

Google とその研究部門である DeepMind は、静かに(そしてその後はかなり目立って)Gemini のロードマップにおけるもう一つの大きな一歩、Gemini 3.1 Pro を押し出しました。コンシューマ向けの各インターフェースおよび CometAPI 全体に展開されたこのリリースは、Gemini 3 ファミリーに対する性能と推論能力のアップグレードとして位置づけられており、長文推論の大幅な強化、マルチモーダル理解の改善、実運用向けのスケーラビリティ向上を約束します。
Google の最新モデル — Gemini 3.1 Pro とは?
Gemini 3.1 Pro は、マルチステップ、マルチモーダル、エージェント型タスクに最適化された「最も高機能」な推論モデルとして位置づけられた、Gemini 3 ファミリー初のインクリメンタルなアップデートです。2026年2月中旬にパブリックプレビューでリリース(プレビューは 2026年2月19〜20日に発表)され、持続的な思考連鎖、ツール使用、長コンテキスト理解を要するシナリオ、例えば大規模なリサーチ統合、ツールやシステムを調整するエンジニアリングエージェント、テキスト・画像・音声・動画が混在する文書のマルチモーダル分析を明確にターゲットにしています。
大局的には、Gemini 3.1 Pro は開発者によって次のように説明されています。
- ネイティブにマルチモーダル — テキスト、画像、音声、動画を受け取り、統合的に推論できる。
- 長いコンテキストに対応 — コードベース全体、複数文書のファイル群、長尺の書き起こしにも適した非常に大きなコンテキストウィンドウをサポート。
- 信頼性の高い推論とエージェント型ワークフローに最適化 — マルチステップタスクにおいて計画し、ツールを呼び出し、出力を検証するように調整されている。
今これが重要な理由:組織や開発者は「会話が上手いアシスタント」から「高リスクの意思決定支援やリサーチエージェント」(法務文書の作成、R&D の統合、マルチモーダル文書理解)へと移行しています。Gemini 3.1 Pro はまさにその領域向けに設計されており、幻覚の削減、追跡可能な推論の生成、プロトタイピングと本番の双方に向けた CometAPI との統合を目指しています。
Gemini 3.1 Pro の技術的ハイライトと機能は?
ネイティブなマルチモーダル性と極大コンテキストウィンドウ
Gemini 3.1 Pro は、マルチモーダル性に焦点を当てた Gemini 系譜を継承しています。モデルカードや製品ノートによると、このモデルはテキスト、画像、音声、動画を同一のパイプラインで受け取り推論することができ、データタイプが混在するワークフロー(例:音声+書き起こし+スキャンが含まれる法的な供述)を簡素化します。特筆すべきは、1,000,000トークンのコンテキストウィンドウをサポートし、長文の出力も生成できる点です(公開ノートでは長文タスクに適した非常に大きな出力上限が示されています)。この規模により、コードリポジトリ全体の解析、複数章にわたる文書、長尺の書き起こしをチャンク分割なしで扱うユースケースに適します。
「動的思考」:推論精度と段階的プランニングの改善
Google は 3.1 Pro の「思考」の改善、すなわちタスクの複雑さに応じた内部的な思考連鎖の扱いと推論戦略の動的選択が向上したと述べています。必要に応じて明示的なマルチステップ計画を起動し、その際のトークン効率も高くなるよう調整されています。実務上は、複雑な段階的課題における幻覚が減り、マルチステップ推論ベンチマークでの事実整合性が改善することに繋がります。
エージェント型ワークフローとツール利用
3.1 Pro の主要な設計焦点の一つはエージェント性能です。ツールの調整、ウェブグラウンディングや検索の呼び出し、コードスニペットの作成と実行、二次パスによる出力検証を行います。Google は 3.1 Pro をエージェントファーストな製品(例:Antigravity 開発環境)に統合し、モデルがエディタ、ターミナル、ブラウザを伴うタスクを実行し、進捗検証のためにスクリーンショットやブラウザ記録のようなアーティファクトを保存できるようにしています。これらの機能は、「助言だけを行う」モデルと、実際にマルチツールのワークフローを信頼性高く実行するモデルのギャップを縮めることを狙っています。
専用サブモード(Deep Research、Deep Think)
Google は 3.1 Pro を「Deep Research」と組み合わせ、将来の「Deep Think」バリアントにも言及しています。これらのサブモードは、それぞれ高再現率のリサーチタスクと最大限の推論深度(追加の計算コストとレイテンシを伴う)をターゲットにしています。高速・低コストよりも、より熟慮された高品質の出力を必要とするアナリスト、研究者、開発者に向けられています。
ベンチマークにおける Gemini 3.1 Pro の性能は?
Gemini 3.1 Pro は、先行する Gemini 3 Pro の結果に対して大幅な向上を達成し、マルチステップ推論やマルチモーダルの幅広い指標で首位を取ることが多い一方で、特定の専門タスク(特に高度なコーディングやエキスパート向け QA セット)では一部の競合に遅れを取ることがあります。要するに、専門ベンチマークでは狭い領域で競合に優位性が見られる一方、全体としては幅広い改善が見られます。
主要なベンチマーク主張とハイライト数値
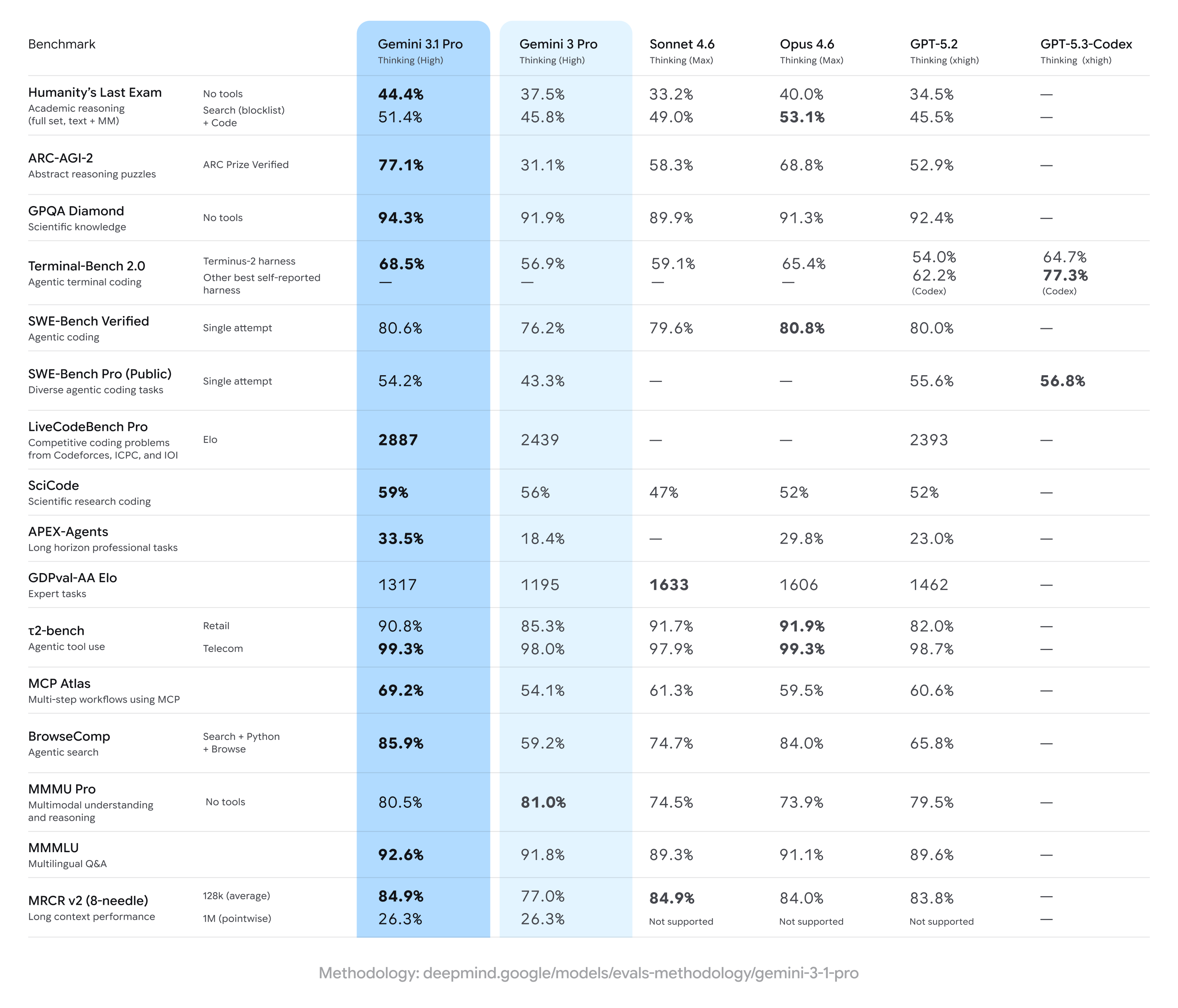
- ARC-AGI-2(抽象推論/多段階の科学パズル): Gemini 3.1 Pro の報告値は、以前の Gemini 3 Pro バージョンからの大幅な改善を示しています。あるコミュニティのテストスイートでは、短時間の集中的なテストにおいて、従来の Gemini 3 Pro ベースラインに対して ARC-AGI-2 で 2 倍超の改善が示されました。具体的な報告スコア(コミュニティテスト)では、Gemini 3.1 Pro は一部の ARC 風アグリゲーションで ~77.1% に達したとされています(公開報告)。
- GPQA Diamond と大学院レベルの科学系ベンチマーク: データ報告によれば、Gemini 3.1 Pro は GPQA Diamond(大学院レベルの科学 QA ベンチマーク)で記録的な高スコアを達成し、以前の Gemini モデルを上回り、独立実行でファミリーの新たなハイウォーターマークを樹立しました。これらの伸びは、連鎖思考および段階的推論の調整改善を反映しています。
- 「Humanity’s Last Exam」ツール有効(マルチツール、グラウンディング推論): Anthropic の Claude Opus 4.6 との直接比較では、この複雑なツール有効ベンチマークで Claude が 53.1%、Gemini 3.1 Pro は同一ラウンドで 51.4% を記録 — この試験では Gemini は僅差で届かずという結果でした。
- コーディング&ターミナル系ベンチマーク(Terminal-Bench 2.0、SWE-Bench Pro): 専門的なコーディング系では差異が大きくなりました。特定のハーネスを用いた Terminal-Bench 2.0 では、GPT-5.3-Codex 系が 77.3% 前後、Gemini 3.1 Pro は同条件で ~68.5%。SWE-Bench Pro の公開結果では、Gemini 3.1 Pro が ~54.2%、GPT-5.3-Codex が 56.8% とより接戦でしたが、これらの実行では OpenAI の Codex 系が専門的プログラミングタスクで僅かに優位でした。
- GDPval-AA Elo(エキスパートタスク評価): エロースタイルの統合ランキングでは、Claude Sonnet/Opus 系がより高得点(例:~1606–1633 ポイント)で、同一データセットにおいて Gemini 3.1 Pro は ~1317 ポイントという公的報告もあり、特定の狭い専門領域には改善余地が示されています。
実地トライアル結果とハンズオン評価
アナリストのハンズオンでは、Gemini 3.1 Pro が特に優れる分野として次が挙げられます。
- 長コンテキストの要約および複数文書の統合。1M トークンのウィンドウにより、チャンク分割に起因するアーティファクトを回避。
- マルチモーダル理解タスク。画像+テキストのグラウンディングにより、事実抽出が向上。
- エージェント的自動化(例:簡易ツールチェーンの調整)。Antigravity での試行では、アーティファクトによる各ステップの記録を伴うマルチエージェントのオーケストレーションが実現可能であることが示されました。
Gemini 3.1 Pro がなお遅れを取る領域(数値が示すもの)
どのモデルも万能ではありません。独立のコメントやコミュニティテストは、次のギャップを指摘しています。
- ソフトウェアエンジニアリングとコード保守系ベンチマーク(SWE-Bench Pro など) — 大規模リファクタリング、雑多なコードベースでのバグトリアージ、特定の自動プログラム修復など、実務的なソフトウェアエンジニアリング能力を試す課題で、Gemini 3.1 Pro は競合(Anthropic の Claude Opus 4.6)に遅れる場面がある。言い換えれば、日常的な保守エンジニアリングでは、専門特化モデルが特定のテストベッドで依然優位な場合がある。
- レイテンシ重視のマイクロタスク — 3.1 Pro は深さ重視に調整されているため、超低遅延・高スループットを要求するタスク(軽量会話 UI のマイクロ推論など)は、Gemini ファミリー内の「Flash」やその他最適化バリアントの方が適している可能性がある。
Gemini 3.1 Pro の料金は?
Gemini 3.1 Pro へのアクセス方法は 2 通りあります — コンシューマ向けサブスクリプションと開発者向け API — で、料金体系はそれぞれ異なります。
- コンシューマ(Gemini アプリ/Google AI Pro): Gemini 3.1 Pro へのアクセスは Google AI Pro サブスクリプションに含まれており、米国では $19.99 / 月 です(Google は下位の「AI Plus」と上位の「AI Ultra」も提供)。Google。
- 開発者/API(トークン課金): Gemini/AI 開発者向け API 経由で Gemini モデルを呼び出す場合、料金はトークン単位で従量制です。Gemini 3.x Pro プレビューの公開開発者価格は概ね、標準帯(≤200k プロンプト)で 入力 1M トークンあたり $2.00、出力 1M トークンあたり $12.00。より大きなコンテキストでは上位ティア(例:入力 $4/出力 $18/1M)があります(詳細とバッチ価格は Gemini API の価格表を参照)。
- CometAPI 経由で Gemini 3.1 Pro を利用する場合:
| Comet 価格 (USD / M Tokens) | 公式価格 (USD / M Tokens) |
|---|---|
| 入力:$1.6/M; 出力:$9.6/M | 入力:$2/M; 出力:$12/M |
コンシューマサブスクリプションの価格(Gemini アプリ)
Gemini アプリ内のエンドユーザープランでは、Google はモデルバリアントと追加機能へのアクセスでティアを構成しています:Google AI Pro と Google AI Ultra。価格は市場と通貨により異なります。公開例では、Google AI Pro は $19.99/月(プロモーションのトライアルあり) と示され、ティア別の通貨価格は製品ページに表示されています(トライアルや短期割引を含む)。AI Ultra はより高いアクセス(例:新機能への優先アクセス、動画生成のクレジット増)をより高い月額でバンドルします。これらのコンシューマプランは、他のハイエンドなコンシューマ向け AI サブスクリプションと競合する価格設定で、API 統合なしに 3.1 Pro の機能へアクセスしたい個人のパワーユーザーや小規模チームを想定しています。
実践的なプロンプトと使用のコツ(私ならこうする)
これらを使うと、信頼でき再現性の高い結果が得られます。
- 明示的なステッププランナー
プロンプトパターン:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.これは 3.1 Pro のより強力な段階的実行を活用し、チェックポイントを与えます。 - スキーマ付きの構造化出力
JSON とスキーマ、strict: trueを要求します。3.1 Pro はスキーマ遵守の長文出力をより安定して生成するため、下流でパースしやすい大きな単一レスポンスが得られます。 - ツールチェック・サンドイッチ
外部ツール(API、コードランナー)を呼ぶときは、計画 → 正確なツール呼び出し(コピペ可能) → 検証手順、の順にモデルに出力させます。続行前に、モデルの外側で検証手順を実施して確認します。 - 単発の「鵜呑み」に注意
モデルが完璧に見えるコードやコマンドを書いても、独立した検証(テスト、リンター、サンドボックス実行)を必ず実施してください。特にエージェント的/自律的アクションでは重要です。
Gemini 3.1 Pro をハンズオン
トライアルケース 1: 長コンテキストの調査アシスタント(NotebookLM/Deep Research)
目標: 10〜50 の長文書(レポート、ホワイトペーパーなど)を引用とアクション項目付きの複数ページのエグゼクティブサマリーへ統合するモデル能力を評価。
セットアップ: 合計 200k〜800k トークンのコーパスを投入し、明示的な引用と「次のステップ」推奨付きで 2〜4 ページのサマリーを生成させる。再現可能なプロンプトテンプレートを使用し、時間、トークン使用量(コスト)、事実精度を測定。
結果: 旧モデルに比べてエンドツーエンドの要約が高速化し、チャンク分割に伴うアーティファクトが減少。サマリーの引用忠実度が向上し、大規模でも首尾一貫性が改善 — その代償としてトークン使用量は多くなる(予算計画が必要)。ベンチマークとハンズオンは、1M トークンウィンドウにより、複数文書の統合で 3.1 Pro が優れていることを示します。
トライアルケース 2: エージェント型コーディングアシスタント(Antigravity + GitHub Copilot)
目標: 複数ステップの開発タスク(例:複数ファイルにまたがる機能実装、テスト実行、失敗テストの修正)の完了までの時間短縮を測定。
セットアップ: プレビューの Antigravity または GitHub Copilot で Gemini 3.1 Pro を選択。再現可能なタスク(課題作成 → 実装 → テスト実行)を定義し、ステップとエージェントのアーティファクトを記録し、人間のみのベースラインと比較。
結果: 複数ステップのタスクのオーケストレーションが改善(アーティファクト記録、パッチ候補の自動提案)。以前の Gemini 3 Pro よりも複数ファイルに跨る推論が向上し、定型的な機能実装で時間短縮が測定可能。専門的で低レベルのシステムデバッグでは、特化したコードファーストモデルが依然有利な場合あり(コミュニティ結果では特定のターミナル系ベンチマークで一部 GPT-Codex 系にギャップ)。
トライアルケース 3: マルチモーダルな法務/医療文書レビュー
目標: スキャン PDF、画像、音声書き起こしが混在するコーパスを取り込み、主要事実を抽出し、リスクマトリクスと優先アクションを生成する。
セットアップ: スキャン画像と OCR テキスト、補助音声を含むデータセットを供給。固有表現抽出の適合率、偽陽性率、主張を裏付けるソースアーティファクトの参照能力を測定。
結果: 複数モダリティに跨る統合推論が強化され、裏付け可能な出力が改善(主張を支える画像/ページ/音声タイムスタンプを指し示す能力)。長いコンテキストウィンドウにより手動のチャンク分割や相互参照の必要が減少。ただし規制領域では、ドメイン専門家による検証とグラウンディング/検証パイプラインの併用が必要。
第一印象(何が違うと感じるか)
- より深い段階的推論。 以前は複数回のやり取りが必要だったタスク(複数文書の統合、段階的な数学・論理)でも、パス数が減り、内部指示テキストを露出せずに、より明確なチェーン・オブ・ソート風の出力が得られる傾向。Google が強調した目玉です。
- より長く高品質な構造化出力。 JSON や長文オートメーションがより一貫しており、しばしばさらに長大(3.0 よりも大きい出力サイズを報告するユーザーも)。単一の大きなペイロードを生成したい用途に適します。より大きな出力とストリーミングの取り扱いを想定すべきです。
- トークン/コンテキスト処理の効率化。 トークン効率の改善と、ツール使用シナリオにおける「よりグラウンディングされ事実整合的な」振る舞い。短い事実検索での幻覚減少として現れます。
最終分析:今、Gemini 3.1 Pro は採用に値するか?
Gemini 3.1 Pro は、推論、コーディング、エージェント系ベンチマークで実証的な改善を示した、Gemini ファミリーの意味ある前進です。Google の公開モデルカードや、特定のリーダーボードで大幅なジャンプを示す独立トラッカーに裏打ちされています。高度な推論、エージェント的なツール協調、長コンテキストのマルチモーダル能力を必要とするチームにとって、3.1 Pro は有力な候補となります。
開発者は CometAPI 経由で今すぐ Gemini 3.1 Pro にアクセスできます。開始するには、Playground でモデルの能力を試し、詳細な手順は API guide を参照してください。アクセス前に、CometAPI にログインし API キーを取得していることを確認してください。CometAPI は統合支援のため、公式価格よりもはるかに低い価格を提供しています。
Ready to Go?→ 今すぐ Gemini 3.1 Pro にサインアップ