

Kling AIの「Omni」ローンチウィークの一環としてリリースされたKling O1は、テキスト、画像、動画を同一のリクエストで受け入れ、ディレクターレベルの反復ワークフローで動画の生成と編集の両方を行うことができる、単一の統合マルチモーダル動画基盤モデルとして位置付けられています。KlingのチームはO1を「世界初の統合マルチモーダル動画大規模モデル」と謳っています。Klingの社内テストでは、GoogleのVeo 3.1やRunway Alephと比べて大幅な性能向上が達成されているとされています。
Kling O1とは何ですか?
クリングO1(しばしば ビデオO1 or オムニワン)は、Kling AIが新たにリリースしたビデオ基盤モデルで、テキスト、画像、ビデオの生成と編集を単一のプロンプト駆動型フレームワークに統合します。テキストからビデオ、画像からビデオ、ビデオ編集を別々のパイプラインとして扱うのではなく、Kling O1は、単一のプロンプトで混合入力(テキスト+複数の画像+オプションの参照ビデオ)を受け取り、それらを推論して、一貫性のあるショートクリップを生成したり、既存の映像をきめ細かく制御して編集したりします。同社はこのロールアウトを「オムニローンチ」の一部と位置付け、O1を、複雑で複数部構成のクリエイティブな指示を解釈するためのマルチモーダルビジュアルランゲージ(MVL)パラダイムと思考連鎖(CoT)推論パスウェイを中心に構築された「マルチモーダルビデオエンジン」と説明しています。
クリング氏のメッセージは、3つの実用的なワークフローを強調しています。(1) テキスト → ビデオ生成、(2) 画像/要素 → ビデオ(明示的な参照を用いた合成と被写体/小道具の入れ替え)、(3) ビデオ編集/ショットの継続(スタイル変更、オブジェクトの追加/削除、開始フレーム/終了フレームの制御)です。このモデルは、複数の要素に対応するプロンプト(特定の参照画像を指定するための「@」構文を含む)をサポートし、開始/終了フレームのアンカーやビデオの継続といった監督スタイルの制御機能を備え、マルチショットシーケンスを構築できます。
Kling O1の5つの主な特徴
1) 真の統合マルチモーダル入力(MVL)
Kling O1の主力機能は、テキスト、静止画(複数参照)、動画を第一級の同時入力として扱うことです。ユーザーは複数の参照画像(または短い参照クリップ)を提供できます。 および 自然言語の指示に従って、モデルはすべての入力を解析し、一貫性のある出力を生成または編集します。これにより、ツールチェーンの摩擦が軽減され、「 @image1、環境に配置する @image2、動きを合わせる ref_video.mp4、そして映画のようなカラーグレードXを適用します。」この「マルチモーダルビジュアルランゲージ」(MVL)のフレーミングは、クリング氏のプレゼンの核心です。
なぜ重要なのか: 実際のクリエイティブワークフローでは、参照情報を組み合わせることがしばしば必要になります。例えば、あるアセットのキャラクター、別のアセットのカメラワーク、そしてテキストによるナレーション指示などです。これらの入力を統合することで、ワンパス生成が可能になり、手作業によるコンポジションのステップ数を削減できます。
2) 1つのモデルで編集+生成(マルチ要素モード)
従来のシステムの多くは、テキストから動画への生成とフレーム単位の編集を分離していました。O1はこれらを意図的に統合しています。クリップをゼロから作成するモデルと同じモデルで、既存の映像を編集することも可能です。オブジェクトの入れ替え、衣装のスタイリング変更、小道具の削除、ショットの延長など、すべて自然言語による指示によって行えます。この統合は、制作チームのワークフローを大幅に簡素化します。
O1 モデルは、複数のビデオ タスクを中核に緊密に統合します。
- テキストからビデオへの生成
- 画像/被写体参照生成
- ビデオ編集と修復
- ビデオのスタイル変更
- 次/前のショット生成
- キーフレーム制約付きビデオ生成
この設計の最大の意味は、これまで複数のモデルや独立したツールを必要としていた複雑なプロセスを、単一のエンジン内で完了できるようになったことです。これにより、作成コストと計算コストが大幅に削減されるだけでなく、「統合されたビデオ理解・生成モデル」の開発の基盤も築かれます。
3) ビデオ生成の一貫性
アイデンティティの一貫性: O1 モデルは、クロスモーダル一貫性モデリング機能を強化し、生成プロセス中に参照対象の構造、材質、照明、スタイルの安定性を維持します。
- 被写体モデリングのためのマルチビュー参照画像をサポートします。
- クロスショットの主題の一貫性をサポートします(キャラクター、オブジェクト、シーンの特徴は異なるショット間で連続性を保ちます)。
- 複数の被写体のハイブリッド参照をサポートし、グループポートレートの生成やインタラクティブなシーンの構築を可能にします。
このメカニズムにより、ビデオ生成の一貫性と「アイデンティティの一貫性」が大幅に向上し、広告や映画レベルのショット生成など、一貫性の要件が非常に高いシナリオに適したものになります。
メモリの改善: O1モデルは「メモリ」も備えており、長いコンテキストや命令の変更によって出力スタイルが不安定になることを防ぎます。さらに、以下の機能も備えています。
- 複数の文字を同時に覚える;
- さまざまなキャラクターがビデオ内で対話できるようにします。
- スタイル、服装、姿勢の一貫性を保つ。
4) 「@」構文と開始/終了フレーム制御による正確な合成
クリングは合成の速記法(「@」メンションシステムとして報告されている)を導入し、プロンプトで特定の画像を参照できるようにしました(例: @image1, @image2)を使用して、アセットに確実に役割を割り当てます。開始フレームと終了フレームの明示的な指定と組み合わせることで、生成されたクリップ内での要素のトランジション、移動、モーフィングをディレクターレベルで制御できます。これは、O1を多くのコンシューマー向けジェネレーターと差別化する、制作重視の機能セットです。
5) 高忠実度、長めの出力、マルチタスクスタッキング
Kling O1は、映画並みの1080p(30fps)出力が可能と報告されており、Klingの以前のバージョンを基盤として、より長いクリップ(最近の製品レビューでは最大2分)の生成が可能と謳われています。また、複数のクリエイティブタスク(生成、被写体の追加、照明の変更、構図の編集)を1回のリクエストで実行できます。これらの機能により、上位のテキスト→動画エンジンに匹敵する競争力を備えています。
なぜ重要なのか: より長く、忠実度の高いクリップと編集を組み合わせる機能により、多くの短いクリップをつなぎ合わせる必要性が減り、エンドツーエンドの制作が簡素化されます。
Kling O1 はどのように設計され、その基礎となるメカニズムは何ですか?
O1の周り マルチモーダル視覚言語(MVL) コア:言語+画像+動き信号(ビデオフレームとオプティカルフロー型の特徴)の結合埋め込みを学習し、拡散またはトランスフォーマーベースのデコーダーを適用して時間的に一貫性のあるフレームを合成するモデル。このモデルは、 コンディショニング 複数の参照 (テキスト、1 対多の画像、短いビデオ クリップ) に基づいて潜在的なビデオ表現を生成し、その後、フレーム間の注意または特殊な時間モジュールを介して時間的な一貫性を維持しながら、フレームごとの画像にデコードします。
1. マルチモーダルトランスフォーマー + ロングコンテキストアーキテクチャ
O1 モデルは、Keling が独自に開発したマルチモーダル Transformer アーキテクチャを採用し、テキスト、画像、ビデオ信号を統合し、長い時間的コンテキスト メモリ (Multimodal Long Context) をサポートします。
これにより、モデルはビデオ生成中の時間的連続性と空間的一貫性を理解できるようになります。
2. MVL: マルチモーダル視覚言語
MVL はこのアーキテクチャの中核となる革新です。
統一されたセマンティック中間層を通じて、Transformer 内の言語と視覚信号を深く整合させることで、次のことが実現します。
- 単一の入力ボックスでマルチモーダルな指示を混在できるようにする。
- モデルの自然言語記述の正確な理解を向上させる。
- 非常に柔軟なインタラクティブ ビデオ生成をサポートします。
MVL の導入により、ビデオ生成は「テキスト主導」から「セマンティックとビジュアルの共同主導」へと移行しました。
3. 思考連鎖推論メカニズム
O1 モデルは、ビデオ生成段階で「思考の連鎖」推論パスを導入します。
このメカニズムにより、モデルは生成前にイベント ロジックとタイミングの推論を実行できるため、ビデオ内のアクションとイベント間の自然な接続が維持されます。
推論と編集パイプライン
- 世代: フィード: (テキスト + オプションの画像参照 + オプションのビデオ参照 + 生成設定) → モデルが潜在的なビデオ フレームを生成 → フレームにデコード → オプションの色/時間的な後処理。
- 指示ベースの編集: フィード: (元の動画 + テキスト指示 + オプションの画像参照) → モデルは内部的に、要求された編集を一連のピクセル空間変換にマッピングし、変更されていないコンテンツを維持しながら編集されたフレームを合成します。すべてが1つのモデルに含まれているため、作成と編集の両方に同じ調整モジュールと時間モジュールが使用されます。
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
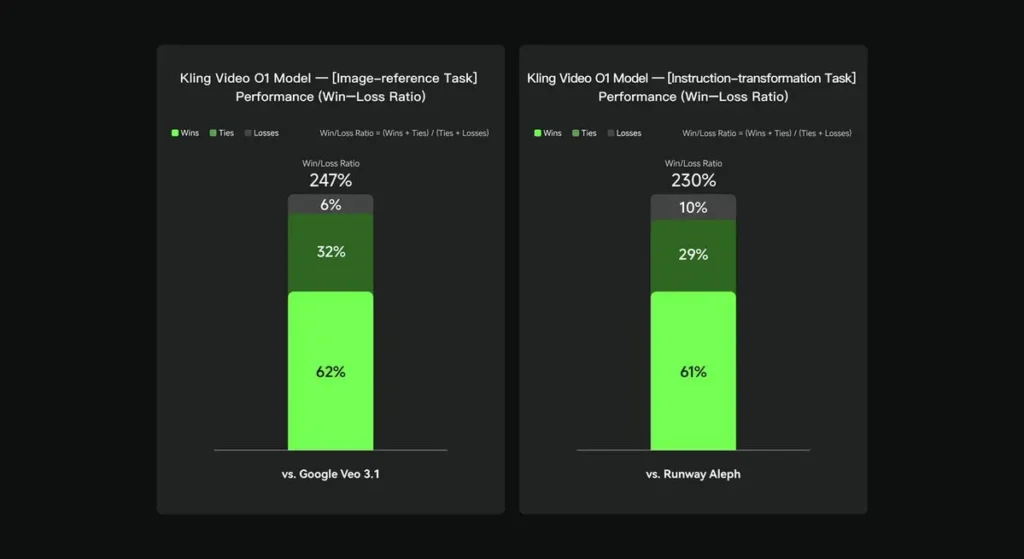
社内評価において、Keling Video O1は、いくつかの主要な側面において、既存の国際的な競合製品を大幅に上回りました。パフォーマンス結果(Keling AIが独自に構築した評価セットに基づく):
- 「画像参照」タスク: O1 は全体的に Google Veo 3.1 を上回り、勝率は 247% でした。
- 「指示の変換」タスク: O1 は Runway Aleph を上回り、勝率は 230% です。
競合他社のスナップショット(機能レベルの比較)
| 機能 / モデル | クリングO1 | グーグル ヴェオ 3.1 | 滑走路(アレフ / Gen-4.5) |
|---|---|---|---|
| 統合マルチモーダルプロンプト(テキスト+画像+ビデオ) | はい(主なセールスポイント). 単一リクエストのマルチモーダルフロー。 | 部分的 - テキスト→ビデオ + 参照が存在し、単一の統一された MVL にはあまり重点が置かれていません。 | Runway は生成 + 編集に重点を置いていますが、多くの場合は別々のモードとして機能します。最新の Gen-4.5 では、そのギャップが縮まります。 |
| 会話型/テキストベースのピクセル編集 | あり —「会話のように編集する」(マスクなし)。 | 部分的 - 編集機能は存在しますが、マスク/キーフレームのワークフローは依然として一般的です。 | Runway には強力な編集ツールがあり、強力な命令変換機能を備えています (リリースによって異なります)。 |
| 開始/終了フレーム制御とカメラ参照 | あり — 明示的な開始/終了フレームと参照カメラの動きが記述されます。 | 限定的/進化中 | 滑走路: コントロールが改善されました。UX はまったく同じではありません。 |
| ロングクリップ生成(高忠実度) | 製品資料およびコミュニティ投稿では最大約 2 分 (1080p、30fps)。 | Veo 3.1: 一貫性は強いですが、以前のバージョンではデフォルトが短かったです。モデル/設定によって異なります。 | Runway Gen-4.5: 高い品質を目指します。長さや忠実度はさまざまです。 |
まとめ:
クリングO1の名声は ワークフローの統合単一のモデルにテキスト、画像、動画の理解と、生成とリッチな指示ベースの編集の両方を、同一のセマンティックシステム内で実行させる権限を与えます。「作成」「編集」「拡張」の各ステップを頻繁に切り替えるクリエイターやチームにとって、この統合はイテレーションの速度とツールの複雑さを大幅に軽減します。時間的な一貫性の向上、開始/終了フレームの制御、そして実用的なプラットフォーム統合により、クリエイターにとってより使いやすくなっています。
Kling Video o1 API はまもなく CometAPI で利用可能になります。
開発者はアクセスできる クリング 2.5 ターボ および Veo3.1 APIについて コメットAPI掲載されている最新モデルは、記事公開日時点のものです。まずは、モデルの機能をご確認ください。 プレイグラウンド そして相談する APIガイド 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。 コメットAPI 統合を支援するために、公式価格よりもはるかに低い価格を提供します。
準備はいいですか?→ 今すぐCometAPIに登録しましょう !