

2026年3月3日、Google は Gemini 3 ファミリーの最新メンバーである「Gemini 3.1 Flash-Lite」を発表しました。これは、開発者およびエンタープライズ向けワークロードのために設計された、高スループット・低レイテンシ・高コスト効率のエンジンです。Google は Flash-Lite を Gemini 3 ラインにおける「最速かつ最もコスト効率の高い」モデルとして位置づけており、ストリーミング型インタラクション、大規模バックグラウンド処理、高頻度の本番タスク(例:翻訳、抽出、UI 生成、大量分類)を、Pro 系列よりもはるかに低い価格帯で提供する軽量バリアントとしています。
以下では、Flash-Lite の実像を解説します。
Gemini 3.1 Flash-Lite とは
Gemini 3.1 Flash-Lite は、速度とコスト効率を重視するために、最高水準の推論深度の一部を意図的にトレードオフした、Google の Gemini 3 ファミリーの一員です。Gemini 系譜としてネイティブにマルチモーダル(テキスト、画像、その他のモダリティを入力として受け付け可能)でありつつ、トークン/秒あたりのスループット最大化と、迅速かつ繰り返し推論が求められるワークロード向けのトークン単価大幅低減に特化してチューニング・デプロイされています。モデルは 3.1 Pro アーキテクチャに由来しつつ、スループット、レイテンシ、コストに最適化されたものと説明されています。
主要な設計上のトレードオフ
「Lite」という名称が示すとおり、本モデルはエンジニアリングの重点を以下に置いています。
- ヘビーな推論よりスループットを優先: Flash-Lite はトークンあたりの計算量を意図的に抑制し、Time-to-First-Token(TTFT)と連続出力速度を高速化します。これにより、安全性フィルター、リアルタイムアシスタント、大量生成など、各リクエストを迅速かつ大規模に処理すべきパイプラインに最適です。
- 大規模用途でのコスト効率: トークンあたりの計算量を減らすことで、100万トークンあたりの価格を低く提供でき、月間で数百万〜数十億トークン規模のアプリケーションにおける限界費用を削減します。Google のプレビュー価格では、Pro ティアとの間に有意な差が示されています。
- 実務タスクに合わせた品質調整: 初期のスコアリング要約によれば、Flash-Lite は標準的な分類、多言語、多くのマルチモーダルタスクで強力な結果を維持しますが、推論の深さが重要となる最も複雑な多段推論やコード生成ベンチマークでは Pro を上回る位置づけではありません。
これらのワークロードは、信頼性の高い出力と高スループットを必要としますが、フラッグシップモデルが持つ複雑な多段推論能力を常に必要とするわけではありません。
Gemini 3.1 Flash-Lite の主な機能
1. 低レイテンシと高速な初回トークン時間
Google は Flash-Lite の主要指標として最初の回答トークンまでの時間を強調しています。同社は、Gemini 2.5 Flash と比較して 約2.5倍の Time-to-First-Token(TTFT)短縮、さらに最大45%の出力生成高速化を報告しています。これらの改善は、エンドユーザーの体感応答性とバックエンドシステムにおけるスループットコストに直接影響します。これにより、アプリ内に組み込まれたチャットボットなどのインタラクティブ機能や、マイクロ秒単位の差が効く高 QPS パイプラインに適しています。
この改善は、以下のようなリアルタイムアプリケーションを大幅に強化します。
- 会話型 AI
- AI 搭載の検索アシスタント
- インタラクティブなチャットボット
- ライブ翻訳サービス
低レイテンシは待ち時間を減らし、より滑らかなインタラクションを可能にすることで、ユーザー体験を向上させます。
2. コスト効率の高いトークン課金
AI 推論コストはしばしばトークン単位で算定されるため、価格は大規模展開における重要要素です。
Gemini 3.1 Flash-Lite は、非常に競争力のある価格体系を導入しています。
| トークン種別 | 価格 |
|---|---|
| 入力トークン | $0.25 / 1M トークン |
| 出力トークン | $1.50 / 1M トークン |
これは従来の Flash モデルと比べて削減されており、大規模ワークロードを運用する組織にとって魅力的な選択肢となります。
比較:
| モデル | 入力価格 | 出力価格 |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
この価格戦略により、開発者は運用コストを劇的に増やすことなく大規模に AI を実行できます。
さらにお得な価格をお探しなら、Gemini Flash-Lite は CometAPI 上で 20% 割引を提供しています。
3. 「思考レベル」(推論深度の制御)
Gemini 3.1 Flash-Lite は、開発者が設定可能な**「思考レベル」**機能を備えています。これは、単純なタスクに対してはより速く浅い処理を、難易度の高いタスクにはより深い推論を選好するようモデルに指示するノブです。モデルを切り替えることなく、リクエストごとに動的にコスト/レイテンシのトレードオフを調整できる点が実運用で重要です。
開発者は、タスクの複雑さに合わせてモデルの推論深度を設定できます。思考レベルは、Minimal、Low、Medium、High の4段階をサポートします。
この動的アプローチにより、リソース使用を最適化しつつ、重要な場面では品質を維持できます。実務上の方針は大まかに次のとおりです。
- Minimal/Low: 翻訳、分類、感情分析など、論理的に単純で高同時実行が求められるタスクに適し、速度とコストを最優先。
- Medium: ほとんどの本番タスクに適し、品質と効率のバランスを確保。
- High: UI 生成、シミュレーション作成、複雑な指示の実行など、深い推論が必要なタスクに適合。
4. 軽量フットプリントを備えたマルチモーダル能力
Flash-Lite は速度とコストに最適化されている一方で、Gemini 3 系のマルチモーダル基盤を維持しています。ユースケースに応じて、分類や軽度のマルチモーダル推論のために画像入力を受け付けることができ、経済設計は非常に大きな画像主体ワークフローよりも、短く範囲が限定されたマルチモーダル処理を優先します。他の Gemini モデルと同様に、Gemini 3.1 Flash-Lite はマルチモーダル入力をサポートし、開発者はさまざまな種類のデータを処理できます。
サポートされる入力:
- テキスト
- 画像
- 動画
- 音声
複数種類の情報を分析できるため、次のような新たなユースケースが可能になります。
- 文書処理の自動化
- 視覚データ抽出
- マルチメディア要約
従来の Gemini モデルは、視覚および知識ベンチマーク全般で強力なマルチモーダル推論能力を示してきました。
パフォーマンスベンチマーク — 実数とその意味
Google の発表と製品ドキュメントでは、Flash-Lite の位置づけを理解するための複数のベンチマーク指標が示されています。
開発者向け速度指標
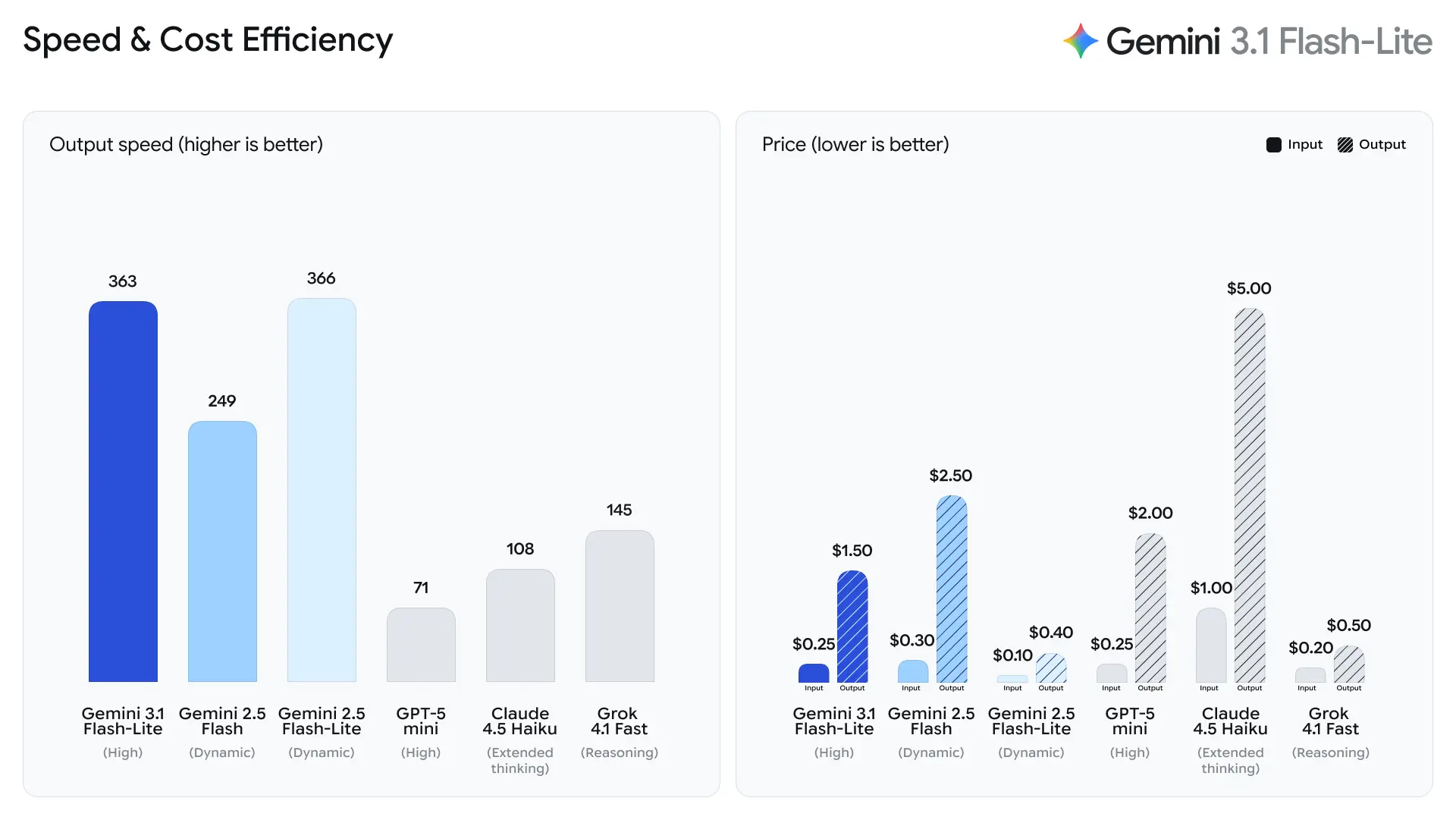
- Time to First Answer Token が 2.5 倍高速化(Gemini 2.5 Flash 比、Google の社内比較による)。
- 出力生成が 45% 高速化(Gemini 2.5 Flash 比)。
これらは人手評価による品質指標ではなく、ランタイムのマイクロアーキテクチャ、バッチ処理、推論スタックの最適化により、短い応答でレイテンシを削減したパフォーマンス工学的な指標です。最初のトークンまでの時間が短いほど、インタラクティブアプリでの体感遅延が減り、サーバーあたりの総スループットが向上し、同一 QPS に対する総計算コストを下げられます。
秒間トークン数(t/s)とスループット
Artificial Analysis のテストデータによると、3.1 Flash-Lite は 1 秒あたり 388.8 トークンの出力速度を達成しました(同価格帯のモデルの中央値は 96.7 トークン/秒)。この速度は同クラスの中でもトップレベルです。
一方で Artificial Analysis は、3.1 Flash-Lite の最初のトークン遅延(TTFT)が 5.18 秒であり、同価格帯の推論モデルとしては比較的高い(中央値は 1.82 秒)点も指摘しています。さらに、評価プロセス中に 5,300 万トークンを生成しており、平均の 2,000 万と比べると多めです。したがって、最初のトークン遅延に非常に敏感、もしくは出力の簡潔性に厳格な要件があるシナリオでは、思考レベルやプロンプトの最適化が必要になる場合があります。
推論力と正確性のベンチマークスコア
Google は、集約的な推論/事実性タスクにおいて、Gemini 3.1 Flash-Lite が同業他社や従来の Gemini 系と比較して強力であることを示すクロスモデル比較を提示しています。
- Arena.ai Elo スコア: Gemini 3.1 Flash-Lite は、対戦型の複合ランキングである Arena 評価リーダーボードで Elo 1432 を達成したと報告されています。
- GPQA Diamond: 86.9%(質問応答の堅牢性を測る指標)。
- MMMU Pro: 76.8%(一部の研究機関が内部/外部で用いるマルチモーダル/マルチタスク指標)。
- LiveCodeBench(コーディング能力):72.0%
- CharXiv Reasoning(グラフ推論):73.2%
- Video-MMMU(動画理解):84.8%
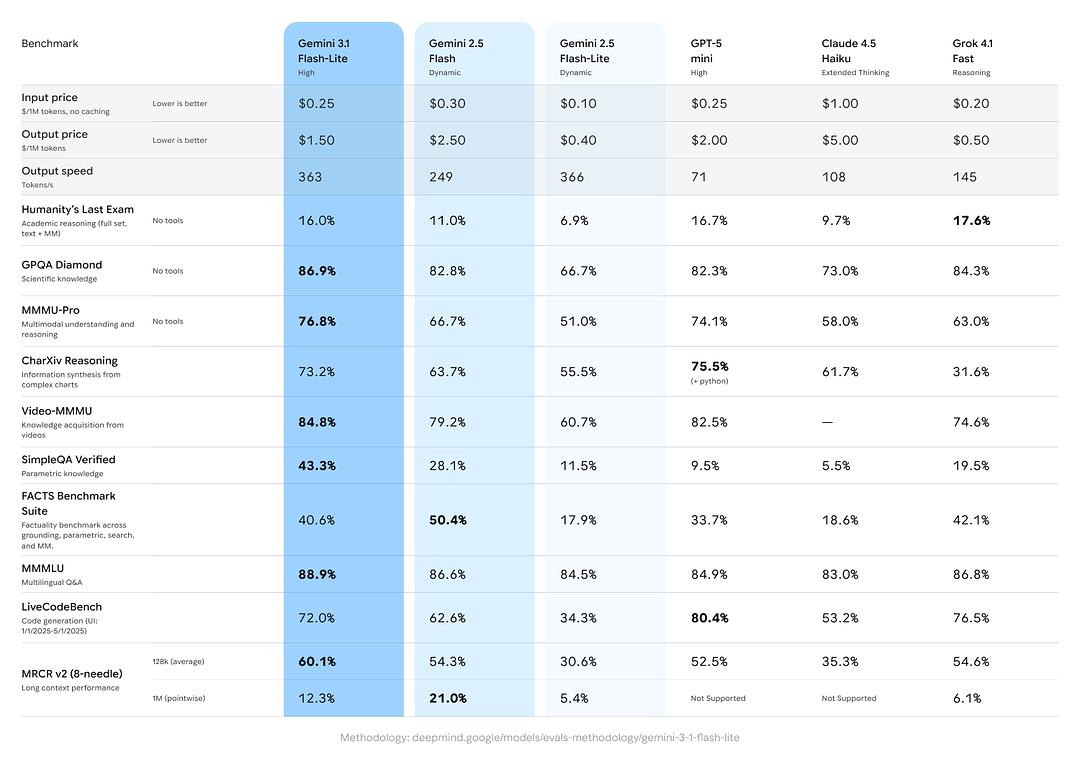
Gemini 3.1 Flash-Lite は、速度とコストを大幅に改善しつつ、いくつかの指標で従来の Gemini 2.5 Flash を上回っています。
Gemini 3.1 Flash-Lite に適したユースケース
Gemini 3.1 Flash-Lite は、高スループットとトークン単価の低さが決定要因となる実務ワークロードに的を絞って設計されています。
高頻度の会話エージェントとストリーミング UI
リアルタイムのチャットボット、ライブの文字起こし+翻訳ストリーム、モデルが生成中の部分回答を表示するコラボレーティブ UI は、Flash-Lite のストリーミング出力と低 TTFT の恩恵を受けます。
大量データ処理(RAG、変換パイプライン)
大規模文書の取り込み:エンティティ抽出、メタデータ付与、分類、翻訳などを数百万件の文書に対して実行—Gemini 3.1 Flash-Lite は、テンプレート化やルール駆動の出力に対して推論コストを抑えつつ、許容可能な精度を提供します。
エッジスタイル/バックグラウンド計算
継続的に流入するテレメトリや非構造データを処理するワークロード(例:コンテンツモデレーションの分類パイプライン、自動レポート生成)は、Gemini 3.1 Flash-Lite により単位コストを最小化できます。
開発者向けツールとバッチコード補完
複数ファイルの雛形生成、大規模なコードリンティング、テンプレート生成などの機能では、Gemini 3.1 Flash-Lite の速度優位性により、最大限の推論深度を必要としない開発者体験ツールでレイテンシとコストを削減できます。
Gemini 他モデルおよび競合との比較
Gemini ファミリー内
- Gemini 3.1 Pro: 複雑な推論や多段計画で最高の能力。トークンあたりのコストと速度は劣るが、深いニュアンスを要するタスクに最適。
- Gemini 3.1 Flash(非 Lite): スループットと能力の中間を狙う。Flash-Lite は計算スタックをさらに下層まで最適化してスループットを追求。
競合する「高速」モデルとの比較
Gemini 3.1 Flash-Lite は、多くのスループットおよび品質指標で複数の高速/ミニ系モデルに匹敵または上回る結果を示しています—ただし、独立系のアナリストは、直接比較は評価方法論やデータセット選定に敏感であると注意喚起しています。最高難度の推論指標では中位程度にとどまる一方で、スループットとコストでは非常に競争力が高いと見込まれます。
結論 — AI スタックにおける Flash-Lite の位置づけ
Gemini 3.1 Flash-Lite は、意図的に設計されたプロダクトです。個々の例あたりの計算量を一部トレードオフすることで、レイテンシとコストを劇的に改善した、Gemini 3 ファミリーの効率・スループット重視の一員です。高ボリュームのパイプライン(翻訳、バッチ処理、ストリーミング UI、適度な複雑性のエージェントタスク)を構築する企業や開発者にとって、Flash-Lite は現実的なベースラインエンジンとなります。絶対的に最高の推論忠実度が必要な場合は、Pro モデルが適切です。
ワークロードが短く反復的な推論に支配される、あるいは大規模で高速なストリーミング出力が必要であれば、Flash-Lite は試す価値があります。深い多段推論が中心であれば、ハイブリッドアプローチを計画しましょう:スループット重視のトラフィックは Flash-Lite に、価値が高く複雑なクエリは Pro モデルにエスカレーションします。
現在、開発者は Gemini 3.1 Flash Lite を CometAPI 経由で利用できます。開始するには、Playground でモデルの機能を試し、詳細は API ガイド を参照してください。アクセス前に、CometAPI にログインして API キーを取得していることを確認してください。CometAPI は、公式価格を大きく下回る価格で統合を支援します。
準備はいいですか?→ 今すぐ Gemini 3.1 Flash-Lite に登録 !