技術詳細
- 適応型推論:
Gemini 2.5 Flash-Liteはオンデマンドの思考をサポートし、より深い推論が必要なときにのみ開発者が計算リソースを割り当てられるようにします。 - ツール統合: Gemini 2.5 のネイティブツールと完全互換。Grounding with Google Search、Code Execution、URL Context、Function Calling を含み、シームレスなマルチモーダルワークフローを実現します。
- Model Context Protocol (MCP): Google の MCP を活用してリアルタイムのウェブデータを取得し、応答が最新で文脈に即したものとなるよう保証します。
- デプロイオプション: CometAPI、Gemini API、Vertex AI、Google AI Studio を通じて利用可能。早期導入者向けのプレビュートラックにより、試用とフィードバックが可能です。
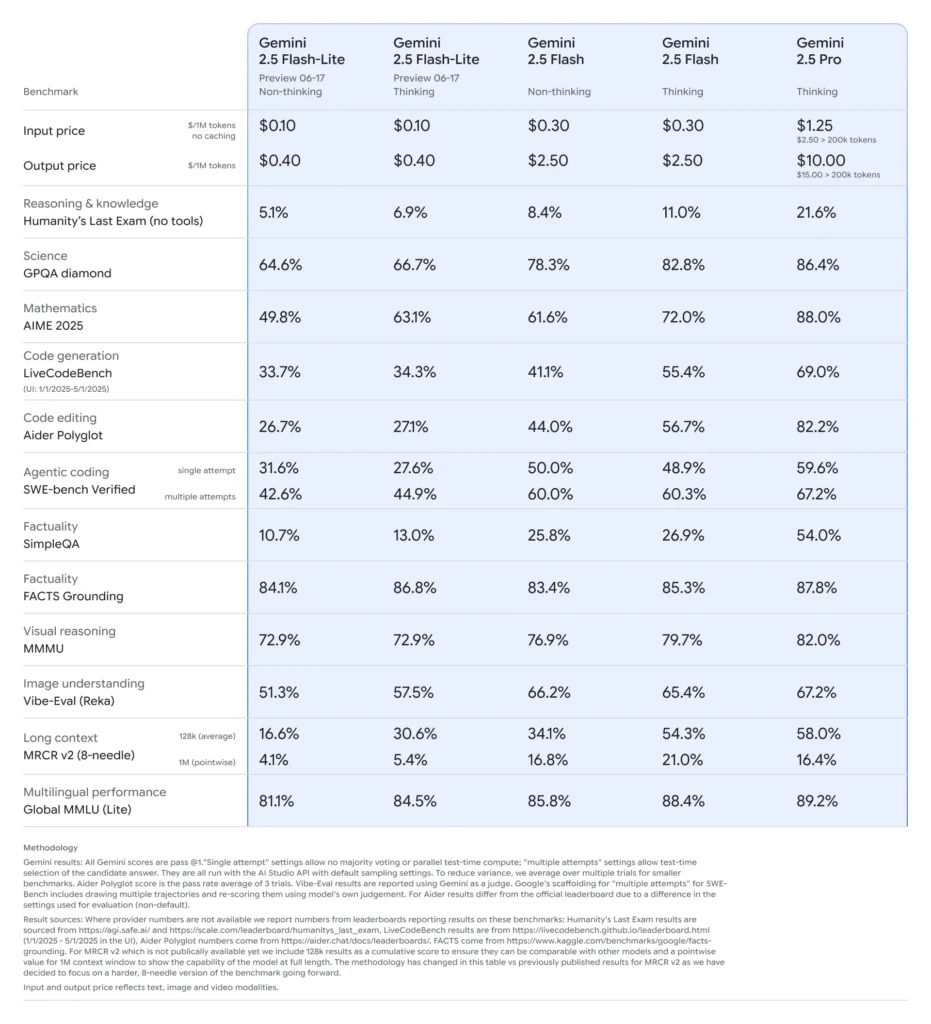
Gemini 2.5 Flash-Lite のベンチマーク性能
- レイテンシ: Gemini 2.5 Flash と比べ、中央値の応答時間を最大 50% 短縮。標準的な分類および要約ベンチマークで、一般的に100 ms 未満のレイテンシを達成。
- スループット: 高ボリュームのワークロード向けに最適化され、性能の劣化なしに毎分数万リクエストを持続的に処理可能。
- 価格性能: Flash 同等モデル比で1,000 トークンあたりのコストを 25% 削減し、コスト重視のデプロイにおけるパレート最適な選択となります。
- 業界での採用: 早期ユーザーは本番パイプラインへのシームレスな統合を報告しており、パフォーマンス指標は当初の予測に一致、もしくはそれを上回っています。
適したユースケース
- 高頻度・低複雑度のタスク: 自動タグ付け、感情分析、一括翻訳
- コスト重視のパイプライン: 大規模文書コーパスからのデータ抽出、定期的なバッチ要約
- エッジおよびモバイルのシナリオ: レイテンシが重要でリソース予算が限られる場合
Gemini 2.5 Flash-Lite の制限事項
- プレビュー段階: GA 前に API 変更が入る可能性があり、連携はバージョン更新の可能性を考慮する必要があります。
- オンザフライのファインチューニングなし: カスタム重みのアップロードは不可。プロンプトエンジニアリングとシステムメッセージに依存。
- 創造性の抑制: 決定論的で高スループットなタスク向けにチューニングされており、自由形式の生成や「創作的」なライティングには不向き。
- リソース上限: 線形スケールは ~16 vCPUs まで。それ以上ではスループットの伸びが鈍化。
- マルチモーダルの制約: 画像/音声入力をサポートするものの忠実度は限定的。大規模なビジョン処理や音声転写タスクには最適ではありません。
- コンテキストウィンドウのトレードオフ : 最大 1 M トークンを受け付けるものの、その規模での実推論ではスループット低下が生じる可能性があります。