

GLM-5は、長期的なコーディングと多段階エージェントのために構築された、Zhipu AI の新しいオープンウェイトのエージェント中心型基盤モデルです。CometAPI やプロバイダのエンドポイントを含む複数のホスト型 API を通じて利用でき、コードと重みを含む研究リリースとしても提供されています。標準的な OpenAI 互換の REST 呼び出し、ストリーミング、SDK を用いて統合可能です。
Z.ai の GLM-5 とは?
GLM-5 は、エージェント指向エンジニアリング(長期的な計画、多段階のツール利用、大規模なコード/システム設計)のために設計された Z.ai の第5世代のフラッグシップ基盤モデルです。2026年2月に一般公開された GLM-5 は、Mixture-of-Experts(MoE)モデルで、総パラメータは ~744 billion、各フォワードパスでのアクティブパラメータ集合は ~40B のレンジです。アーキテクチャと学習の選択は、長い文脈の整合性、ツール呼び出し、プロダクション向けの費用対効果の高い推論を優先しています。これにより、GLM-5 は非常に長い入力でも文脈を保持しながら、拡張されたエージェント的ワークフロー(例:ブラウズ → 計画 → コード作成/テスト → 反復)を実行できます。
Key technical highlights :
- MoE アーキテクチャ(総 ~744B/アクティブ ~40B パラメータ)。スケールした事前学習(報告では ~28.5T トークン)により、フロンティアなクローズドモデルとのギャップを縮小。
- 長文脈サポートと最適化(deep sparse attention, DSA)により、安直な密スケーリングに比べて展開コストを削減。
- エージェント機能を内蔵:ツール/関数呼び出し、ステートフルセッションのサポート、統合出力(ベンダーの UI におけるエージェントワークフローの一部として
.docx、.xlsx、.pdfの成果物を生成可能)。 - オープンウェイトの提供(モデルハブへの重み公開)とホスト型アクセスオプション(ベンダー API、推論マイクロサービス)。
GLM-5 の主な利点は?
エージェント的計画と長期的メモリ
GLM-5 のアーキテクチャとチューニングは、ワークフローにわたる一貫した多段階推論とメモリを優先しており、以下に有益です:
- 自律エージェント(CI パイプライン、タスクオーケストレーター)
- 複数ファイルにまたがるコード生成やリファクタリング
- 大きな履歴の保持を必要とする文書インテリジェンス
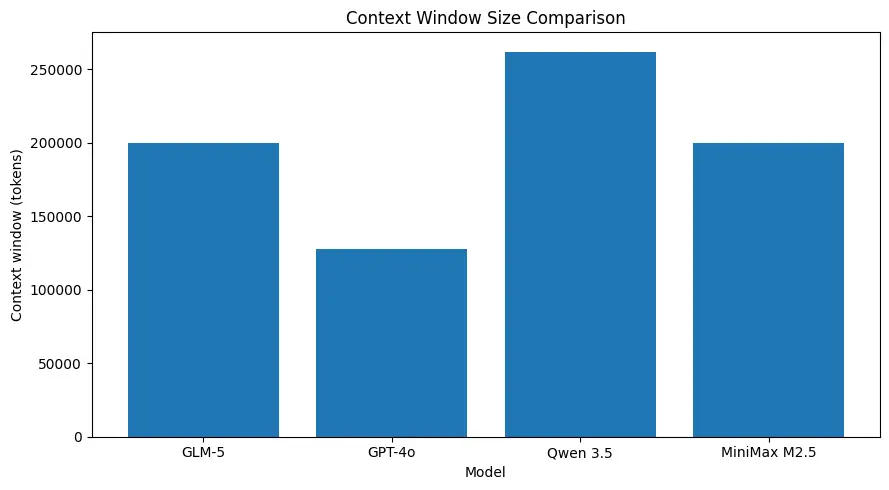
大規模なコンテキストウィンドウ
GLM-5 は公開仕様において ~200k トークン規模の非常に大きなコンテキストサイズをサポートし、1回のリクエストにより多くのセッション内容を保持できます。これにより、多くのユースケースで過度なチャンク分割や外部メモリの必要性が減ります(下記の比較チャート参照)。
システムレベルタスクにおける強力なコーディング性能
GLM-5 はソフトウェアエンジニアリングベンチマーク(SWE-bench および実用的なコード+エージェントスイート)でトップクラスのオープンソース性能を報告しています。SWE-bench-Verified では ~77.8% を記録し、コーディング/ターミナル型エージェントテスト(Terminal-Bench 2.0)ではスコアがミッド 50s に集中しています。これは、フロンティアなプロプライエタリモデルに近い実用的なコーディング能力の証拠です。これらの指標は、コード生成、自動リファクタリング、複数ファイルの推論、CI/CD アシスタントなどのタスクに GLM-5 が適していることを示します。
コスト/効率のトレードオフ
GLM-5 は MoE と「スパース」アテンションのイノベーションを用いることで、密スケーリングの力業に比べ、能力当たりの推論コストを削減することを目指しています。CometAPI は競争力のある価格帯を提供しており、エージェント的ワークロードの大量スループットに GLM-5 を魅力的な選択肢にします。
CometAPI 経由で GLM-5 API をどう使うの?
短い答え:CometAPI を OpenAI 互換のゲートウェイとして扱います。ベース URL と API キーを設定し、モデルに glm-5 を選び、chat/completions エンドポイントを呼び出してください。CometAPI は OpenAI 風の REST インターフェース(/v1/chat/completions のようなエンドポイント)に加え、SDK とサンプルプロジェクトを提供しているため、移行は容易です。
以下は実運用向けの実践レシピです:認証、基本的なチャット呼び出し、ストリーミング、関数/ツール呼び出し、コスト/レスポンス処理。
CometAPI 経由で GLM-5 にアクセスする基本手順は次のとおりです:
- CometAPI にサインアップし、API キーを取得。
- CometAPI のカタログで GLM-5 の正確なモデル ID を確認(リストに応じて
"glm-5")。 - 認証付きで CometAPI の chat/completions エンドポイント(OpenAI 形式)へ POST を送信。
Base details (CometAPI patterns): プラットフォームは https://api.cometapi.com/v1/chat/completions のような OpenAI 形式のパス、ベアラー認証、model パラメータ、system/user メッセージ、ストリーミング、そしてドキュメント内の curl/python の例をサポートしています。
例:GLM-5 を用いた Python(requests)のクイックなチャット補完
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
例:curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
ストリーミング応答(実用パターン)
CometAPI は OpenAI 形式のストリーミング(SSE/チャンク)をサポートします。Python の最も簡単なアプローチは "stream": true を指定し、到着したデータを逐次処理することです。低レイテンシな部分出力が必要な場合(リアルタイム開発アシスタント、ストリーミング UI の構築)に重要です。
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Reference: OpenAI 形式のストリーミングおよび CometAPI 互換性のドキュメント。
関数/ツール呼び出し(外部ツールの呼び出し方法)
GLM-5 は OpenAI/アグリゲーターの慣習と互換性のある関数またはツール呼び出しパターンをサポートしています(ゲートウェイはモデル応答内の構造化された関数呼び出しを中継します)。ユースケース例:GLM-5 にローカルの “run_tests” ツールの呼び出しを促すと、解析して実行できる構造化指示を返します。
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
モデルが function_call のペイロードを返したら、サーバー側でツールを実行し、その結果を "tool" ロールのメッセージとしてフィードバックして会話を継続します。このパターンにより、安全なツール呼び出しとステートフルなエージェントフローが可能になります。具体的な SDK ヘルパーについては CometAPI のドキュメントと例をご覧ください。
実用パラメータとチューニング
function_call: 構造化ツール呼び出しと安全な実行フローを有効化するために使用。
temperature: システムレベルの出力(コード、インフラ)には 0–0.3 の低温度、アイデア出しには高め。
max_tokens: 期待する出力長に設定。ホスト環境では GLM-5 は非常に長い出力をサポート(ベンダー制限は異なる)。
top_p / nucleus sampling: あり得ない裾野を抑えるのに有用。
stream: インタラクティブな UI 向けに true。
GLM-5 は Anthropic の Claude Opus や他のフロンティアモデルとどう比較される?
短い答え:GLM-5 はエージェント的およびコーディング系ベンチマークでクローズドなフロンティアモデルとの差を縮めつつ、オープンウェイトの展開と、アグリゲーターでホストされた場合のトークン当たりのコスト優位を提供します。ニュアンスとして、いくつかの絶対的なコーディングベンチマーク(SWE-bench、Terminal-Bench の各種)では Anthropic の Claude Opus(4.5/4.6)が多くの公開ランキングで数ポイント上回っていますが、GLM-5 は非常に競争力があり、他の多くのオープンモデルを凌駕します。
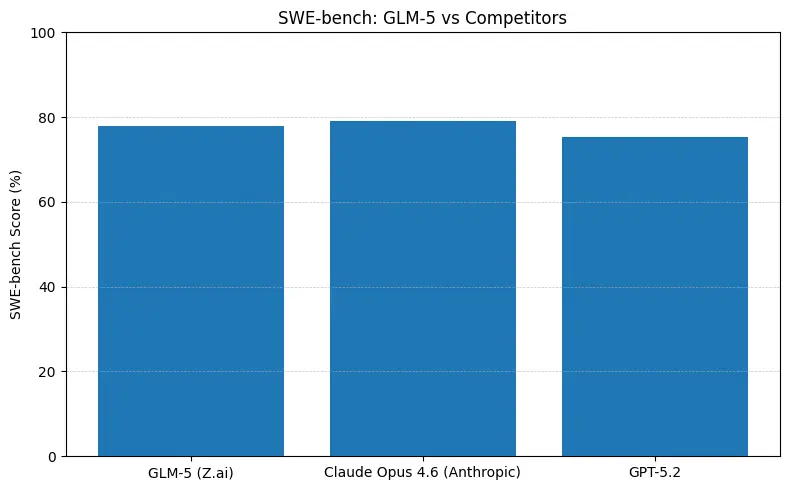
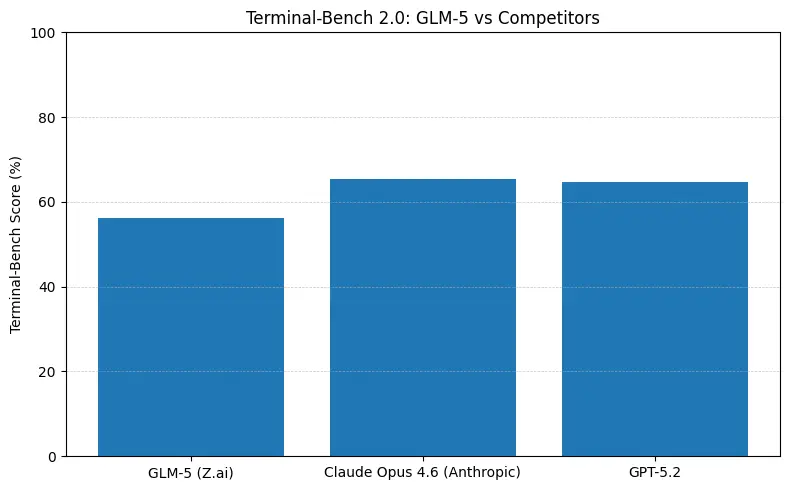
実務でこれらの数値が意味すること
- SWE-bench(コードの正確性/エンジニアリング):公開ランキングでは Claude Opus がわずかにリード(≈79% vs GLM-5 ≈77.8%)。多くの実務タスクではこの差は手動修正の少なさに現れますが、プロトタイピングやスケールしたエージェント的ワークフローのアーキテクチャ選択を左右するとは限りません。
- Terminal-Bench(コマンドラインのエージェントタスク):Opus 4.6 がリード(≈65.4% vs GLM-5 ≈56.2%)。分布外のシェル操作でも最高の信頼性が必要なら、周辺的には Opus の方が良いことが多いです。
- エージェント的/長期スパン:GLM-5 は長期的なビジネスシミュレーションで非常に良好な性能を示し(Vending-Bench 2 の残高 $4,432 を報告)、多段階ワークフローにおける計画の一貫性が強力です。製品が長時間稼働するエージェント(ファイナンス、オペレーション)なら GLM-5 は有力です。
GLM-5 から信頼できる出力を得るためのプロンプト/システム設計は?
システムメッセージと明示的制約
GLM-5 に厳格なロールと制約を与えてください。特にコードやツール呼び出しのタスクでは重要です。例:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
各非自明な変更について、テストと短い理由を要求します。
複雑なタスクの分解
「製品全体を書いて」ではなく、次のように依頼します:
- 設計アウトライン
- インターフェースシグネチャ
- 実装とテスト
- 最終統合スクリプト
この段階的分解により、幻覚が減り、検証可能な決定的チェックポイントが得られます。
決定的なコードには低温度を使用
コード生成では temperature を 0–0.2 に設定し、max_tokens を十分な上限にします。創作やブレーンストーミングでは温度を上げます。
GLM-5 を統合する際のベストプラクティス(CometAPI または直接ホスト)
プロンプトエンジニアリングとシステムプロンプト
- エージェントの役割、ツールアクセス方針、安全制約を明示するsystem指示を使用します。例:「あなたはシステムアーキテクトです:ローカルのユニットテストが合格したときだけ変更を提案し、実行する正確な CLI コマンドを列挙してください。」
- コーディングタスクでは、リポジトリの文脈(ファイル一覧、主要なコード断片)を提供し、可能ならユニットテストの出力を添付します。GLM-5 の長文脈処理は役立ちますが、必須の文脈(役割、タスク)を先に、補助資料を後にする順序を保ってください。
セッションと状態管理
- 長いエージェント会話ではセッション ID を使用し、前段の要約をコンパクトな「メモリ」として保持して文脈の膨張を防ぎます。CometAPI などのゲートウェイはセッション/状態のヘルパーを提供しますが、長時間稼働するエージェントではアプリケーション側の状態圧縮が不可欠です。
ツーリングと関数呼び出し(安全性+信頼性)
- 監査可能で範囲の狭いツールだけを公開します。人の監督なしに任意のシェル実行を許可しないでください。構造化された関数定義を用い、引数はサーバー側で検証します。
- 追跡性と事後分析のために、ツール呼び出しとモデル応答を常にログに記録してください。
コスト制御とバッチ処理
- 多量のエージェントでは、品質トレードオフが許容できるバックグラウンド処理をより安価なモデルにルーティングします(CometAPI ではモデル名で切り替え可能)。類似のリクエストをバッチ化し、
max_tokensを可能な限り減らします。入力と出力のトークン比を監視してください—出力トークンの方が高価なことが多いです。
レイテンシとスループットの設計
- インタラクティブセッションにはストリーミングを使用します。バックグラウンドのエージェントジョブでは、非同期ランタイム、ワーカキュー、レートリミッターを優先します。セルフホスト(オープンウェイト)の場合、MoE アーキテクチャに合わせてアクセラレータのトポロジーをチューニングしてください—FPGA/Ascend/専用シリコンなどの選択肢がコスト面で有利になる可能性があります。
締めのノート
GLM-5 はエージェント的エンジニアリングに向けた実用的なオープンウェイトの一歩を示します。大きなコンテキストウィンドウ、計画能力、強力なコード性能により、開発者ツール、エージェントのオーケストレーション、システムレベルの自動化に魅力的です。迅速な統合には CometAPI を、マネージドホスティングにはクラウドのモデルガーデンを利用してください。常に自分のワークロードで検証し、コストと幻覚制御のために十分な計測を行いましょう。
開発者は、GLM-5 に CometAPI 経由で今すぐアクセスできます。まずは Playground でモデルの機能を試し、詳細は API guide を参照してください。アクセス前に、CometAPI にログインして API キーを取得していることを必ず確認してください。CometAPI は公式価格よりもはるかに低い価格を提供し、統合を支援します。
準備はできましたか?→ Sign up fo M2.5 today !