

急速に進化する人工知能(AI)分野において、2025年には大規模言語モデル(LLM)が大きく進歩しました。その最有力候補として、AlibabaのQwen2.5、DeepSeekのV3およびR1モデル、そしてOpenAIのChatGPTが挙げられます。これらのモデルはそれぞれ独自の機能と革新性を備えています。この記事では、Qwen2.5を取り巻く最新の開発状況を詳しく検証し、その機能と性能をDeepSeekやChatGPTと比較することで、現在AIレースをリードするモデルを特定します。
Qwen2.5とは何ですか?
概要
Qwen 2.5は、Alibaba Cloudの最新の高密度デコーダー専用大規模言語モデルです。0.5Bから72Bのパラメータまで、複数のサイズで利用可能です。命令実行、構造化出力(JSON、テーブルなど)、コーディング、数学的問題解決に最適化されています。29以上の言語をサポートし、最大128Kトークンのコンテキスト長を持つQwen2.5は、多言語およびドメイン固有のアプリケーション向けに設計されています。
他社とのちがい
- 多言語サポート: 29 以上の言語をサポートし、世界中のユーザーベースに対応します。
- 拡張コンテキスト長: 最大 128K のトークンを処理し、長いドキュメントや会話の処理を可能にします。
- 特殊なバリアント: プログラミングタスク用の Qwen2.5-Coder や数学の問題解決用の Qwen2.5-Math などのモデルが含まれています。
- ユーザー補助: Hugging Face、GitHub、および新しく公開されたWebインターフェースなどのプラットフォームを通じて利用可能 チャット.qwenlm.ai.
Qwen 2.5 をローカルで使用するにはどうすればいいですか?
以下は、 7Bチャット チェックポイント。サイズが大きい場合は、GPU 要件のみが異なります。
1. ハードウェアの前提条件
| モデル | 8ビット用vRAM | 4ビット用vRAM(QLoRA) | ディスクサイズ |
|---|---|---|---|
| クウェン 2.5-7B | 14ギガバイト | 10ギガバイト | 13ギガバイト |
| クウェン 2.5-14B | 26ギガバイト | 18ギガバイト | 25ギガバイト |
4090 枚の RTX 24 (7 GB) は、完全な 16 ビット精度で 14 B の推論に十分です。このカードを XNUMX 枚使用するか、CPU オフロードと量子化を組み合わせると、XNUMX B を処理できます。
2。 インストール
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. クイック推論スクリプト
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
当学校区の trust_remote_code=True Qwenはカスタム出荷のためフラグが必要です 回転位置埋め込み ラッパー。
4. LoRAによる微調整
パラメータ効率の高い LoRA アダプタのおかげで、単一の 50 GB GPU で 24 時間以内に約 XNUMX のドメイン ペア (医療など) に対して Qwen を専門的にトレーニングできます。
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
結果のアダプター ファイル (約 120 MB) は、必要に応じてマージしたりロードしたりできます。
オプション: Qwen 2.5 を API として実行する
CometAPI は、いくつかの主要な AI モデルの API の集中ハブとして機能し、複数の API プロバイダーと個別に連携する必要がなくなります。 コメットAPI Qwen APIの統合を支援するために、公式価格よりもはるかに安い価格をご用意しています。登録してログインすると、アカウントに1ドルが付与されます。ぜひ登録してCometAPIを体験してください。Qwen 2.5をアプリケーションに組み込むことを目指している開発者の方へ:
ステップ1: 必要なライブラリをインストールする:
bash
pip install requests
ステップ2: APIキーを取得する
ステップ3: API呼び出しを実装する
API認証情報を利用してQwen 2.5にリクエストを送信します。アカウントの実際の CometAPI キーを使用します。
たとえば、Python の場合:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
この統合により、Qwen 2.5の機能をさまざまなアプリケーションにシームレスに組み込むことができ、機能性とユーザーエクスペリエンスが向上します。 “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” APIリクエストを送信し、リクエストボディを設定するためのエンドポイントです。リクエストメソッドとリクエストボディは、当社のウェブサイトのAPIドキュメントから取得できます。また、お客様の便宜を図るため、当社のウェブサイトではApifoxテストも提供しています。
を参照してください Qwen 2.5 Max API 統合の詳細については、CometAPIが最新の QwQ-32B APIComet APIのモデル情報の詳細については、以下を参照してください。 APIドキュメント.
ベストプラクティスとヒント
| シナリオ | おすすめ |
|---|---|
| 長文Q&A | パッセージを 16 K 未満のトークンに分割し、単純な 100 K のコンテキストの代わりに検索拡張プロンプトを使用して、レイテンシを削減します。 |
| 構造化された出力 | システム メッセージの先頭に次の語句を付けます。 You are an AI that strictly outputs JSON. Qwen 2.5 のアライメント トレーニングは、制約付き生成に優れています。 |
| コード補完 | 作成セッションプロセスで temperature=0.0 および top_p=1.0 決定論を最大化するために、複数のビームをサンプリングする(num_return_sequences=4)でランキング付けしました。 |
| 安全フィルタリング | 最初のパスとして、Alibaba のオープンソース「Qwen-Guardrails」正規表現バンドルまたは OpenAI の text-moderation-004 を使用します。 |
Qwen 2.5 の既知の制限
- 迅速な注射感受性。 外部監査では、Qwen 18-VL の脱獄成功率が 2.5 % であることが示されています。これは、モデルのサイズが大きいだけでは敵対的な命令から免れることはできないということを示しています。
- 非ラテン語OCRノイズ。 視覚言語タスク用に微調整すると、モデルのエンドツーエンドのパイプラインで繁体字と簡体字の中国語のグリフが混同されることがあり、ドメイン固有の修正レイヤーが必要になります。
- 128 K で GPU メモリが枯渇します。 FlashAttention-2 は RAM をオフセットしますが、72 K トークンにわたる 128 B の高密度フォワード パスには依然として 120 GB を超える vRAM が必要です。そのため、実践者はウィンドウ アテンドまたは KV キャッシュを使用する必要があります。
ロードマップとコミュニティエコシステム
Qwenチームは、 クウェン 3.0ハイブリッドルーティングバックボーン(Dense + MoE)と統合音声・視覚・テキスト事前学習をターゲットとしています。一方、このエコシステムでは既に以下のサービスが提供されています。
- Qエージェント – Qwen 2.5-14B をポリシーとして使用する ReAct スタイルの思考連鎖エージェント。
- 中国金融アルパカ – 2.5万件の規制申請でトレーニングされたQwen7‑1B上のLoRA。
- Open Interpreterプラグイン – VS Code で GPT-4 をローカル Qwen チェックポイントに置き換えます。
チェックポイント、アダプター、評価ハーネスのリストは継続的に更新されるため、Hugging Face の「Qwen2.5 コレクション」ページを参照してください。
比較分析: Qwen2.5 vs. DeepSeekおよびChatGPT
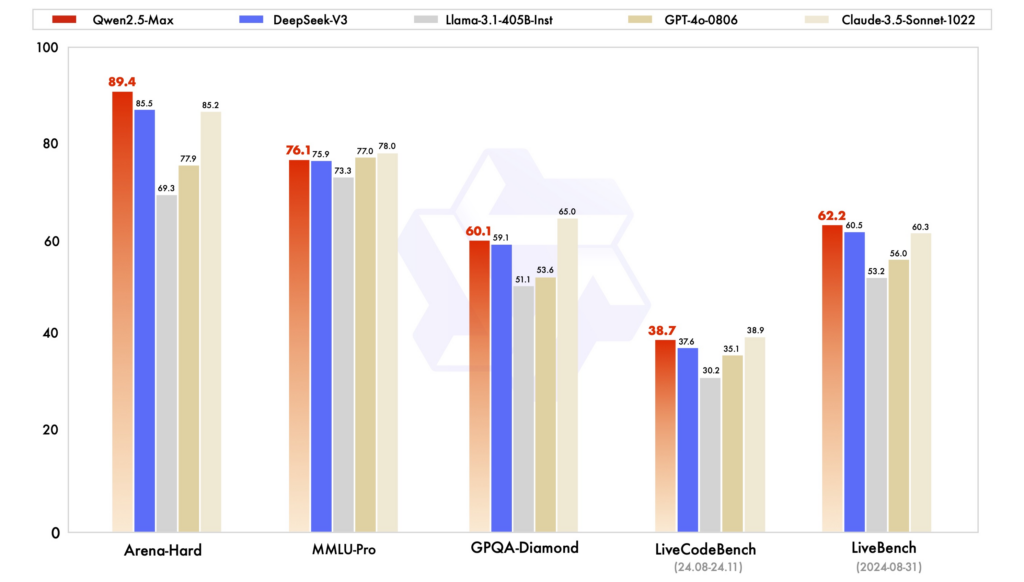
パフォーマンスのベンチマーク: Qwen2.5は、様々な評価において、推論、コーディング、多言語理解を必要とするタスクにおいて優れたパフォーマンスを示しました。MoEアーキテクチャを採用したDeepSeek-V3は、効率性とスケーラビリティに優れており、少ない計算リソースで高いパフォーマンスを実現します。ChatGPTは、特に汎用言語タスクにおいて、依然として堅牢なモデルです。
効率とコスト: DeepSeekのモデルは、MoEアーキテクチャを活用してトークンごとに必要なパラメータのみをアクティブ化することで、コスト効率の高いトレーニングと推論を実現していることで知られています。Qwen2.5は高密度でありながら、特定のタスクのパフォーマンスを最適化するための専用バリアントを提供しています。ChatGPTのトレーニングには膨大な計算リソースが必要であり、運用コストに反映されています。
アクセシビリティとオープンソースの利用可能性:Qwen2.5とDeepSeekは、GitHubやHugging Faceなどのプラットフォームでモデルを公開しており、オープンソースの原則を様々なレベルで採用しています。Qwen2.5は最近Webインターフェースをリリースし、アクセシビリティを向上させました。ChatGPTはオープンソースではありませんが、OpenAIのプラットフォームと統合を通じて広くアクセス可能です。
結論
Qwen 2.5は、 クローズドウェイトプレミアムサービス および 完全にオープンな趣味のモデル許容度の高いライセンス、多言語対応力、長期コンテキスト対応力、幅広いパラメータスケールを融合したこの言語は、研究と制作の両面で魅力的な基盤となります。
オープンソースのLLM分野が急速に発展する中、Qwenプロジェクトは次のようなことを示しています。 透明性とパフォーマンスは共存できる開発者、データ サイエンティスト、政策立案者にとって、今日 Qwen 2.5 を習得することは、より多元的で革新に優しい AI の未来への投資となります。