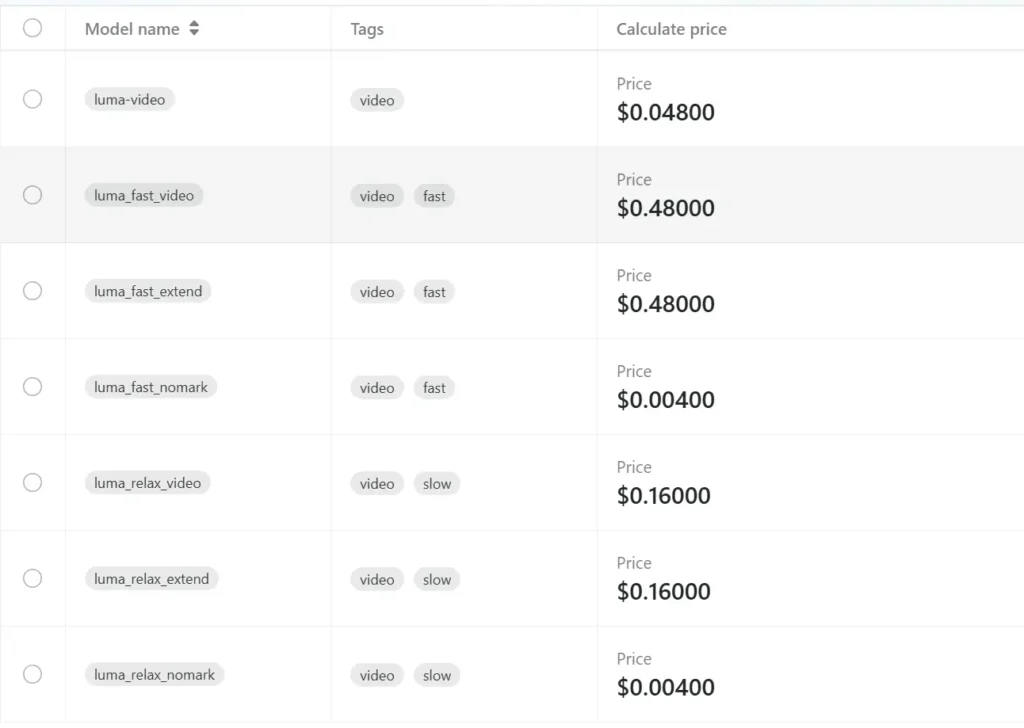
Luma AIは、コンシューマー向けおよびプロシューマー向けのコンテンツ制作において、最も話題のツールの一つとなっています。スマートフォンの写真や動画をフォトリアルな3D NeRF(Neural Engine)に変換し、Dream Machine / Ray2モデルを介してテキストや画像のプロンプトから画像やショートビデオを生成するアプリ兼クラウドサービスです。しかし、クリエイターが最初に抱く現実的な疑問の一つは、キャプチャ、レンダリング、そして動画生成に実際にどれくらいの時間がかかるのか、という点です。
Luma AI が Dream Machine (テキスト → ビデオ) クリップを生成するのにどれくらいの時間がかかりますか?
公式ベースラインタイム
Lumaの製品ページとラーニングハブでは、画像および短編動画生成パイプラインの高速なベースライン時間を提供しています。有料ユーザーと社内ベンチマークの通常条件下では、画像バッチは数十秒、短編動画ジョブは数秒から数分で計測されます。これらの公式指標は、Lumaのインフラストラクチャ(Ray2 / Dream Machineスタック)上で最適化されたモデル実行を反映しており、短く短いクリップにおける最良のケースの数値です。
実際に期待できる範囲
エッジケース / 無料枠またはピーク負荷: 空きユーザーや需要が集中する時間帯に待ち時間が発生しました 時 あるいは、キャパシティが解放されるまでジョブが「キューに滞留」することもあります。コミュニティのスレッドには、ピーク時や障害発生時に数時間も待たされたという記録があります。低レイテンシが重要な場合は、こうした変動性を考慮し、有料または優先オプションを検討してください。
**短いソーシャルクリップ(5~15秒)**多くの場合、生成ステップだけで完了することができます 1分以内から数分以内 有料ユーザーの場合、通常の負荷時に 1 時間あたり 1.5 秒かかりますが、キューイング、前処理、ストリーミング/エクスポートの手順を含めると、合計のウォールクロック時間は長くなる可能性があります。
より詳細な、またはより長いクリップ(20~60秒): これらは 数分から数十分特に高解像度、複雑なカメラワーク、反復的な改良を求める場合は、時間がかかります。第三者のレビューやユーザーアカウントによると、 5~30分 より複雑な短いビデオ用のバンド。
Luma AI が 3D キャプチャ (NeRF / Genie / 電話キャプチャ) を生成するのにどれくらいの時間がかかりますか?
典型的な3Dキャプチャワークフローとその時間プロファイル
Lumaの3Dキャプチャツール(モバイルキャプチャアプリとGenieのような機能)は、写真セットまたは録画した動画をNeRFのような3Dモデルまたはテクスチャメッシュに変換します。Dream Machineの短いクリップとは異なり、3D再構成はより重く、多くのフレームを取り込み、カメラのポーズを推定し、ボリュームジオメトリを最適化し、テクスチャを合成する必要があります。公開チュートリアルとハンズオンガイドでは、 実際の処理時間は数分から数時間までキャプチャの長さと品質に応じて異なります。よく引用されるチュートリアルの例では、 30分からXNUMX時間 中程度のキャプチャの場合。他のキャプチャ タイプ (長いウォークスルー、高解像度のフレーム) の場合は、さらに時間がかかることがあります。
代表的な範囲
- クイックオブジェクト/製品スキャン(写真20~80枚、短いキャプチャ): 数分~30分程度.
- ルームスケールまたはウォークスルーのキャプチャ(数百から数千フレーム): 30分から数時間入力サイズと最終的なエクスポートの忠実度に応じて異なります。
- ゲームエンジン向けの高忠実度エクスポート(メッシュ、高解像度テクスチャ): メッシュ生成、リトポロジー、ベイク処理に余分な時間をかけることになり、ジョブが 時.
3D動画が短い動画よりも時間がかかる理由
3D再構成は反復的で、最適化を多用します。モデルは多数のフレームにわたってボリュームフィールドとテクスチャ予測を精緻化するため、計算負荷が高くなります。Lumaのバックエンドはこれらの作業の多くを並列化しますが、ジョブごとの計算規模はXNUMX本の短い動画生成よりも依然として大きくなります。
Luma AI の処理時間に影響を与える主な要因は何ですか?
モデルとパイプラインの選択(Ray2、Photon、Genie、Modify Video)
異なるLumaモデルと機能は、それぞれ異なるトレードオフを考慮して設計されています。Ray2とDream Machineは、低遅延のインタラクティブフィードバックを備えたフォトリアルな動画生成を優先し、PhotonとGenieは画像強調や3D再構成に最適化されているため、設計上、処理が重くなる場合があります。忠実度の高い設定のモデルを選択すると、計算時間が長くなります。公式ドキュメントとAPIには、実行時間に影響を与える複数のモデルエンドポイントと品質フラグについて説明されています。
入力サイズと複雑さ
- フレーム数/写真数: 入力が増えると、最適化のステップも増えます。
- 解像度: 出力解像度が高くなり、入力解像度も高くなると、処理時間が長くなります。
- リクエストされたクリップの長さ: クリップが長くなるほど、レンダリングとモーションの一貫性のチェックがさらに必要になります。
アカウント階層、キューイング、優先順位
有料サブスクリプションおよびエンタープライズ/APIのお客様には、優先アクセスやより高いレート制限が適用される場合が多くあります。無料プランのお客様は、システムに負荷がかかっている場合、一般的にキュー時間が長くなります。コミュニティレポートもこれを裏付けており、有料プランでは一般的に待ち時間が短縮され、スループットが向上します。
システム負荷と時間帯
実際のユーザースレッドを見ると、ピーク時や主要機能のリリースによるアクセス急増時には生成時間が急増する可能性があることがわかります。Luma のチームは、キャパシティに対応するためにインフラストラクチャを継続的に更新しています(変更ログを参照)。それでも一時的な遅延は発生します。
ネットワーク/アップロード時間とクライアントデバイス
キャプチャワークフローでは、アップロード速度とデバイスのパフォーマンスが重要です。数ギガバイトの大容量キャプチャアップロードは、処理開始前の実時間を増加させます。Lumaのドキュメントでは、最大ファイルサイズについて記載されており、不要なデータ転送を最小限に抑えるためのキャプチャのベストプラクティスが推奨されています。
事前にジョブ時間を見積もって待ち時間を短縮するにはどうすればよいでしょうか?
簡単な見積もりチェックリスト
- 仕事を分類する: 画像、短いビデオ (<15 秒)、長いビデオ (>15 秒)、または 3D キャプチャ。
- 入力をカウントする: 写真の数 / ビデオの長さ (秒) / キャプチャ ファイル サイズ。
- 品質を決める: 低、標準、高の忠実度 — 忠実度が高いほど、計算時間が長くなります。
- アカウント階層を確認する: 無料 vs 有料 vs エンタープライズ; 待ち行列の可能性を考慮します。
- 簡単なテストを実行する: 実際のベースラインを収集するために 5 ~ 10 秒のテスト ジョブを作成します。
スループットを高速化するための実用的なヒント
- 推奨キャプチャパターンを使用する (スムーズなカメラの動き、一貫した照明)により、再構成がより速く収束します。Lumaのラーニングハブとモバイルアプリのページでは、キャプチャのベストプラクティスを紹介しています。
- 入力サイズを縮小する 許容できる場合: アップロード前に映像をトリミング、ダウンサンプル、またはトリミングして、処理時間とコストを削減します。
- 下書きには低品質のプリセットを選択する構成に満足したら、高品質で仕上げます。
- オフピーク時に重いランニングをスケジュールする 可能であれば、コミュニティのレポートによると、プライムタイム外にキューが減少するとのことです。
- API / エンタープライズオプションを検討する 拡張性と予測可能な SLA が必要な場合、Luma の API と変更ログには、パフォーマンスへの継続的な投資と、ワークフローを効率化するためのビデオの変更などの新しいエンドポイントが示されています。
Luma のタイミング数値は他のツールと比べてどうですか?
生成画像/動画サービスやNeRFサービスの比較は複雑です。各プロバイダーがそれぞれ異なるトレードオフ(品質、速度、コスト)を最適化しているためです。画像および非常に短い動画生成に関しては、LumaのDream Machine(特にRay2 Flashと組み合わせる)が3分未満のインタラクティブレイテンシで競合しており、これは主要な消費者向け生成サービスと同等です。一方、フルシーンのNeRFキャプチャと高忠実度XNUMXDモデル作成には、クラウドコンピューティングの要件とキューイングのプッシュ時間が高速画像生成サービスよりも高くなるため、大きなばらつきを予想し、それに応じた計画を立てる必要があります。パートナーのドキュメントやサードパーティのレポートでは、一般的に次のようなことが示されています。 短くてシンプルなレンダリングの場合は数分、複雑な 3D パイプラインの場合は数時間(または予想以上に長い)かかります。.
最終判決 — どれくらい 意志 ルマテイク my ジョブ?
すべてのユーザーやすべてのジョブに当てはまる単一の数値は存在しません。以下の実用的な基準を使って概算してください。
- 画像生成(ドリームマシン): 通常の負荷では、小さなバッチごとに約 20 ~ 30 秒かかります。
- ショートビデオ生成(Dream Machine / Ray2): 短いクリップの場合は数十秒から数分ですが、Ray2 Flash はサポートされているフローでは大幅に高速化されます。
- 3Dキャプチャ→NeRF: 非常に変動しやすい。 最良のケース: 小さなオブジェクトと軽い計算には数分かかります。 最悪のケース(報告): 需要が集中している場合や、キャプチャデータが非常に大量である場合は、数時間から数日かかることがあります。確実なスケジュールが必要な場合は、プライオリティプランまたはエンタープライズプランをご購入いただくか、実稼働前のパイロットテストを実施し、スケジュールに余裕を持ったバッファ時間を組み込んでください。
スタートガイド
CometAPIは、OpenAIのGPTシリーズ、GoogleのGemini、AnthropicのClaude、Midjourney、Sunoなど、主要プロバイダーの500以上のAIモデルを、開発者にとって使いやすい単一のインターフェースに統合する統合APIプラットフォームです。一貫した認証、リクエストフォーマット、レスポンス処理を提供することで、CometAPIはAI機能をアプリケーションに統合することを劇的に簡素化します。チャットボット、画像ジェネレーター、音楽作曲ツール、データドリブン分析パイプラインなど、どのようなアプリケーションを構築する場合でも、CometAPIを利用することで、反復処理を高速化し、コストを抑え、ベンダーに依存しない環境を実現できます。同時に、AIエコシステム全体の最新のブレークスルーを活用できます。
開発者はアクセスできる ルマAPI コメットAPI掲載されている最新モデルのバージョンは、記事の公開日時点のものです。まずは、モデルの機能をご確認ください。 プレイグラウンド そして相談する APIガイド 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。 コメットAPI 統合を支援するために、公式価格よりもはるかに安い価格を提供します。