Gemini 2.5 Flash は、出力品質を損なうことなく迅速な応答を実現するよう設計されています。テキスト、画像、音声、動画を含むマルチモーダル入力をサポートし、幅広い用途に適しています。Google AI Studio や Vertex AI などのプラットフォームを通じて利用でき、さまざまなシステムへのシームレスな統合に必要なツールを開発者に提供します。
基本情報(機能)
Gemini 2.5 Flash は、Gemini 2.5 ファミリーの中で差別化される際立った機能をいくつか導入しています:
- ハイブリッド推論: 開発者は thinking_budget パラメータを設定でき、出力前の内部推論に割り当てるトークン数を細かく制御できます。
- パレート・フロンティア: 最適なコストパフォーマンス点に位置し、Flash は 2.5 モデルの中で最高の価格対インテリジェンス比を提供します。
- マルチモーダル対応: テキスト、画像、動画、音声をネイティブに処理し、より豊かな会話および分析能力を実現します。
- 100万トークンのコンテキスト: 比類のないコンテキスト長により、単一リクエストでの深い分析と長文理解が可能です。
モデルのバージョニング
Gemini 2.5 Flash は、以下の主要なバージョンを経て移行しました:
- gemini-2.5-flash-lite-preview-09-2025: ツールの使いやすさを強化: 複雑な多段タスクでの性能が向上し、SWE-Bench Verified のスコアが 5% 改善(48.9% から 54%)。効率性の向上: 推論を有効化した場合、より少ないトークンで高品質な出力を達成し、レイテンシとコストを削減。
- Preview 04-17: “thinking” 機能を備えた早期アクセス版。gemini-2.5-flash-preview-04-17 で利用可能。
- Stable General Availability (GA): 2025年6月17日付で安定版エンドポイント gemini-2.5-flash がプレビューを置き換え、5月20日のプレビューから API 変更なしで本番レベルの信頼性を保証。
- Deprecation of Preview: プレビューのエンドポイントは 2025年7月15日にシャットダウン予定。ユーザーはそれまでに GA エンドポイントへ移行する必要があります。
2025年7月時点で、Gemini 2.5 Flash は一般公開され安定版です(gemini-2.5-flash-preview-05-20 からの変更はありません)。gemini-2.5-flash-preview-04-17 を使用している場合、モデルエンドポイントが 2025年7月15日に廃止・停止されるまで既存のプレビュープライシングが継続します。一般提供モデル "gemini-2.5-flash" へ移行できます。
より高速、低コスト、よりスマート:
- 設計目標: 低レイテンシ + 高スループット + 低コスト;
- 推論、マルチモーダル処理、長文タスクの全体的な高速化;
- トークン使用量を 20~30% 削減し、推論コストを大幅に低減。
技術仕様
入力コンテキストウィンドウ: 最大 100万トークンで、広範なコンテキスト保持が可能。
出力トークン: 応答あたり最大 8,192 トークンを生成可能。
対応モダリティ: テキスト、画像、音声、動画。
統合プラットフォーム: Google AI Studio と Vertex AI で利用可能。
価格: 競争力のあるトークンベースの料金モデルで、費用対効果の高い導入を実現。
技術詳細
内部的には、Gemini 2.5 Flash は transformer-based 大規模言語モデルで、web、コード、画像、動画データの混成で学習されています。主要な技術仕様は以下のとおりです:
マルチモーダルトレーニング: 複数のモダリティを整合させるように学習されており、Flash はテキストと画像、動画、音声をシームレスに組み合わせ、動画要約や音声キャプション生成のようなタスクに有用。
動的な思考プロセス: 出力の前にモデルが計画し、複雑なプロンプトを分解する内部推論ループを実装。
思考バジェットの設定可能性: thinking_budget は 0(推論なし)から 24,576 トークンまで設定でき、レイテンシと回答品質のトレードオフを調整可能。
ツール統合: Grounding with Google Search、Code Execution、URL Context、Function Calling をサポートし、自然言語プロンプトから直接、実世界のアクションを実行可能。
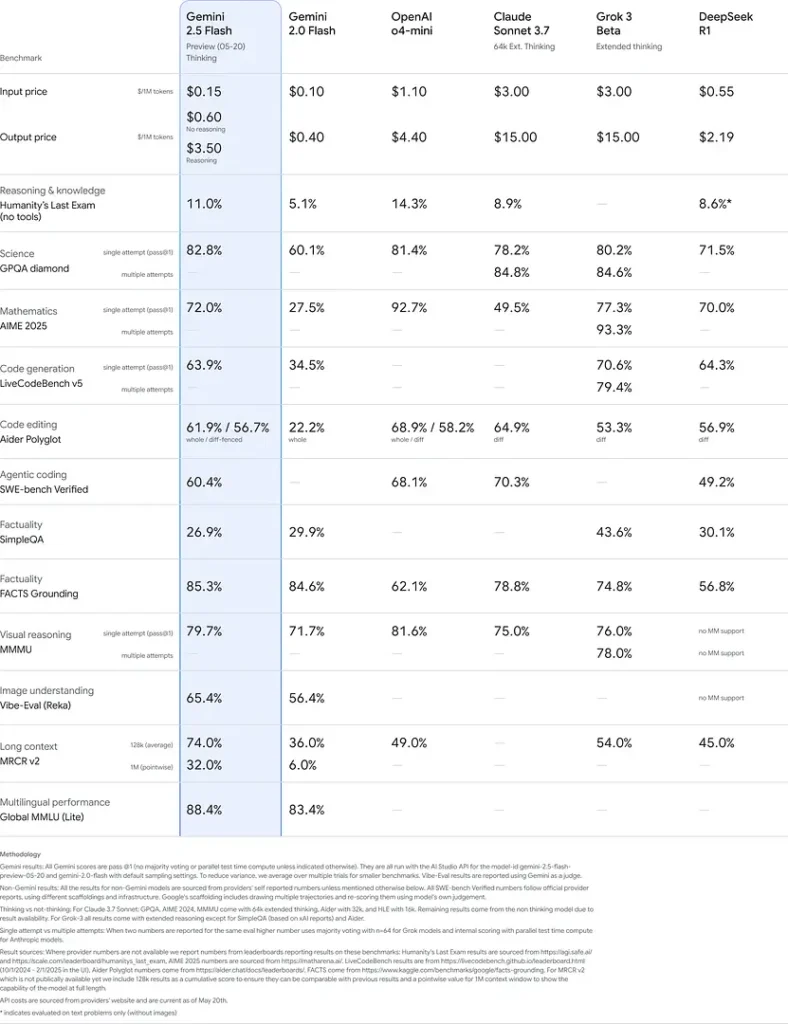
ベンチマーク性能
厳密な評価において、Gemini 2.5 Flash は業界最先端の性能を示しています:
- LMArena Hard Prompts: 難易度の高い Hard Prompts ベンチマークで、2.5 Pro に次いで第2位のスコアを記録し、強力な多段推論能力を示しました。
- MMLU スコア 0.809: MMLU 正答率 0.809 で平均的なモデル性能を上回り、幅広い領域知識と推論力を反映。
- レイテンシとスループット: デコード速度 271.4 トークン/秒、Time-to-First-Token 0.29 s を達成し、レイテンシに敏感なワークロードに最適。
- 価格対性能のリーダー: \$0.26/1 M tokens で、主要ベンチマークで同等またはそれ以上の性能を維持しつつ、多くの競合よりも低価格。
これらの結果は、推論、科学的理解、数学的問題解決、コーディング、視覚解釈、多言語能力における Gemini 2.5 Flash の競争優位性を示しています:
制限事項
強力である一方、Gemini 2.5 Flash にはいくつかの制限があります:
- 安全性リスク: モデルが“preachy”な口調を示したり、もっともらしく聞こえるが誤った、あるいは偏りのある出力(幻覚)を生成することがあります。特にエッジケースの問い合わせで顕著です。厳密な人による監督が依然として不可欠。
- レート制限: API の使用はレート制限(デフォルト階層で 10 RPM、250,000 TPM、250 RPD)により制約され、バッチ処理や大量トラフィックのアプリケーションに影響する可能性があります。
- インテリジェンスの下限: Flash モデルとしては非常に高性能ですが、高度なコーディングやマルチエージェント調整など、最も要求の厳しいエージェントタスクでは 2.5 Pro ほどの精度には及びません。
- コストのトレードオフ: 最高の価格対性能を提供する一方で、thinking モードを多用すると総トークン消費が増加し、深い推論を要するプロンプトではコストが上昇します。