

CometAPI経由でGemini 2.5 Flash-Liteを使い始めることは、現在利用可能な最もコスト効率が高く、低レイテンシな生成AIモデルの一つを活用する絶好の機会です。このガイドでは、Google DeepMindの最新の発表、Vertex AIドキュメントの詳細な仕様、そしてCometAPIを使用した実践的な統合手順をまとめ、迅速かつ効果的に導入・運用を開始できるよう支援します。
Gemini 2.5 Flash-Lite とは何ですか? また、なぜ検討する必要があるのですか?
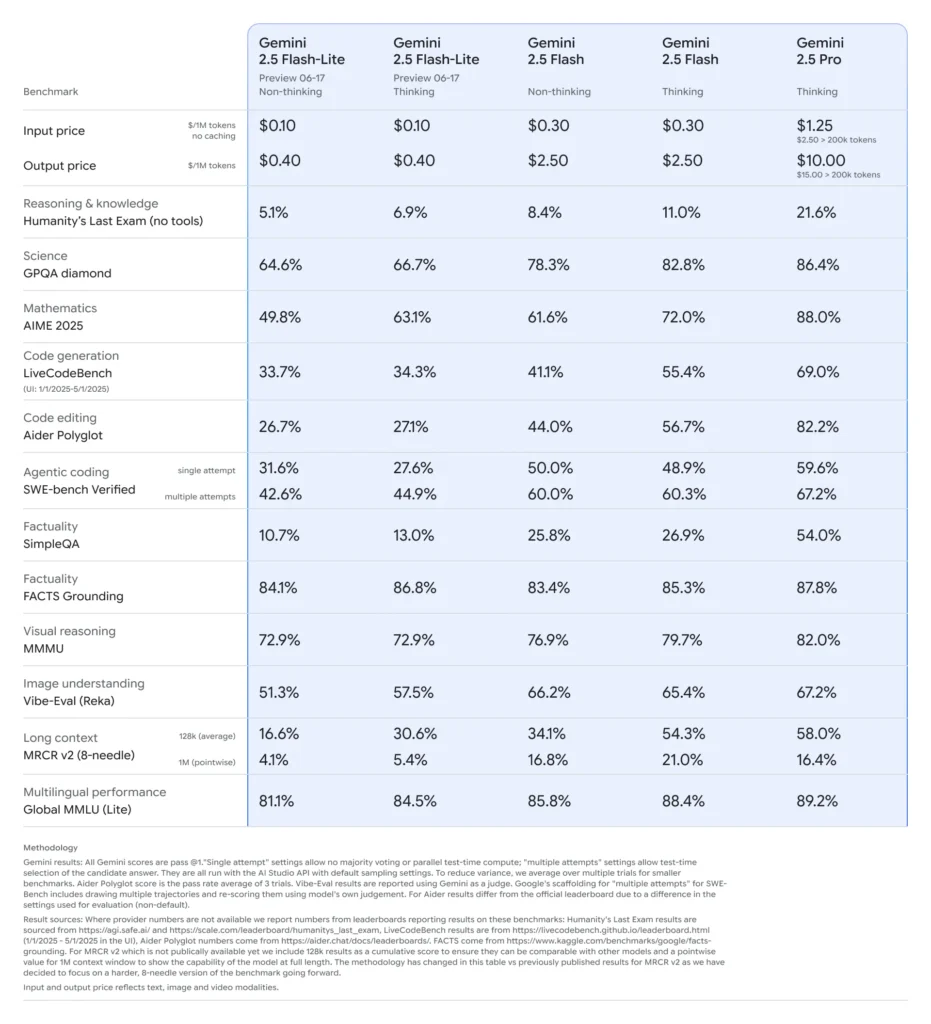
Gemini 2.5ファミリーの概要
2025年2.5月中旬、Google DeepMindはGemini 2.5シリーズを正式にリリースしました。これには、Gemini 2.5 ProとGemini 2.5 Flashの安定版GA版に加え、全く新しい軽量モデルであるGemini 2.5 Flash-Liteのプレビュー版が含まれています。速度、コスト、パフォーマンスのバランスを重視して設計されたXNUMXシリーズは、高負荷の研究ワークロードから大規模でコスト重視の導入まで、幅広いユースケースに対応しようとするGoogleの姿勢を体現しています。
Flash-Liteの主な特徴
Flash-Liteは、極めて低いレイテンシでマルチモーダル機能(テキスト、画像、音声、動画)を提供することで他社を圧倒しています。コンテキストウィンドウは最大100万トークンをサポートし、Google検索、コード実行、関数呼び出しなどのツール統合もサポートしています。特に重要なのは、Flash-Liteが「思考予算」制御を導入していることです。これにより、開発者は内部トークン予算パラメータを調整することで、推論の深さと応答時間およびコストのバランスを取ることができます。
モデルラインナップにおける位置付け
他の類似製品と比較すると、Flash-Liteはコスト効率のパレートフロンティアに位置しています。プレビュー期間中の価格は、入力トークン0.10万個あたり約0.40ドル、出力トークン0.30万個あたり約2.50ドルで、Flash(1.25ドル/10ドル)とPro(XNUMXドル/XNUMXドル)よりも低価格でありながら、マルチモーダル機能と関数呼び出しサポートの大半を維持しています。そのため、Flash-Liteは、要約、分類、軽量会話エージェントといった、大量かつ複雑性の低いタスクに最適です。
開発者が Gemini 2.5 Flash-Lite を検討する必要があるのはなぜですか?
パフォーマンスベンチマークと実世界テスト
直接比較すると、Flash-Lite は次のことを実証しました。
- スループットが2倍高速化 分類タスクでは Gemini 2.5 Flash よりも優れています。
- 3倍のコスト削減 エンタープライズ規模の要約パイプライン向け。
- 競争力のある精度 ロジック、数学、コードのベンチマークでは、以前の Flash-Lite プレビューと同等かそれ以上の結果が得られました。
理想的な使用例
- 大容量チャットボット: 数百万のユーザーにわたって一貫性のある低遅延の会話エクスペリエンスを提供します。
- 自動コンテンツ生成: ドキュメントの要約、翻訳、マイクロコピーの作成を拡張します。
- 検索と推奨のパイプライン: 迅速な推論を活用してリアルタイムのパーソナライゼーションを実現します。
- バッチデータ処理: 最小限の計算コストで大規模なデータセットに注釈を付けます。
CometAPI 経由で Gemini 2.5 Flash-Lite の API アクセスを取得および管理するにはどうすればよいですか?
CometAPI をゲートウェイとして使用する理由は何ですか?
CometAPIは、GoogleのGeminiシリーズを含む500以上のAIモデルを統合RESTエンドポイントに集約し、プロバイダ間の認証、レート制限、課金を簡素化します。複数のベースURLとAPIキーを扱う代わりに、すべてのリクエストを https://api.cometapi.com/v1ペイロードでターゲット モデルを指定し、単一のダッシュボードを通じて使用状況を管理します。
前提条件とサインアップ
- ログインする コムタピまだユーザーでない場合は、まず登録してください
- インターフェースのアクセス認証情報APIキーを取得します。パーソナルセンターのAPIトークンで「トークンを追加」をクリックし、トークンキー(sk-xxxxx)を取得して送信します。
- このサイトの URL を取得します: https://api.cometapi.com/
トークンとクォータの管理
CometAPI のダッシュボードは、Google、OpenAI、Anthropic、その他のモデル間で共有できる統合トークンクォータを提供します。組み込みの監視ツールを使用して、使用状況アラートとレート制限を設定することで、予算割り当ての超過や予期せぬ料金の発生を回避できます。
CometAPI 統合のために開発環境をどのように構成しますか?
必要な依存関係のインストール
Python 統合の場合は、次のパッケージをインストールします。
pip install openai requests pillow
- 開いている: CometAPI と通信するための互換性のある SDK。
- リクエスト: 画像のダウンロードなどの HTTP 操作用。
- 枕: マルチモーダル入力を送信する際の画像処理用。
CometAPIクライアントの初期化
環境変数を使用して、API キーをソース コードから除外します。
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
このクライアントインスタンスは、ID(例: gemini-2.5-flash-lite-preview-06-17) をリクエストに含めてください。
思考予算とその他のパラメータの設定
リクエストを送信するときに、オプションのパラメータを含めることができます。
- 気温/top_p: 生成時のランダム性を制御します。
- 候補者数: 代替出力の数。
- max_tokens: 出力トークンの上限。
- 予算の考え: 深度と速度およびコストをトレードオフする Flash-Lite のカスタム パラメーター。
CometAPI 経由の Gemini 2.5 Flash-Lite への基本的なリクエストはどのようなものですか?
テキストのみの例
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
この呼び出しは 200 ミリ秒未満で簡潔な要約を返します。これは、チャットボットやリアルタイム分析パイプラインに最適です。
マルチモーダル入力の例
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite は最大 7 MB の画像を処理し、コンテキストの説明を返すため、ドキュメントの理解、UI 分析、自動レポートに適しています。
ストリーミングや関数呼び出しなどの高度な機能をどのように活用できますか?
リアルタイムアプリケーション向けのストリーミング応答
チャットボット インターフェースまたはライブ キャプションの場合は、ストリーミング API を使用します。
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
これにより、部分的な出力が利用可能になるとすぐに配信され、インタラクティブ UI で認識される遅延が短縮されます。
構造化データ出力のための関数呼び出し
構造化された応答を強制するために JSON スキーマを定義します。
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
このアプローチにより、JSON 準拠の出力が保証され、下流のデータ パイプラインと統合が簡素化されます。
Gemini 2.5 Flash-Lite を使用する場合、パフォーマンス、コスト、信頼性をどのように最適化しますか?
予算調整の考え方
Flash-Liteの思考予算パラメータは、モデルが費やす「認知的努力」の量を調整できます。低い予算(例:0)では速度とコストが優先され、高い値ではレイテンシとトークンを犠牲にしてより深い推論が可能になります。
トークン制限とスループットの管理
- 入力トークン: リクエストごとに最大 1,048,576 トークン。
- 出力トークン: デフォルトの制限は 65,536 トークンです。
- マルチモーダル入力: 画像、音声、動画アセット全体で最大 500 MB。
大量のワークロードに対してクライアント側のバッチ処理を実装し、CometAPI の自動スケーリングを活用して、手動介入なしでバースト トラフィックを処理します。
コスト効率戦略
- 複雑度の低いタスクを Flash-Lite にプールし、負荷の高いジョブには Pro または標準の Flash を予約します。
- CometAPI ダッシュボードのレート制限と予算アラートを使用して、支出の暴走を防ぎます。
- モデル ID 別に使用状況を監視し、リクエストあたりのコストを比較して、それに応じてルーティング ロジックを調整します。
初期統合後のベストプラクティスと次のステップは何ですか?
監視、ログ記録、セキュリティ
- ロギング: パフォーマンス監査のために、リクエスト/レスポンスのメタデータ (タイムスタンプ、レイテンシ、トークンの使用) をキャプチャします。
- アラート: CometAPI でエラー率またはコスト超過のしきい値通知を設定します。
- セキュリティ: API キーを定期的にローテーションし、安全なボールトまたは環境変数に保存します。
一般的な使用パターン
- チャットボット: 迅速なユーザークエリには Flash-Lite を使用し、複雑なフォローアップには Pro を使用します。
- 文書処理: 低予算設定で PDF または画像を夜間にバッチ分析します。
- リアルタイム解析: ストリーミング API を介して財務データや運用データをストリーミングし、即座に分析情報を得ることができます。
さらに探索する
- ハイブリッドプロンプトを試してください。テキストと画像の入力を組み合わせて、より豊富なコンテキストを実現します。
- ベクター検索ツールを Gemini 2.5 Flash-Lite と統合して RAG (Retrieval-Augmented Generation) のプロトタイプを作成します。
- 競合他社の製品 (GPT-4.1、Claude Sonnet 4 など) とベンチマークして、コストとパフォーマンスのトレードオフを検証します。
生産のスケーリング
- 専用のクォータ プールと SLA 保証のために CometAPI のエンタープライズ層を活用します。
- ブルーグリーン展開戦略を実装して、ライブ ユーザーを中断せずに新しいプロンプトや予算をテストします。
- モデルの使用メトリックを定期的に確認して、さらなるコスト削減や品質向上の機会を特定します。
スタートガイド
CometAPIは、数百ものAIモデルを単一のエンドポイントに集約する統合RESTインターフェースを提供します。APIキー管理、使用量制限、課金ダッシュボードも内蔵されており、複数のベンダーURLや認証情報を管理する手間が省けます。
開発者はアクセスできる Gemini 2.5 Flash-Lite(プレビュー)API(モデル: gemini-2.5-flash-lite-preview-06-17)を通じ コメットAPI掲載されている最新モデルは、記事公開日時点のものです。まずは、モデルの機能をご確認ください。 プレイグラウンド そして相談する APIガイド 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。 コメットAPI 統合を支援するために、公式価格よりもはるかに低い価格を提供します。
わずか数ステップで、CometAPIを介してGemini 2.5 Flash-Liteをアプリケーションに統合できます。これにより、スピード、手頃な価格、そしてマルチモーダルインテリジェンスという強力な組み合わせが実現します。上記のガイドライン(セットアップ、基本的なリクエスト、高度な機能、最適化)に従うことで、ユーザーに次世代のAIエクスペリエンスを提供できるようになります。コスト効率が高く、高スループットなAIの未来がここにあります。今すぐGemini 2.5 Flash-Liteを使い始めましょう。