

xAIが静かにリリース グロク4.1 (2025年11月17日~18日)— Grok 4の重点的なアップグレードで、 感情知能、創造的表現、幻覚の減少 Grokの以前のリリースの鋭い推論機能はそのままに、2つのモード(思考型/非思考型)で提供されます。11月初旬に静かにリリースされ、LMArenaでトップのリーダーボードにランクインしています。grok.com、Grokアプリ、APIから利用可能です。
Grok 4.1とは何ですか?
Grok 4.1は、Grok 4の増分型で実稼働に特化した後継バージョンです。Grok 4と同じ大規模強化学習基盤上に構築されていますが、スタイル、パーソナリティ、アラインメント、そして実世界における信頼性を重視した、トレーニング後の大規模な最適化によって微調整と再トレーニングが施されています。Grok 4.1は、実用的で「使える」前進として位置付けられています。ブラインドテストでの人間の嗜好テストにおいてより賢くなり、感情知能が向上し、クリエイティブライティングが優れ、そして、以前の高パフォーマンスのLLMを悩ませてきた、自信があるが間違った「幻覚」に陥る傾向が明らかに減少しています。
Grok 4.1 は、次の 4 つの側面で質的な変化を実現します。
- 創造性: 文章、ストーリーテリング、社会的文脈において、より強力な言語スタイルと想像力を発揮します。
- 感情的知性: 口調や感情の変化を認識し、より人間らしい感情的論理で反応し、慰めと理解を与える応答を生成します。
- パーソナリティの一貫性: 長い会話でも一貫した口調とパーソナリティを維持し、以前のモデルのような一貫性のない動作は見られなくなりました。
- 共同作業: 複数ターンの対話やタスクの共同作業において一貫性と目標認識を維持します。
xAI はその特徴を一言でまとめています。「より知覚力があり、より共感力があり、より一貫性のある人間に似ています。」
Grok 4.1 は内部ではどのように動作するのでしょうか?
Grok 4.1は、Grok 4ファミリーで使用されているのと同じ事前学習済みのバックボーンに、以下の点に重点を置いた階層化された学習後のパイプラインを加えたものと理解するのが最も適切です。 報酬モデリング、スタイルの調整、エージェント評価.
トレーニングと調整の段階とは何ですか?
Grok 4.1 は、現代の最先端の LLM に典型的な多段階パイプラインで動作し、4.1 では 2 つの重要な変更が加えられています。
- 事前トレーニング + 中間トレーニング: ウェブデータに関する大規模なコーパスの事前トレーニング + ドメイン知識とマルチモーダル機能を強化するためのターゲットを絞った中間トレーニング。
- 教師あり微調整(SFT): 望ましい行動(返答、拒否戦略)に対する人間のデモンストレーション。
- 報酬モデリング(新規アプリケーション): xAIは報酬モデルを人間の好みのラベルだけでなく、 フロンティアエージェント推論モデル 報酬評価者として、つまり高性能なモデルベースの評価者が候補の出力を大規模に評価できるようにしました。これにより、検証不可能な属性の最適化が可能になりました。 スタイル、人格の統一性、共感、そして親切さ 人間によるラベル付けに莫大な予算を費やす必要もありません。
- ポリシー最適化(モデル報酬からのRLHF / RL): 学習した報酬信号を使用して展開されたポリシー (消費者が対話するモデル) を生成する標準的なポリシー最適化。
報酬モデリングのアプローチの何が新しいのでしょうか?
従来のRLHFでは、人間の好みのラベル(A/B)を収集し、それらのラベルを予測するように報酬モデルを学習し、学習した報酬に対してRL(または棄却サンプリング)を用いてベースモデルを最適化します。しかし、xAIは以下の2つの実用的なイノベーションを際立たせています。
- エージェント報酬モデル: xAIは、純粋な人間の審査員ではなく、より繊細な特性(トーン、感情のニュアンス、創造性)を評価するために、有能な「エージェント的」推論モデルを採点者として用いました。採点者は数千もの一対比較を迅速に実行できるため、エンジニアはより迅速に反復処理を行うことができます。これが、スタイルと感情知能を大幅に向上させるメカニズムです。
- 検証できない信号のトレーニング後の調整: 決定論的な指標で測定できない属性(例えば「温かさ」や「一貫した性格」)については、モデルが学習できるように特別な報酬目標とスケーリングカリキュラムを導入した。 事実の正確さを犠牲にすることなく、出力を向上させます。
「思考」と「非思考」は技術的にどのように機能するのでしょうか?
- Grok 4.1 思考(コードネーム
quasarflux) — 最終的な答えを出す前に、明示的な推論ステップ(思考トークン)を公開します。LMArenaにおける複雑なタスクや高Elo向けに最適化されています。追加トークンは推論時間を消費しますが、複数ステップの推論タスク、デバッグ、説明可能性の向上に役立ちます。 - Grok 4.1 非思考(コードネーム
tensor) 明示的な中間トークンをバイパスし、単一の即時最終応答を生成します。これにより、レイテンシとトークンコストが削減されると同時に、洗練されたポリシー重み付けの恩恵も得られます。非思考モードは、極めて低レイテンシでありながら高い性能を維持するように最適化されています。
感情とスタイルの整合最適化
Grok 4.1は、単純な「誠実さ」シグナルに加え、感情、口調、対人関係のスタイルをターゲットとしたアライメント最適化機能を備えています。つまり、トレーニングパイプラインには、口調の不一致(例えば、共感を示すべき場面で不必要にそっけない態度を取るなど)を明示的に罰し、望ましいスタイルや感情プロファイルに一致する応答を報酬とする報酬または損失コンポーネントが含まれています。Grok 4.1では、AIが初めて「パーソナリティアライメント」という最適化目標を導入しました。
モデルが一貫性と安定性のあるアイデンティティを維持できるように支援することを目的としています。Grok 4と比較して、4.1ではトレーニング目標に以下の項目が追加されています。
- 感情表現の側面に対する肯定的な報酬(感情的整合報酬)
- 性格の一貫性の指標。
Grok 4.1 はどのように評価され、どのようなパフォーマンスを発揮しましたか?
盲検による人間の嗜好テストでは何が判明しましたか?
サイレント ロールアウト中、ライブ トラフィックでは、Grok 4.1 が以前の製品モデルよりも 64.78% 多く好まれました。これは、実際の環境での会話結果が優れていることを示す、人間の強い好みのシグナルです。
Grok 4.1 はリーダーボードのトップにランクインしますか?
xAIはGrok 4.1の 考え モードは LMArenaのテキストアリーナで1位、報告されたEloは 1483、非推論(高速)モードは 1465 Elo で第 2 位にランクされています。これは、正確性とプレゼンテーション(スタイル制御が影響)の両方において、公開リーダーボードで強力な順位につけています。
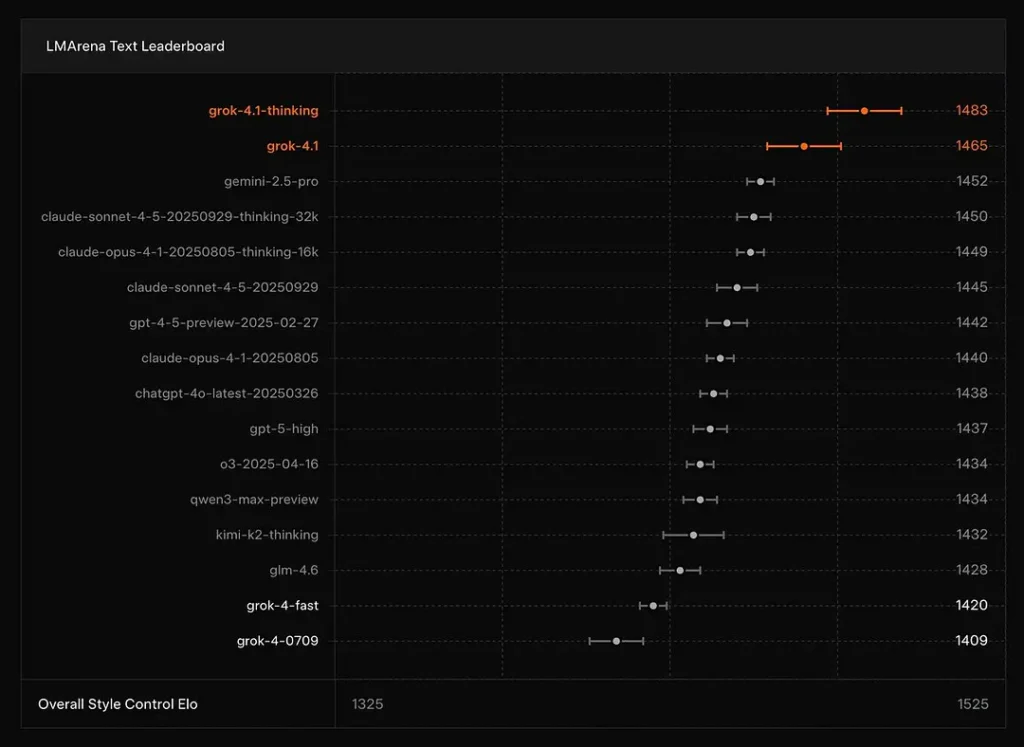
結論: Grok 4.1 は、テキストの理解、生成、全体的な品質において、主流の GPT-4.5 および Claude シリーズ モデルよりも優れており、GPT-5 Advanced Preview バージョンに次ぐ性能です。
感情的知性
xAI は、45 の難しいロールプレイ シナリオを網羅した感情知能の専門テストである EQ-Bench3 を実行し、Grok 4.1 が共感、ペース、対人洞察力において大きな向上を示したと報告しています。Grok 4.1 は、悲しみ、共感、快適さの状況を理解する上で最高得点を獲得しました。

クリエイティブライティングは実際、より想像力豊かになるのでしょうか?
Grok 4.1は クリエイティブライティング v3 (3回の反復で32のプロンプト、ルーブリックとEloスコアを使用)。xAIによると、4.1のライティングスタイル、文体の一貫性、物語の創造性は大幅に向上し、クリエイティブタスクの最近のリーダーボードで上位にランクインしました(サンプルプロンプトはリリースに含まれています)。独立したレポートでも同様の結果が得られ、レビュアーは「独特の声」が顕著に向上し、長文の一貫性が向上したと評価しました。ライティング品質の点では、Grok 4.1はGPT-5シリーズモデルに次ぐ2位であり、Claude、Gemini、Kimiの全製品ラインを上回っています。

幻覚の減少/誠実さ
xAIは幻覚発生率が著しく減少したと主張している。発表とソーシャル投稿で報告されたGrok 4.1は〜幻覚の可能性が3倍低い 以前のGrokモデルと比較して、本番環境のトラフィック分析とFActScore形式の評価(例:経歴・伝記問題セット、スコアが低いほど良い)を引用しています。特に、外部検索ツールが利用可能な「非推論モード」では、事実の一貫性がより安定しています。

Grok 4.1 が他のモデルを「圧倒」するのはなぜでしょうか。これは誇張でしょうか?
「Crushes」はマーケティングっぽいですが、その主張の裏には客観的な主張があります。
- リーダーボード: Grok 4.1は、LMArenaの公開リーダーボードでテキスト生成(思考モードで1483 Elo)において上位にランクインしており、xAIのリリースによると、クリエイティブとEQベンチの成績も非常に優れています。これらはコミュニティ全体で使用されている、同等の競争力を持つ指標です。
- 実交通優先が勝利: xAIは、ライブトラフィックへのサイレントロールアウトにおいて、ブラインド比較において人間の嗜好が勝ったことを報告しています(以前の製品モデルと比較して約65%の嗜好向上)。これは単なる紙上のベンチマークではなく、実際のユーザーによる改善を反映しています。
- 実用的な新機能: モデル グレーダー、検証不可能な信号に対する RL、およびより厳格な入力フィルターの組み合わせは、競合他社がこれまでパフォーマンスを発揮できなかった会話、共感、および創造的なタスクにおけるユーザー エクスペリエンスを直接的に改善する実用的なエンジニアリング ステップです。
つまり、「クラッシュ」は「複数の公開評価と内部評価でリードする」という言い方を華やかに表現しているが、その結論を裏付けるxAIが公開した基礎となる公開指標は
Grok 4.1 へのアクセス方法
消費者/アプリのアクセス
xAI は定期的に Grok 4.1 を「自動」モードで無料またはプロモーション期間として利用できるようにしてきましたが、プレミアム層 (SuperGrok、SuperGrok Heavy) と、より高い割り当て量による API アクセスは有料サービスとして存在し、継続されます。
Grok 4.1はすべてのユーザーに利用可能です on grok.com, X(旧ツイッター)、iOS および Android Grok アプリは、自動モードですぐに展開されると同時に、モデル ピッカーで「Grok 4.1」として明示的に選択することもできます。
APIアクセスと開発者プラン
Grok 4.1エンドポイントはxAI API経由で利用可能です。この記事の公開時点では、公式のGPT 4.1 APIはまだリリースされていません。
コメットAPI 最新のモデルダイナミクスを追跡することを約束します。 Grok 4.1 API正式リリースと同時にリリースされる予定です。どうぞご期待ください。引き続きCometAPIにご注目ください。お待ちいただく間は、Grokの他のモデルにもご注目ください。 Grokコード高速1 および グロク4をプレイグラウンドで試し、APIガイドを参照して を呼び出すための詳細な手順を確認してください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。
Grok 4.1 を本番環境で使用する際の実用的なヒント
幻覚リスクを減らす方法
- ライブ検索を有効にする または、情報検索クエリ用の検証済みツール チェーン。
- 検証手順を提供する: モデルに事実の主張のソースと証拠を返すように依頼します。
response引用を検査するためのメタデータ(利用可能な場合)。 - 決定論的チェックを実行する (ファクトチェック LLM、構造化データ検証) を、重要な出力の後処理ステップとして使用します。
トーンとスタイルをコントロールする方法
- 明確なシステムプロンプトを使用して音声を修正します(「あなたはフォーマルで共感的です。」)。
- アプリケーション間で一貫した音声を実現するために、監視付きプロンプトと小さなローカル テンプレートを使用します。
- 利用可能な場合は、xAI のスタイル制御オプションと報酬駆動型ステアリング ノブを活用します。
最終判定: Grok 4.1 は大きな変化をもたらすか?
Grok 4.1は まったく新しい建築ではなく、むしろ洗練された思慮深い トレーニング後 / アライメント チャットで人間が実際に気にしていることに焦点を当てたリリース: 性格、感情知能、創造性、事実誤認の減少リーダーボードにおける目に見える成果、大規模な実トラフィック設定、そして改良された安全対策ツール。高品質な会話、創造的なコラボレーション、あるいはトーンに配慮したアシスタンスを必要とするアプリケーションにとって、Grok 4.1は大きな前進であり、いくつかのコミュニティベンチマークにおいてリリース時点で最高のパフォーマンスを達成しました。
CometAPIは、開発者が複数のベンダーが提供する数百ものAIモデル(テキストLLM、画像/動画ジェネレーター、埋め込みなど)に、単一の一貫性のあるインターフェースを介してOpenAIスタイルのRESTアクセスを統合的に提供する商用API集約プラットフォームです。OpenAI、Anthropic、Google、Meta、あるいは小規模な専門モデルプロバイダー向けに個別のSDKや特注エンドポイントを用意する代わりに、CometAPIでは、モデル文字列といくつかのパラメータを変更するだけで、異なるモデルを呼び出すことができます。
試してみませんか?→ 今すぐCometAPIに登録しましょう !