

17月XNUMX日、上海のAIユニコーン企業MiniMaxが正式にオープンソース化しました。 ミニマックスM1世界初のオープンウェイト大規模ハイブリッドアテンション推論モデル。Mixture-of-Experts(MoE)アーキテクチャと新しいLightning Attentionメカニズムを組み合わせることで、MiniMax-M1は推論速度、超長コンテキスト処理、複雑なタスクパフォーマンスを大幅に向上させます。
背景と進化
の基盤の上に構築 ミニマックステキスト01MiniMax-M1は、Mixture-of-Experts(MoE)フレームワークに高速アテンションを導入し、学習時に4万トークン、推論時に最大1万トークンのコンテキストを実現したMiniMax-01シリーズの次世代モデルです。前身モデルであるMiniMax-Text-01は、合計456億個のパラメータとトークンあたり45.9億個のアクティブパラメータを備え、トップクラスのLLMと同等の性能を発揮しながら、コンテキスト機能を大幅に拡張しました。
MiniMax-M1の主な特徴
- ハイブリッドMoE + Lightning AttentionMiniMax-M1 は、スパースな Mixture-of-Experts 設計 (合計 456 億のパラメーターですが、トークンごとにアクティブ化されるのは 45.9 億のみ) と、非常に長いシーケンスに最適化された線形複雑度のアテンションである Lightning Attention を融合しています。
- 超ロングコンテキスト: までサポート 1億XNUMX万 入力トークンはDeepSeek-R128の1K制限の約XNUMX倍であり、膨大な文書の深い理解が可能になります。
- 優れた効率: 100万トークンを生成する場合、MiniMax-M1のLightning Attentionでは、DeepSeek-R25で使用される計算量の約30~1%しか必要としません。
モデルバリアント
- ミニマックスM1-40K: 1万トークンのコンテキスト、40万トークンの推論予算
- ミニマックスM1-80K: 1万トークンのコンテキスト、80万トークンの推論予算
TAU ベンチのツール使用シナリオでは、40K バリアントが、Gemini 2.5 Pro を含むすべてのオープンウェイト モデルよりも優れたパフォーマンスを発揮し、そのエージェント機能を実証しました。
トレーニング費用とセットアップ
MiniMax-M1は、高度な数学的推論からサンドボックスベースのソフトウェアエンジニアリング環境まで、多様なタスクにわたって、大規模強化学習(RL)を用いてエンドツーエンドで学習されました。新しいアルゴリズムは、 CISPO (政策最適化のためのクリップド重要度サンプリング)は、トークンレベルの更新ではなく、重要度サンプリングの重みをクリップすることで、学習効率をさらに向上させます。このアプローチとモデルの超高速アテンションを組み合わせることで、512基のH800 GPUによる完全なRL学習をわずか534,700週間で完了し、総レンタル費用はXNUMXドルでした。
可用性と価格
MiniMax-M1は、 アパッチ 2.0 オープンソースライセンスで、以下の方法ですぐにアクセスできます。
- GitHubリポジトリモデルの重み、トレーニング スクリプト、評価ベンチマークなどが含まれます。
- シリコンクラウド ホスティングでは、40Kトークン(「M1-40K」)と80Kトークン(「M1-80K」)の1つのバリエーションが提供されており、XNUMX万トークンファンネル全体を有効にする予定です。
- 現在設定されている価格は 4万あたりXNUMX円 入力用のトークンと 16万あたりXNUMX円 出力ごとにトークンが提供され、エンタープライズ顧客には数量割引が適用されます。
開発者や組織は、標準 API を介して MiniMax-M1 を統合し、ドメイン固有のデータに基づいて微調整したり、機密性の高いワークロード用にオンプレミスで展開したりできます。
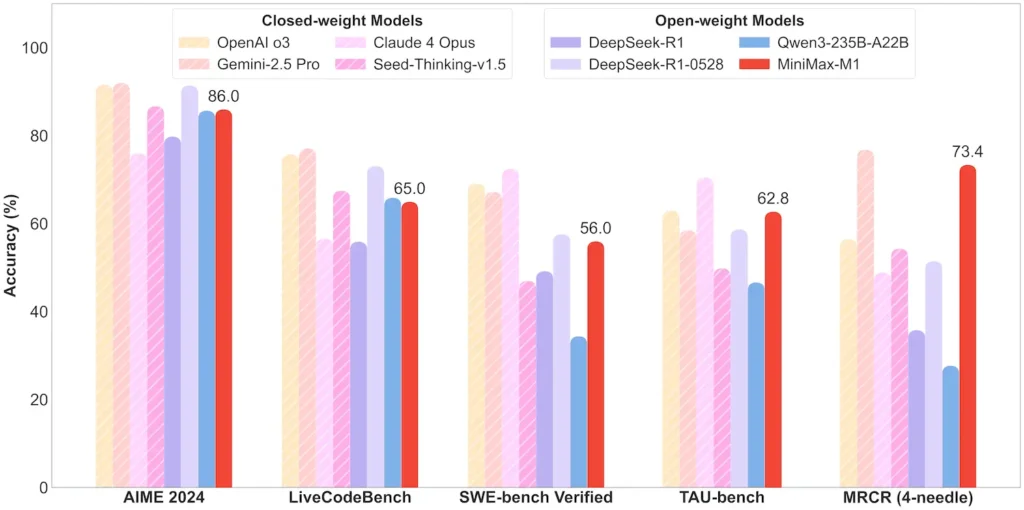
タスクレベルのパフォーマンス
| タスクカテゴリ | 特徴 | 相対的なパフォーマンス |
|---|---|---|
| 数学と論理 | AIME 2024: 86.0% | > Qwen 3、DeepSeek-R1; ほぼクローズドソース |
| 長文理解 | ルーラー(Kトークン4枚、Mトークン1枚):安定したトップティア | 4Kトークン長を超えるとGPT-128を上回る |
| ソフトウエアエンジニアリング | SWEベンチ(実際のGitHubバグ): 56% | オープンモデルの中では最高、クローズドモデルではトップに次ぐ |
| エージェントとツールの使用 | TAUベンチ(APIシミュレーション) | 62–63.5% vs. ジェミニ 2.5、クロード 4 |
| ダイアログとアシスタント | マルチチャレンジ:44.7% | クロード4、DeepSeek-R1にマッチ |
| ファクトQA | シンプルQA:18.5% | 今後の改善点 |
注:パーセンテージとベンチマークはMiniMaxの公式開示と独立したニュース報道によるものです
技術革新
- ハイブリッドアテンションスタック: 雷注意 効率とモデリング能力のバランスをとるために、周期的な Softmax Attention (2 次だがより表現力がある) とインターリーブされたレイヤー (線形コスト)。
- スパースMoEルーティング: 32 個のエキスパート モジュール。各トークンは合計パラメータの約 10% のみをアクティブ化するため、容量を維持しながら推論コストが削減されます。
- CISPO強化学習: 学習信号内の希少だが重要なトークンを保持し、RL の安定性と速度を向上させる新しい「Clipped IS-weight Policy Optimization」アルゴリズム。
MiniMax-M1 のオープンウェイトリリースにより、超長期コンテキストの高効率推論を誰でも実行できるようになり、研究と展開可能な大規模 AI の間のギャップが埋められます。
スタートガイド
CometAPIは、ChatGPTファミリーを含む数百のAIモデルを一貫したエンドポイントに集約する統合RESTインターフェースを提供します。APIキー管理、使用量制限、課金ダッシュボードが組み込まれているため、複数のベンダーURLと認証情報を管理する手間が省けます。
まず、モデルの機能を調べてみましょう。 プレイグラウンド そして相談する APIガイド 詳細な手順についてはこちらをご覧ください。アクセスする前に、CometAPIにログインし、APIキーを取得していることを確認してください。
最新の統合MiniMax-M1 APIはまもなくCometAPIに登場しますので、お楽しみに!MiniMax-M1モデルのアップロードが完了するまで、他のモデルもご覧ください。 モデルページ または、 AI プレイグラウンドMiniMaxのCometAPIの最新モデルは Minimax ABAB7 プレビュー API および ミニマックスビデオ-01 API 参照:
