

GPT-5.2は、OpenAIの2025年12月のポイントリリースであり、GPT-5ファミリーの一員です。これは、テキスト + ビジョン + ツールのフラッグシップなマルチモーダルモデルファミリーで、専門的なナレッジワーク、長文脈推論、エージェンティックなツール利用、ソフトウェアエンジニアリング向けに最適化されています。OpenAIはGPT-5.2を現時点で最も高性能なGPT-5シリーズモデルと位置づけ、信頼性の高いマルチステップ推論、非常に大きなドキュメントの取り扱い、セーフティ/ポリシー準拠の改善に重点を置いて開発されたとしています。本リリースにはユーザー向けの3つのバリアント(Instant、Thinking、Pro)が含まれ、有料のChatGPT加入者とAPI顧客から順次展開されています。
GPT-5.2とは何か、なぜ重要か?
GPT-5.2はOpenAIのGPT-5ファミリーの最新メンバーで、長いドキュメント全体を跨いで推論し、ツールを呼び出し、画像を解釈し、複数ステップのワークフローを確実に実行する必要があるシステムと、単一ターンの会話アシスタントとのギャップを埋めることに特化した新しい「フロンティア」モデル系列です。OpenAIは5.2を専門的なナレッジワークにおけるこれまでで最も高性能なリリースと位置づけ、内部ベンチマーク(特にナレッジワーク向けの新しいGDPvalベンチマーク)で最先端の結果を達成し、ソフトウェアエンジニアリング系ベンチマークでのコーディング性能が強化され、長文脈およびビジョン機能が大幅に向上したとしています。
実務的には、GPT-5.2は単なる「より大きなチャットモデル」ではありません。レイテンシ、推論の深さ、コストをトレードオフする3つのチューニング済みバリアント(Instant、Thinking、Pro)から成り、OpenAIのAPIやChatGPTのルーティングと組み合わせることで、長時間のリサーチジョブを実行し、外部ツールを呼び出すエージェントを構築し、複雑な画像やチャートを解釈し、以前のリリースよりも高い忠実度で本番水準のコードを生成できます。モデルは非常に大きなコンテキストウィンドウ(OpenAIのドキュメントではフラッグシップモデルで400,000トークンのコンテキストウィンドウと128,000の最大出力制限を記載)をサポートし、明示的な推論努力レベルを指定するための新しいAPI機能や「エージェンティック」なツール呼び出し挙動を備えています。
GPT-5.2で強化された5つの中核能力
1) GPT-5.2は多段論理と数学がより得意になったか?
GPT-5.2は多段推論がより鋭くなり、数学や構造化された問題解決のパフォーマンスが目に見えて向上しています。OpenAIは、推論努力のよりきめ細かな制御(xhighなどの新レベル)、「推論トークン」サポートの実装、より長い内部推論トレースにわたってチェーン・オブ・ソートを維持するようにモデルをチューニングしたと述べています。FrontierMathやARC-AGI系のテストなどのベンチマークでは、GPT-5.1に対して大幅な改善が示され、科学・金融ワークフローで用いられるドメイン固有ベンチマークでもより大きな差で上回っています。要するに、GPT-5.2は求めに応じてより長く「考え」、より複雑な記号的/数学的作業をより高い一貫性でこなせます。

| RC-AGI-1 (Verified) 抽象推論 | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) 抽象推論 | 52.9% | 17.6% |
GPT-5.2 Thinkingは先端の科学・数学推論テストで記録を樹立しています:
- GPQA Diamond Science Quiz: 92.4% (Pro版 93.2%)
- ARC-AGI-1 Abstract Reasoning: 86.2%(90%の閾値を初めて突破)
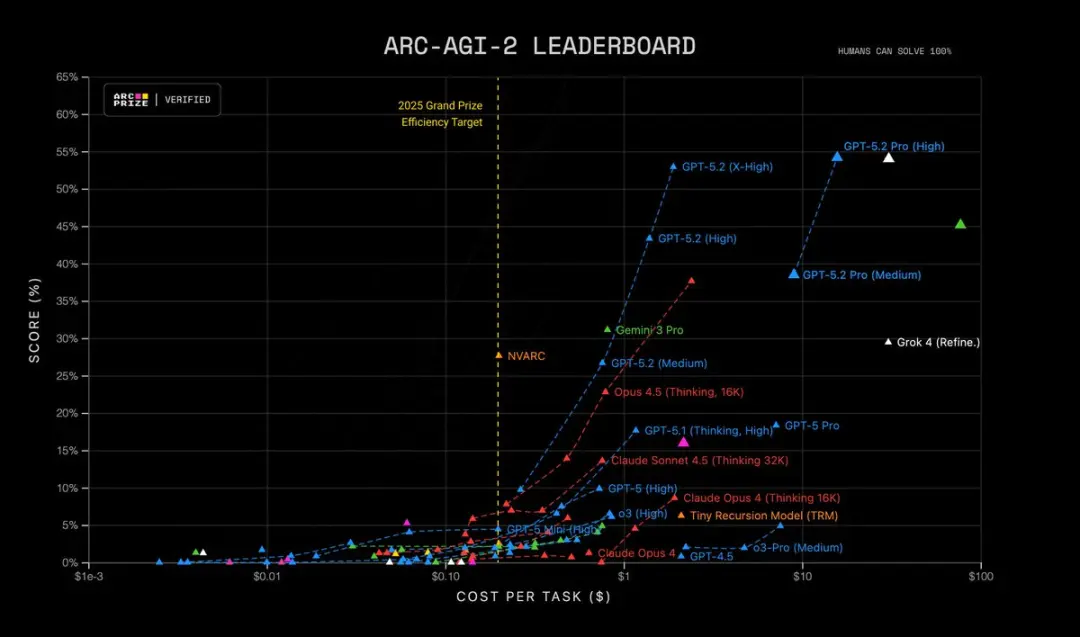
- ARC-AGI-2 Higher Order Reasoning: 52.9%、Thinking Chainモデルの新記録
- FrontierMath Advanced Mathematics Test: 40.3%、前世代を大幅に上回る
- HMMT Math Competition Problems: 99.4%
- AIME Math Test: 100% 完全解答
さらに、GPT-5.2 Pro (High) はARC-AGI-2で最先端を達成し、1タスクあたり$15.72のコストで54.2%のスコア!他のすべてのモデルを上回っています。
なぜ重要か: 多くの実世界のタスク(ファイナンシャルモデリング、実験設計、形式的推論を要するプログラム合成など)は、モデルが多数の正しいステップを連鎖させる能力にボトルネックがあります。GPT-5.2は「幻覚的なステップ」を減らし、解法過程の提示を求めた際に、より安定した中間推論過程を生成します。
2) 長文の理解と文書横断の推論はどう改善されたか?
長文脈理解は目玉改善点の一つです。GPT-5.2の基礎モデルは400kトークンのコンテキストウィンドウをサポートし、重要なのは、関連内容がコンテキストの深部に移っても高い精度を維持する点です。44の職種にわたる「明確に仕様化されたナレッジワーク」のためのタスクスイートであるGDPvalでは、GPT-5.2 Thinkingが多くのタスクでエキスパート人間審査員と同等以上の成績に達しました。独立した報告でも、このモデルが過去のモデルよりもはるかに多くの文書間で情報を保持・統合することが確認されています。デューデリジェンス、法的要約、文献レビュー、コードベース理解といったタスクにとって、これは実務的に大きな前進です。
GPT-5.2は最大256,000トークン(約200ページ超のドキュメント)のコンテキストを扱えます。さらに、「OpenAI MRCRv2」長文理解テストでは、GPT-5.2 Thinkingがほぼ100%に近い精度を達成しました。
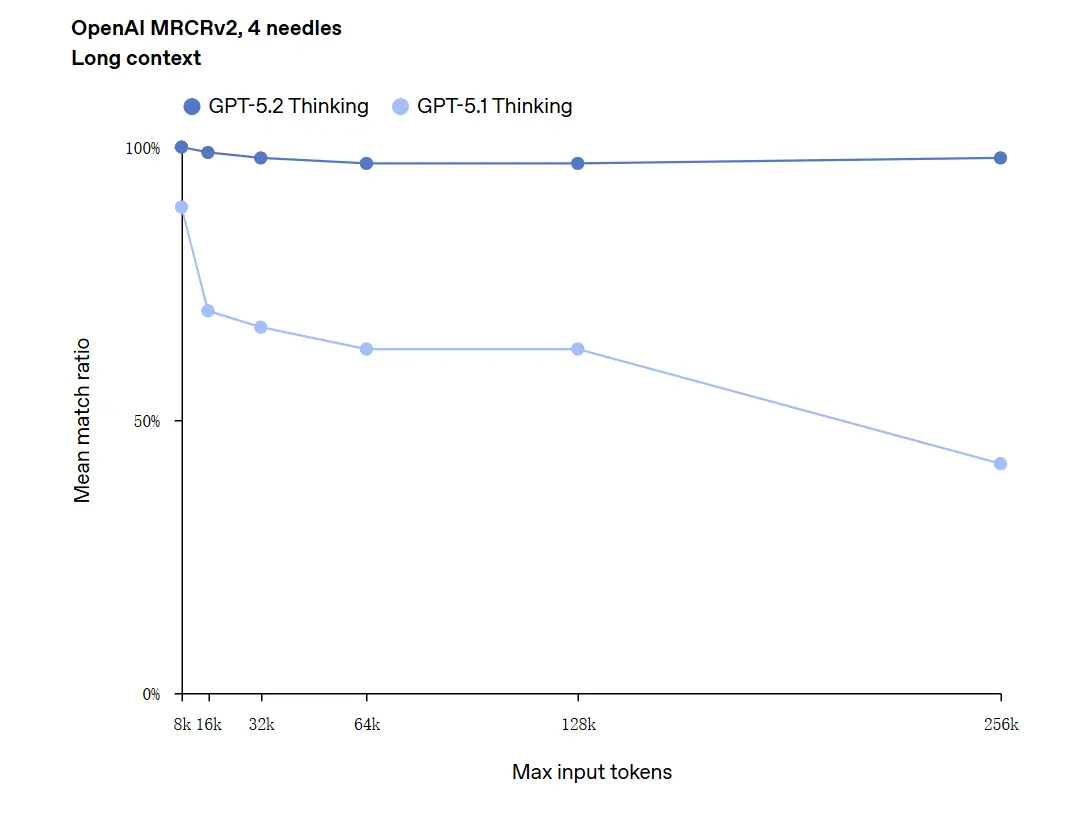
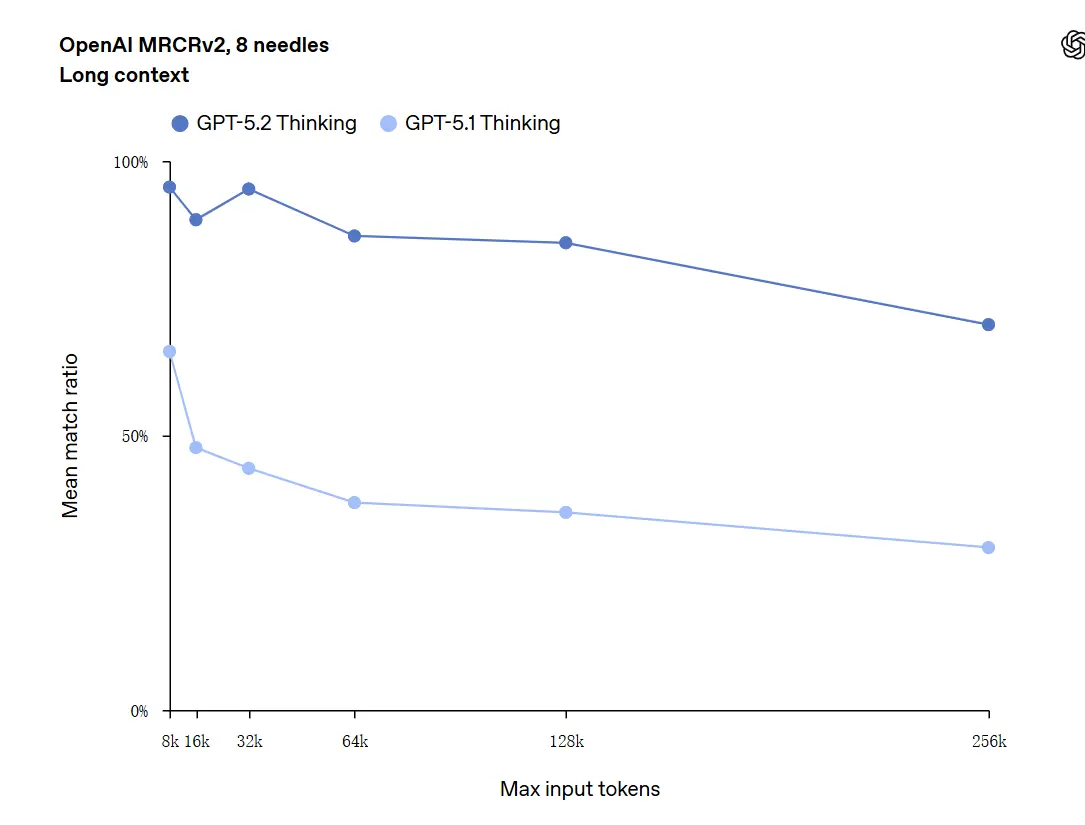
「100%の正確性」への注意: これは限定的なマイクロタスクにおいて「100%に近づく」と表現されました。OpenAIのデータは「評価されたタスクで最先端であり、多くのケースで人間の専門家レベルに匹敵または上回る」と表現するのが適切で、すべての用途で文字通り完璧という意味ではありません。ベンチマークは大きな改善を示す一方で、普遍的な完全性を意味するわけではありません。
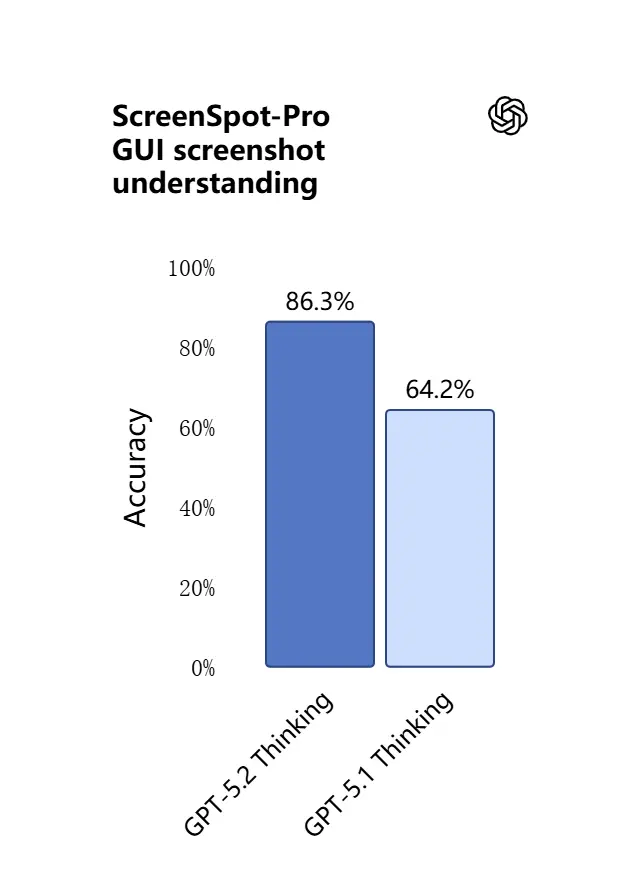
3) ビジュアル理解とマルチモーダル推論の新点は?
GPT-5.2のビジョン機能は、より精緻で実用的になりました。スクリーンショットの解釈、チャートや表の読解、UI要素の認識、長いテキストコンテキストと視覚入力の組み合わせが得意です。単なるキャプション生成ではありません。GPT-5.2は画像から構造化データ(例: PDF内の表)を抽出し、グラフを説明し、図を推論して、下流のツールアクション(例: 写真に撮ったレポートからスプレッドシートを生成)を支援する形で活用できます。
.webp)
実務的効果: チームは、スライドデッキ全体、スキャンした調査レポート、画像の多い文書をそのままモデルに入力し、文書横断の統合要約を求められるため、手作業での抽出作業が大幅に減ります。
4) ツール呼び出しとタスク実行はどう変わったか?
GPT-5.2はエージェンティックな挙動をさらに推し進め、複数ステップのタスクを計画し、外部ツールを呼び出すべきタイミングを判断し、ジョブを端から端まで完了するためのAPI/ツール呼び出しシーケンスを実行する能力が向上しました。「エージェンティックなツール呼び出し」の改善により、モデルは計画を提案し、ツール(データベース、コンピュート、ファイルシステム、ブラウザ、コードランナー)を呼び出し、結果を統合して最終成果物をより信頼性高く生成します。APIはルーティングとセーフティ制御(許可ツールリスト、ツールのスキャフォールディング)を導入し、ChatGPTのUIはリクエストを適切な5.2バリアント(Instant vs Thinking)へ自動ルーティングできます。
GPT-5.2はTau2-Bench Telecomベンチマークで98.7%を記録し、複雑なマルチターンタスクにおける成熟したツール呼び出し能力を示しました。
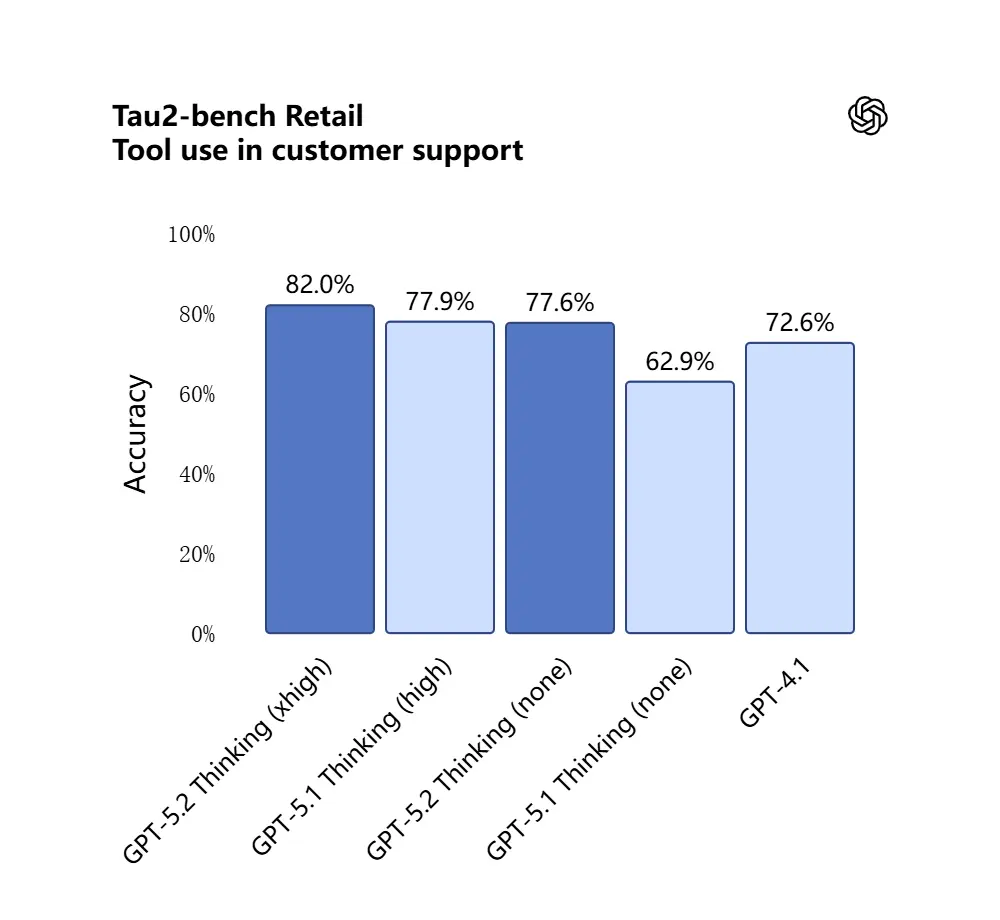
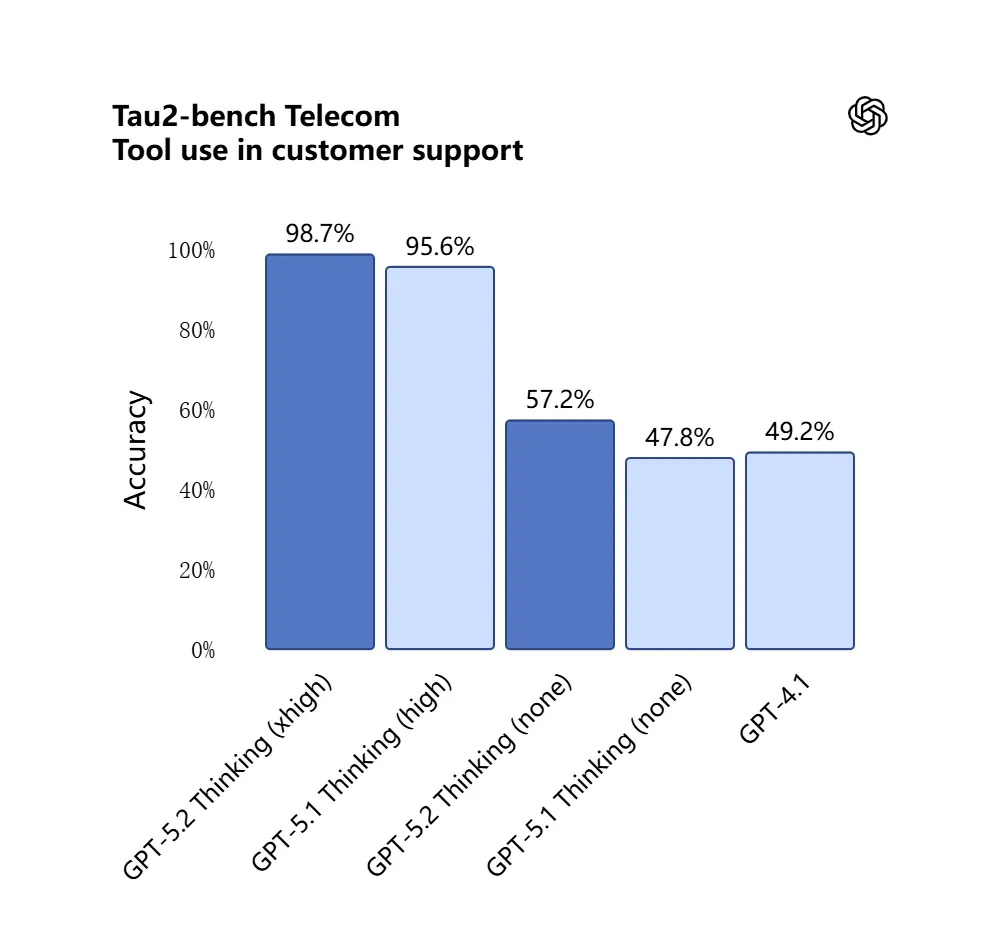
なぜ重要か: これにより、従来は慎重なオーケストレーションを要した「これらの契約書を取り込み、条項を抽出し、スプレッドシートを更新し、要約メールを書く」といったワークフローにおいて、GPT-5.2が自律的アシスタントとしてさらに有用になります。
5) プログラミング能力の進化
GPT-5.2はソフトウェアエンジニアリングタスクにおいて顕著に向上しました。より完全なモジュールを書き、テストをより確実に生成して実行し、複雑なプロジェクトの依存関係グラフを理解し、「手抜きコーディング」(ボイラープレートの省略やモジュールの結線漏れ)に陥りにくくなっています。産業グレードのコーディングベンチマーク(SWE-bench Proなど)でGPT-5.2は新記録を樹立しました。LLMをペアプログラマとして活用するチームにとって、この改善は生成後の手動検証と手戻りの削減につながります。
SWE-Bench Proテスト(実世界の産業ソフトウェアエンジニアリングタスク)では、GPT-5.2 Thinkingのスコアが55.6%に改善し、SWE-Bench Verifiedテストでも新高値の80%を達成しました。
_Software%20engineering.webp)
実務への意味:
- 本番環境コードの自動デバッグにより、より高い安定性を実現
- マルチ言語プログラミングのサポート(Pythonに限定されない)
- エンドツーエンドの修復タスクを単独で完遂可能
GPT-5.2とGPT-5.1の違いは?
短い答え: GPT-5.2は反復的だが実質的な改善です。GPT-5ファミリーのアーキテクチャとマルチモーダルの基盤を維持しつつ、実用的な4つの次元で前進しています。
- 推論の深さと一貫性。5.2はより高い推論努力レベルを導入し、多段問題の連鎖を改善。5.1も推論を改善しましたが、5.2は複雑な数学や多段ロジックの上限を引き上げました。
- 長文脈での信頼性。両バージョンともコンテキストを拡張しましたが、5.2は非常に長い入力の深部でも精度を維持するようにチューニングされています(OpenAIは数十万トークンにわたる保持の改善を主張)。
- ビジョン + マルチモーダルの忠実度。5.2は画像とテキスト間の相互参照を改善—例えば、チャートを読み、そのデータをスプレッドシートに統合—し、タスクレベルの精度が向上。
- エージェンティックなツール挙動とAPI機能。5.2は新たな推論努力パラメータ(
xhigh)やAPIでのコンテキスト圧縮機能を公開し、ChatGPTではUIが最適なバリアントを自動選択できるようルーティングロジックを洗練。 - エラー減少と安定性向上: GPT-5.2は「幻覚率」(誤回答率)を38%削減。調査、ライティング、分析の質問により安定して回答し、「でっち上げた事実」の発生が減少。複雑なタスクでは構造化出力が明確になり、論理がより安定。あわせて、メンタルヘルス関連タスクでの応答安全性が大幅に改善。メンタルヘルス、自傷、自殺、情緒的依存のようなセンシティブな状況でもより堅牢に振る舞います。
システム評価では、GPT-5.2 Instantが「メンタルヘルス支援」タスクで0.995(1.0満点)を記録し、GPT-5.1(0.883)を大きく上回りました。
定量的には、OpenAIの公開ベンチマークはGDPval、数学ベンチマーク(FrontierMath)、ソフトウェアエンジニアリング評価での測定可能な向上を示しています。ジュニア投資銀行業務のスプレッドシートタスクでも、GPT-5.2はGPT-5.1を数ポイント上回ります。
GPT-5.2は無料か—費用はいくらか?
GPT-5.2を無料で使えるか?
OpenAIはGPT-5.2を有料のChatGPTプランとAPIアクセスから展開しました。歴史的にOpenAIは、最速/最深のモデルを有料ティアの背後に置き、より軽量のバリアントを後に広く提供してきました。5.2でも、まず有料プラン(Plus、Pro、Business、Enterprise)から開始し、APIを開発者に提供するとしています。つまり、直ちに無料でのフルアクセスは限定的であり、無料ティアは(スケールに応じて)後から軽量サブバリアントへのルーティングや抑制されたアクセスを受ける可能性があります。
良いニュースとして、CometAPI はすでに GPT-5.2 と統合され、現在クリスマスセール中です。CometAPI経由でGPT-5.2を利用でき、PlaygroundでGPT-5.2と自由に対話できるほか、開発者はGPT-5.2のAPI(CometAPIはOpenAIの価格の20%)を使ってワークフローを構築できます。
API(開発/本番利用)ではいくらか?
APIの利用はトークン単位で課金されます。ローンチ時のOpenAIの公開プラットフォーム価格は以下のとおり(CometAPIはOpenAIの価格の20%):
- GPT-5.2(標準チャット) — 1M入力トークンあたり$1.75、1M出力トークンあたり$14(キャッシュ入力の割引が適用)。
- GPT-5.2 Pro(フラッグシップ) — 1M入力トークンあたり$21、1M出力トークンあたり$168(高精度・高計算ワークロード向けのため大幅に高価)。
- 参考までに、GPT-5.1はより安価でした(例: 1Mトークンあたり 入力$1.25 / 出力$10)。
解釈: APIコストは前世代に比べて上昇。5.2の高水準の推論と長文脈性能は、独立したプロダクト階層として価格付けされています。本番システムでは、入力/出力トークン数とキャッシュ入力の再利用頻度(キャッシュ入力は大幅割引)にコストが大きく依存します。
実務上の意味
- ChatGPTのUI経由のカジュアル利用では、月額サブスクリプション(Plus、Pro、Business、Enterprise)が主な経路。5.2のリリースでもChatGPTのサブスクリプション価格は変更されていません(モデル提供内容が変わってもプラン価格は安定維持)。
- 本番・開発利用では、トークンコストを予算化。長い応答をストリームしたり長文書を処理するアプリでは、出力トークンの価格(Thinkingで$14 / 1Mトークン)がコストの大半を占めやすく、入力のキャッシュや出力の再利用を綿密に行わない限りコストが膨らみます。
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAIはGPT-5.2を、ユースケースに合わせて3つの目的別バリアント(Instant、Thinking、Pro)でリリースしました。
- GPT-5.2 Instant: 高速・コスト効率重視。FAQ、ハウツー、翻訳、素早い下書きなど日常業務向け。低レイテンシで、初稿や簡単なワークフローに適する。
- GPT-5.2 Thinking: 継続的な作業向けの高品質な応答。長文書要約、多段計画、詳細なコードレビューなどに強い。レイテンシと品質のバランスが良く、プロフェッショナルタスクのデフォルトの主力。
- GPT-5.2 Pro: 最高品質と信頼性。より遅く高コストだが、難易度が高く重要度の高いタスク(複雑なエンジニアリング、法的統合、重大な意思決定)や「xhigh」の推論努力が必要な場面に最適。
比較表
| Feature / Metric | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Intended use | 日常タスク、素早い下書き | 深い分析、長文書 | 最高品質、複雑な問題 |
| Latency | 最低 | 中程度 | 最高 |
| Reasoning effort | Standard | High | xHigh available |
| Best for | FAQ、チュートリアル、翻訳、短いプロンプト | 要約、計画、スプレッドシート、コーディングタスク | 複雑なエンジニアリング、法的統合、リサーチ |
| API name examples | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Input token price (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Output token price (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Availability (ChatGPT) | 展開中;有料プランから順次拡大 | 有料プランへ展開中 | Proユーザー / Enterprise(有料) |
| Typical use case example | メール下書き、軽微なコードスニペット | 複数シートの財務モデル作成、長文レポートのQ&A | コードベース監査、本番水準のシステム設計生成 |
誰に適しているか?
企業・プロダクトチーム
リサーチアシスタント、契約レビュー、分析パイプライン、開発者向けツールなどのナレッジワーク製品を構築する場合、GPT-5.2の長文脈とエージェンティックな機能は統合の複雑さを大幅に減らせます。堅牢な文書理解、自動レポート、インテリジェントなコパイロットを必要とする企業には、Thinking/Proが有用です。Microsoftなどのプラットフォームパートナーはすでに生産性スタック(例: Microsoft 365 Copilot)に5.2を統合しています。
開発者・エンジニアリングチーム
LLMをペアプログラマとして利用したい、またはコード生成/テストの自動化を行いたいチームは、5.2のプログラミング忠実度の向上の恩恵を受けます。APIアクセス(thinkingやproモード)により、400kトークンのコンテキストウィンドウを活用して大規模なコードベースのより深い統合が可能です。ProのAPIコストは高くなりますが、複雑なシステムでは手動デバッグやレビューの削減で費用対効果が見合う可能性があります。
研究者・データ中心のアナリスト
文献の統合、長い技術レポートの解析、モデル支援の実験設計を日常的に行う場合、GPT-5.2の長文脈と数学の改善はワークフローを加速します。再現可能な研究のためには、慎重なプロンプト設計と検証ステップを組み合わせると良いでしょう。
中小企業・パワーユーザー
ChatGPT Plus(およびパワーユーザー向けのPro)は5.2バリアントへのルーティングアクセスを得られます。これにより、API統合を行わなくても小規模チームが高度な自動化や高品質のアウトプットを利用できるようになります。非技術ユーザーにとっても、より良い文書要約やスライド作成が実務レベルで向上します。
開発者・運用者向け実用メモ
注目すべきAPI機能
reasoning.effortレベル(例:medium、high、xhigh)により、内部推論にかける計算量を指示可能。これでリクエストごとにレイテンシと精度をトレードできます。- コンテキスト圧縮: 履歴を圧縮・コンパクト化して、本当に関連する内容を長いチェーンでも保持。効果的なトークン使用を抑える上で重要です。
- ツールのスキャフォールディング & 許可ツール制御: 本番システムでは、モデルが呼び出せるツールを明示的にホワイトリスト化し、ツール呼び出しを監査ログに記録すべきです。
コスト管理のヒント
- よく使うドキュメント埋め込みをキャッシュし、同じコーパスに対する繰り返しクエリではキャッシュ入力(大幅割引)を利用。OpenAIのプラットフォーム価格はキャッシュ入力に大きな割引があります。
- 探索的/低価値のクエリはInstantへルーティングし、Thinking/Proはバッチジョブや最終パスに限定。
- APIコスト見積もりでは、入出力トークンの合計を慎重に算出。長い出力はコストを乗算的に増やします。
結論—GPT-5.2にアップグレードすべきか?
長文書推論、文書横断の統合、マルチモーダル解釈(画像 + テキスト)、ツールを呼び出すエージェント構築に依存する業務なら、GPT-5.2は明確なアップグレードです。実用精度が向上し、手作業の統合作業が減ります。一方で、高ボリューム・低レイテンシのチャットボットや厳しい予算制約のアプリケーションには、Instant(または以前のモデル)が依然として妥当な選択かもしれません。
GPT-5.2は、「より良いチャット」から「より良いプロフェッショナルアシスタント」への意図的なシフトを体現します。より多くの計算資源、より高い能力、より高いコスト階層—しかし、信頼できる長文脈、改善された数学/推論、画像理解、エージェンティックなツール実行を活用できるチームにとって、実際の生産性向上につながります。
始めるには、Playground でGPT-5.2モデル(GPT-5.2;GPT-5.2 pro、GPT-5.2 chat)の機能を試し、詳細は API guide を参照してください。アクセス前に、CometAPIにログインしてAPIキーを取得していることを確認してください。CometAPI は公式価格を大きく下回る価格で統合を支援します。
Ready to Go?→ Free trial of gpt-5.2 models !