

OpenAIは、 gpt-oss-セーフガード開発者が強制できるように設計されたオープンウェイト推論モデルファミリー 彼ら自身 推論時の安全ポリシー。固定された分類器やブラックボックスのモデレーションエンジンを出荷するのではなく、新しいモデルは微調整され、 開発者が提供するポリシーからの理由推論を説明する思考連鎖(CoT)を出力し、構造化された分類出力を生成します。研究プレビューとして発表されたgpt-oss-safeguardは、2つの推論モデルとして提示されます。gpt-oss-セーフガード-120b および gpt-oss-セーフガード-20bgpt-oss ファミリーから微調整され、推論中に安全性分類とポリシー適用タスクを実行するように明示的に設計されています。
gpt-oss-safeguard とは何ですか?
gpt-oss-safeguardは、gpt-ossファミリーから後学習されたオープンウェイトのテキストのみの推論モデルのペアです。 自然言語で書かれたポリシーを解釈し、そのポリシーに従ってテキストにラベルを付ける特徴的なのは、この政策が 推論時に提供される (ポリシーを入力として)静的な分類器の重み付けに組み込まれるものではありません。これらのモデルは、主に安全性分類タスク(複数ポリシーのモデレーション、複数の規制体制にまたがるコンテンツ分類、ポリシーコンプライアンスチェックなど)向けに設計されています。
なぜこれが重要
従来のモデレーションシステムは通常、(a) ラベル付きサンプルでトレーニングされた分類器にマッピングされた固定ルールセット、または (b) キーワード検出のためのヒューリスティック/正規表現に依存しています。gpt-oss-safeguard は、このパラダイムを変えようとしています。ポリシー変更のたびに分類器を再トレーニングするのではなく、ポリシーテキスト(たとえば、会社の利用規約、プラットフォームの利用規約、規制当局のガイドラインなど)を提供すると、モデルが特定のコンテンツがそのポリシーに違反しているかどうかを推論します。これにより、俊敏性(再トレーニングなしでポリシーを変更)と解釈可能性(モデルが推論の連鎖を出力)が実現されます。
これがその中心となる哲学です。「暗記を推論に、推測を説明に置き換える」
これはコンテンツ セキュリティにおける新しい段階であり、「受動的にルールを学習する」段階から「能動的にルールを理解する」段階へと移行しています。
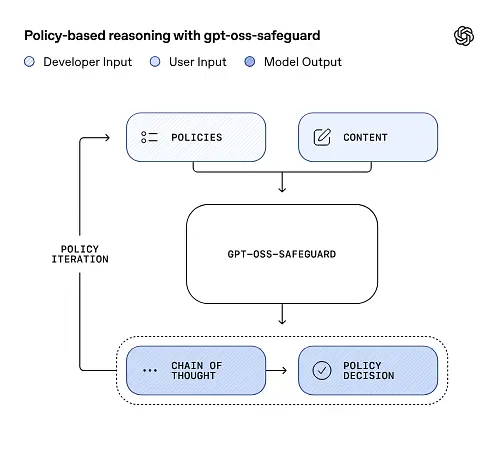
gpt-oss-safeguard は、開発者が定義したセキュリティ ポリシーを直接読み取り、それらのポリシーに従って推論中に判断を下すことができます。
gpt-oss-safeguard はどのように機能しますか?
入力としてのポリシー推論
推論時に、次の2つのものを提供します。 ポリシーテキスト と 候補コンテンツ ラベル付けされます。モデルはポリシーを主要な指示として扱い、段階的な推論を実行して、コンテンツが許可されるか、許可されないか、あるいは追加のモデレーション手順が必要かを判断します。推論において、モデルは以下のことを行います。
- 結論 (ラベル、カテゴリ、信頼度) と、その結論に至った理由を説明する人間が読める推論トレースを含む構造化された出力を生成します。
- 分類するポリシーとコンテンツを取り込み、
- 思考の連鎖のようなステップを使用してポリシーの条項を内部的に推論し、
具体的な例を挙げますと、以下の通りです。
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
次のように応答します:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
思考の連鎖(CoT)と構造化された出力
gpt-oss-safeguardは、各推論の一部として完全なCoTトレースを出力できます。CoTは検査可能なように設計されており、コンプライアンスチームはモデルが結論に至った理由を読み取ることができ、エンジニアはトレースを使用してポリシーの曖昧さやモデルの障害モードを診断できます。モデルはまた、 構造化された出力たとえば、判定、違反したポリシーのセクション、重大度スコア、推奨される修復アクションを含む JSON など、モデレーション パイプラインに簡単に統合できます。
調整可能な「推論努力」レベル
レイテンシ、コスト、徹底性のバランスをとるために、モデルは構成可能な推論作業をサポートします。 低 / 中 / 高労力を多くすると思考の連鎖の深さが増し、一般的にはより堅牢な推論が得られますが、推論速度とコストは増加します。これにより、開発者はワークロードをトリアージし、日常的なコンテンツには労力を少なく、エッジケースや高リスクのコンテンツには労力を多く割り当てることができます。
モデルの構造と、存在するバージョンは何ですか?
模範的な家族と家系
gpt-oss-safeguardは 訓練後 OpenAIの以前の gpt-oss オープンモデル。セーフガードファミリーには現在2つのサイズがリリースされています。
- gpt-oss-セーフガード-120b — 高精度の推論タスクを目的とした 120 億のパラメータ モデルであり、最適化されたランタイムで単一の 80 GB GPU 上で実行されます。
- gpt-oss-セーフガード-20b — 低コストの推論やエッジまたはオンプレミス環境向けに最適化された 20 億パラメータのモデル (一部の構成では 16 GB VRAM デバイスで実行可能)。
アーキテクチャに関する注意事項とランタイム特性(期待されるもの)
- トークンごとのアクティブパラメータ: 基礎となる gpt-oss アーキテクチャでは、トークンごとにアクティブ化されるパラメータの数を減らす手法が使用されています (親 gpt-oss の密な注意と疎な注意の組み合わせ / 専門家の混合スタイルの設計)。
- 実際には、120B クラスは単一の大型アクセラレータに適合し、20B クラスは最適化されたランタイムで 16GB VRAM セットアップで動作するように設計されています。
セーフガードモデルは 追加の生物学的データやサイバーセキュリティデータで訓練されていないgpt-ossリリースで実施された最悪の悪用シナリオの分析は、セーフガードバリアントにも概ね当てはまります。これらのモデルは、エンドユーザー向けのコンテンツ生成ではなく、分類を目的としています。
gpt-oss-safeguardの目標は何ですか?
目標
- 政策の柔軟性: 開発者が自然言語で任意のポリシーを定義し、カスタム ラベルの収集なしでモデルにそれを適用できるようにします。
- 説明可能性: 理由を公開することで、決定を監査し、ポリシーを反復できるようになります。
- アクセシビリティ: オープンウェイトの代替手段を提供することで、組織はローカルで安全性の推論を実行し、モデルの内部を検査できるようになります。
従来の分類器との比較
プロ vs. 従来の分類器
- ポリシー変更による再トレーニングは不要です。 モデレーション ポリシーが変更された場合は、ラベルを収集して分類器を再トレーニングするのではなく、ポリシー ドキュメントを更新します。
- より豊かな推論: CoT 出力は、微妙なポリシーの相互作用を明らかにし、人間のレビュー担当者に役立つ物語的な正当性を提供することができます。
- カスタマイズ性: 推論中に、単一のモデルで同時に多くの異なるポリシーを適用できます。
欠点 vs. 従来の分類器
- 一部のタスクのパフォーマンス上限: OpenAIの評価では、 数万のラベル付きサンプルで訓練された高品質の分類器は、GPT-OSS-Safeguardよりも優れた性能を発揮できる。 特殊な分類タスクに。目的が生の分類精度であり、ラベル付きデータがある場合、その分布でトレーニングされた専用の分類器の方が適している場合があります。
- レイテンシとコスト: CoT による推論は計算集約型であり、軽量分類器よりも低速です。そのため、純粋に安全策ベースのパイプラインは大規模になるとコストが高くなる可能性があります。
要約: gpt-oss-safeguardは次のような場合に最適です。 政策の機敏性と監査可能性 優先事項である場合や、ラベル付けされたデータが不足している場合に使用します。また、スケール最適化された分類器の代替として必ずしも使用できるわけではなく、ハイブリッド パイプラインの補完的なコンポーネントとして使用します。
gpt-oss-safeguard は OpenAI の評価でどのように機能しましたか?
OpenAIは、内部評価と外部評価をまとめた10ページの技術レポートでベースライン結果を公開しました。主なポイント(選択された負荷耐性指標):
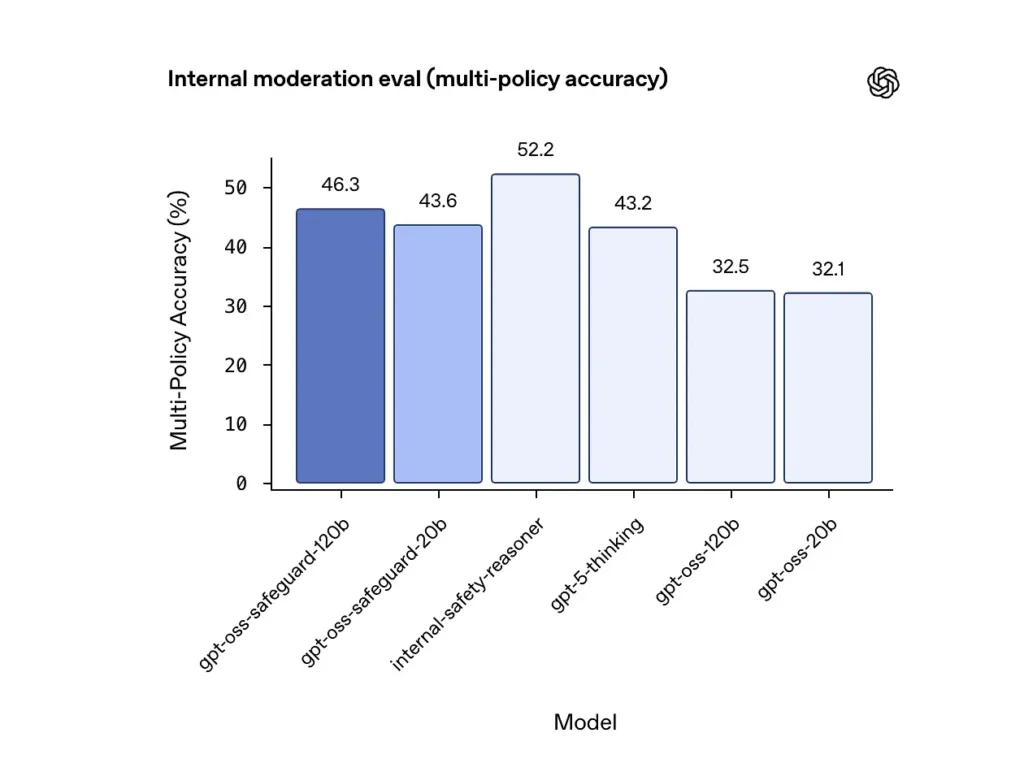
マルチポリシー精度(内部評価)
OpenAIはモデルに複数のポリシーを与えて、その精度を評価した。 の試合に 同時にポリシーを実行し、予測がゴールデンラベルと一致した場合のみ正しいとカウントします を ポリシー。結果:
- gpt-oss-セーフガード-120b: 46.3% マルチポリシー精度
- gpt-oss-セーフガード-20b: 43.6%
- 比較のために: gpt-5-思考: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%
OpenAIの内部「安全推論器」アンサンブルは、同じテストで52.2%のスコアを獲得しました。これらの数値は、セーフガードモデルがマルチポリシータスクにおいてGPT-OSSベースモデルを大幅に上回っていることを示しています。さらに、内部マルチポリシーメトリックでは、より優れたGPT-5-thinkingベースラインを上回りました。
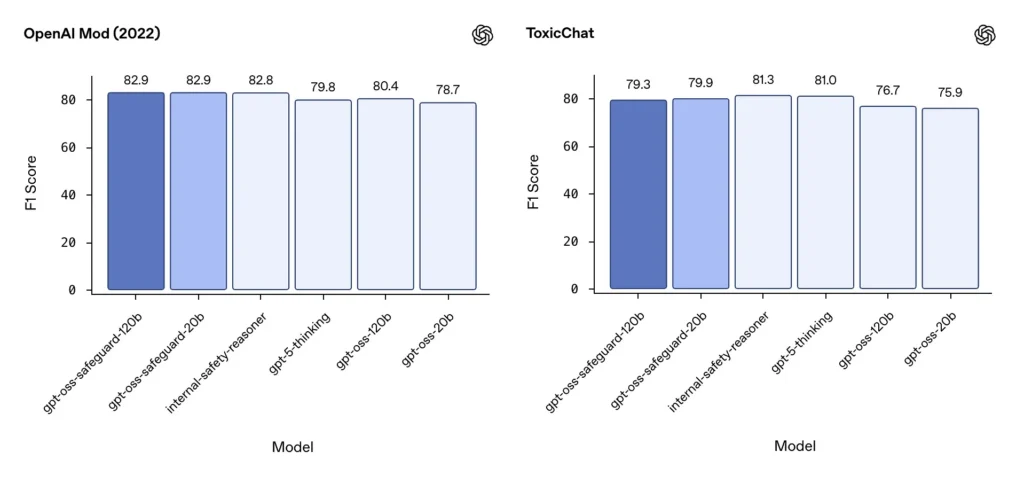
モデレーションF1(外部ベンチマーク)
OpenAIの2022年のモデレーションデータセットと公開されているToxicChatベンチマークでは、gpt-oss-safeguardモデルは堅実なF1スコアを達成しました。
- OpenAI Mod (2022) F1: gpt-oss-セーフガード-120b = 82.9%、gpt-oss-safeguard-20b = 82.9%
- 毒性チャット F1: gpt-oss-セーフガード-120b = 79.3%、gpt-oss-safeguard-20b = 79.9%
これらのスコアにより、gpt-oss-safeguard は、いくつかのベンチマークで特殊な OpenAI 内部システムに近いかわずかに遅れており、一般に、微調整されていない gpt-oss の同等のシステムよりも優れています。
観察された限界
OpenAI は 2 つの実際的な制限を指摘しています。
- 大規模でタスク固有のラベル付きデータセットで訓練された分類器は、依然として安全保護モデルよりも優れている可能性がある。 分類の精度が唯一の目的である場合。
- コンピューティングとレイテンシーのコスト: CoT 推論により推論時間とコンピューティング消費量が増加し、トリアージ分類器および非同期パイプラインと組み合わせない限り、プラットフォーム レベルのトラフィックへのスケーリングが複雑になります。
多言語対応
gpt-oss-safeguard は、MMMLU スタイルのテストにおいて、多くの言語の基礎となる gpt-oss モデルと同等のパフォーマンスを発揮し、微調整された safeguard バリアントが幅広い推論能力を保持していることを示しています。
チームはどのようにして gpt-oss-safeguard にアクセスして展開できますか?
OpenAIはApache 2.0で重みを提供し、モデルをダウンロードするためのリンクを提供しています(Hugging Face)。gpt-oss-safeguardはオープンな重みモデルであるため、ローカルで自己管理型のデプロイメントが可能です(プライバシーとカスタマイズのために推奨)。
- モデルの重みをダウンロード (OpenAI / Hugging Faceより)をダウンロードし、独自のサーバーまたはクラウドVMでホストできます。Apache 2.0では改変および商用利用が可能です。
- ランタイム大規模なTransformerモデルをサポートする標準的な推論ランタイム(ONNX Runtime、Triton、または最適化されたベンダーランタイム)を使用してください。OllamaやLM Studioなどのコミュニティランタイムは、すでにgpt-ossファミリーのサポートを追加しています。
- Hardware120Bでは通常、大容量メモリを搭載したGPU(例:80GB A100 / H100、またはマルチGPUシャーディング)が必要ですが、20Bではより低コストで実行でき、16GB VRAM構成に最適化されたオプションが用意されています。ピーク時のスループットとマルチポリシー評価コストを考慮して容量を計画してください。
マネージドおよびサードパーティのランタイム
独自のハードウェアを実行するのが現実的でない場合は、 コメットAPI gpt-ossモデルのサポートが急速に追加されています。これらのプラットフォームはスケーリングを容易にする一方で、サードパーティのデータ漏洩というトレードオフを再び招きます。マネージドランタイムを選択する前に、プライバシー、SLA、アクセス制御を評価してください。
gpt-oss-safeguard を使用した効果的なモデレーション戦略
1) ハイブリッドパイプラインを使用する(トリアージ → 推論 → 判断)
- トリアージ層: 小型で高速な分類器(またはルール)が些細なケースを除外します。これにより、高価なセーフガードモデルの負荷が軽減されます。
- セーフガード層: ポリシーのニュアンスが重要な、あいまい、高リスク、または複数ポリシーのチェックには、gpt-oss-safeguard を実行します。
- 人間による判定: エッジケースと異議申し立てをエスカレーションし、CoTを透明性の証拠として保存します。このハイブリッド設計は、スループットと精度のバランスを実現します。
2) ポリシーエンジニアリング(プロンプトエンジニアリングではない)
- ポリシーをソフトウェア成果物として扱います。つまり、ポリシーをバージョン管理し、データセットに対してテストし、明示的かつ階層的に維持します。
- ポリシーには、例と反例を添えて記述してください。可能であれば、曖昧さを解消する指示を含めてください(例:「ユーザーの意図が明らかに探索的かつ履歴的な場合はXとラベル付けし、操作的かつリアルタイムな場合はYとラベル付けする」)。
3) 推論の努力を動的に設定する
- 労力が少ない 大量処理および 高い努力 フラグが付けられたコンテンツ、異議申し立て、または影響の大きい業種(法律、医療、金融)向け。
- 人間によるレビューのフィードバックを使用してしきい値を調整し、コストと品質の最適なバランスを見つけます。
4) CoTを検証し、幻覚的な推論に注意する
CoTは有用ですが、幻覚を引き起こす可能性があります。トレースはモデルによって生成された根拠であり、真実ではありません。CoTの出力を定期的に監査し、幻覚的な引用や不一致な推論を検出する検出器を装備してください。OpenAIは、幻覚的な思考連鎖を観察済みの課題として記録し、緩和戦略を提案しています。
5) システム運用からデータセットを構築する
モデルの決定と人間による修正を記録し、ラベル付きデータセットを作成します。これにより、トリアージ分類器の改善やポリシーの書き換えに役立ちます。時間の経過とともに、小規模で高品質なラベル付きデータセットと効率的な分類器を組み合わせることで、日常的なコンテンツにおける完全なCoT推論への依存度が軽減されることがよくあります。
6) コンピューティングとコストを監視し、非同期フローを採用する
消費者向けの低レイテンシアプリケーションでは、高負荷のCoTを同期的に実行するのではなく、短期的な保守的なUX(例:レビュー待ちのコンテンツを一時的に非表示にする)を備えた非同期の安全性チェックを検討してください。OpenAIによると、Safety Reasonerは、本番サービスのレイテンシを管理するために内部的に非同期フローを使用しています。
7) プライバシーと展開場所を考慮する
重みはオープンなので、推論を完全にオンプレミスで実行して、厳格なデータ ガバナンスに準拠したり、サードパーティ API への露出を減らしたりすることができます。これは、規制の厳しい業界にとって価値があります。
まとめ:
gpt-oss-safeguardは、実用的で透明性が高く、柔軟なツールです。 ポリシー主導の安全性推論必要な時に光ります 明示的なポリシーに結びついた監査可能な決定ポリシーが頻繁に変更される場合や、オンプレミスで安全性チェックを維持したい場合などに最適です。 特化型の大容量分類器を自動的に置き換える特効薬。OpenAI独自の評価では、大規模なラベル付きコーパスで訓練された専用分類器は、限定的なタスクにおいて、これらのモデルよりも生の精度で優れていることが示されています。gpt-oss-safeguardを戦略的コンポーネントとして扱うべきです。つまり、階層化された安全アーキテクチャ(高速トリアージ → 説明可能な推論 → 人間による監視)の中核を成す説明可能な推論エンジンです。
スタートガイド
CometAPIは、OpenAIのGPTシリーズ、GoogleのGemini、AnthropicのClaude、Midjourney、Sunoなど、主要プロバイダーの500以上のAIモデルを、開発者にとって使いやすい単一のインターフェースに統合する統合APIプラットフォームです。一貫した認証、リクエストフォーマット、レスポンス処理を提供することで、CometAPIはAI機能をアプリケーションに統合することを劇的に簡素化します。チャットボット、画像ジェネレーター、音楽作曲ツール、データドリブン分析パイプラインなど、どのようなアプリケーションを構築する場合でも、CometAPIを利用することで、反復処理を高速化し、コストを抑え、ベンダーに依存しない環境を実現できます。同時に、AIエコシステム全体の最新のブレークスルーを活用できます。
最新の統合gpt-oss-safeguardはまもなくCometAPIに登場しますので、お楽しみに!gpt-oss-safeguardモデルのアップロードが完了するまで、開発者はアクセスできます。 GPT-OSS-20B API および GPT-OSS-120B API CometAPIを通じて、 最新モデルバージョン 公式ウェブサイトで常に更新されています。まずは、モデルの機能について調べてみましょう。 プレイグラウンド そして相談する APIガイド 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。 コメットAPI 統合を支援するために、公式価格よりもはるかに低い価格を提供します。
準備はいいですか?→ 今すぐCometAPIに登録しましょう !