

GPT-5.2 は OpenAI が 2025 年 12 月にリリースした GPT-5 ファミリーのポイントリリースであり、フラッグシップのマルチモーダルモデルファミリー(テキスト + ビジョン + ツール)です。これは、プロフェッショナルな知識労働、長い文脈での推論、エージェント的なツール使用、ソフトウェアエンジニアリングに向けてチューニングされています。OpenAI は GPT-5.2 を GPT-5 シリーズで最も高性能なモデルと位置づけ、信頼できるマルチステップ推論、非常に大きなドキュメントの取り扱い、安全性/ポリシー準拠の改善に重点を置いて開発したとしています。リリースにはユーザー向けに Instant、Thinking、Pro の 3 つのバリアントが含まれ、まずは有料の ChatGPT サブスクライバーと API 顧客に展開されます。
GPT-5.2 とは?なぜ重要なのか?
GPT-5.2 は OpenAI の GPT-5 ファミリーの最新メンバーであり、長いドキュメントを跨いで推論し、ツールを呼び出し、画像を解釈し、マルチステップのワークフローを確実に実行する必要があるシステムと、単発の会話型アシスタントとのギャップを埋めることを狙った新たな「フロンティア」モデルシリーズです。OpenAI は 5.2 をプロフェッショナルな知識労働における最も有能なリリースと位置づけ、(特に知識労働向けの新しい GDPval ベンチマークで)社内ベンチマークにおいて新たな SOTA を達成し、ソフトウェアエンジニアリング系ベンチマークでのコーディング性能が向上し、長文脈およびビジョン機能が大幅に改善されたと述べています。
実用面では、GPT-5.2 は単なる「より大きなチャットモデル」ではありません。レイテンシ、推論の深さ、コストのトレードオフを持つ 3 つのチューニング済みバリアント(Instant、Thinking、Pro)で構成され、OpenAI の API と ChatGPT のルーティングと組み合わせることで、長時間のリサーチジョブの実行、外部ツールを呼ぶエージェントの構築、複雑な画像やチャートの解釈、そして従来より高い忠実度での本番グレードのコード生成が可能です。モデルは非常に大きなコンテキストウィンドウ(OpenAI のドキュメントではフラッグシップモデルで 400,000 トークンのコンテキストウィンドウと 128,000 の最大出力上限を記載)をサポートし、明示的な推論負荷レベルのための新 API 機能や「エージェント的」ツール呼び出し動作を備えています。
GPT-5.2 でアップグレードされた 5 つの中核機能
1) GPT-5.2 はマルチステップのロジックと数学に強くなったのか?
GPT-5.2 はマルチステップ推論がより鋭くなり、数学や構造化問題解決で目に見える性能向上を示します。OpenAI は、推論負荷のより細かな制御(xhigh などの新レベル)、「推論トークン」対応の設計、より長い内部推論痕跡にわたってチェイン・オブ・ソートを維持するようモデルをチューニングしたと述べています。FrontierMath や ARC-AGI スタイルのテストでは GPT-5.1 と比べ顕著な向上が見られ、科学・金融ワークフロー向けのドメイン固有ベンチマークでもより大きな差を示します。要するに、GPT-5.2 は求められれば「より長く考え」、より複雑な記号的/数学的作業を安定してこなせるようになりました。

| RC-AGI-1 (Verified) Abstract reasoning | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) Abstract reasoning | 52.9% | 17.6% |
GPT-5.2 Thinking は複数の先端的な科学・数学推論テストで記録を更新:
- GPQA Diamond Science Quiz: 92.4%(Pro バージョン 93.2%)
- ARC-AGI-1 Abstract Reasoning: 86.2%(初めて 90% の閾値を突破)
- ARC-AGI-2 Higher Order Reasoning: 52.9%、Thinking Chain モデルの新記録
- FrontierMath Advanced Mathematics Test: 40.3%、前世代を大きく上回る
- HMMT Math Competition Problems: 99.4%
- AIME Math Test: 100% 完全解答
さらに、GPT-5.2 Pro(High)は ARC-AGI-2 で SOTA を達成し、1 タスクあたり $15.72 のコストで 54.2% を記録!他のすべてのモデルを上回りました。
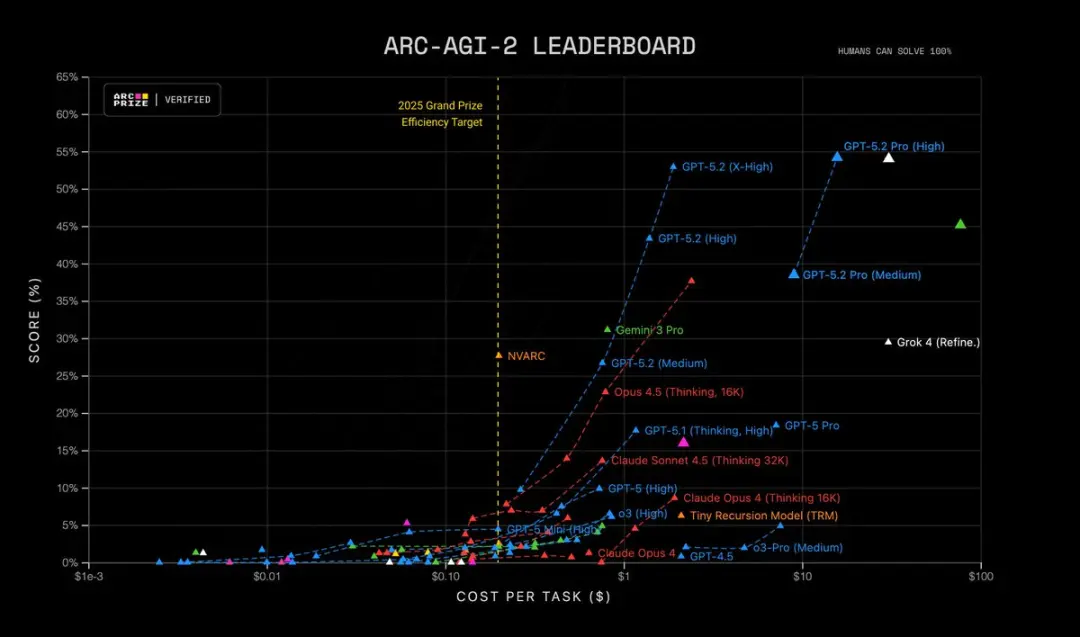
なぜ重要か: 多くの実世界タスク(財務モデリング、実験設計、形式的推論を要するプログラム合成など)は、モデルが多くの正しいステップを連鎖できるかどうかにボトルネックがあります。GPT-5.2 は「幻覚的なステップ」を減らし、作業過程の開示を求めたときに、より安定した中間推論の痕跡を生成します。
2) 長文テキスト理解とドキュメント横断推論はどのように改善されたか?
長文脈の理解は注目の改善点の 1 つです。GPT-5.2 の基盤モデルは 400k トークンのコンテキストウィンドウをサポートし、重要なのは、関連コンテンツが文脈の深部に移っても高い正確性を維持することです。よく定義された知識労働タスクから成る GDPval(44 の職種を対象)では、GPT-5.2 Thinking が多くのタスクで人間の専門審査員と同等またはそれ以上に達しています。独立報告でも、先行モデルより多くのドキュメントにまたがる情報の保持と統合が大幅に向上していることが確認されています。これはデューデリジェンス、法務サマリー、文献レビュー、コードベース理解などの実務で本当に役立つ前進です。
GPT-5.2 は最大 256,000 トークン(約 200 ページ超のドキュメント)までのコンテキストを処理できます。さらに、「OpenAI MRCRv2」の長文理解テストでは、GPT-5.2 Thinking がほぼ 100% に近い正確度を達成しました。
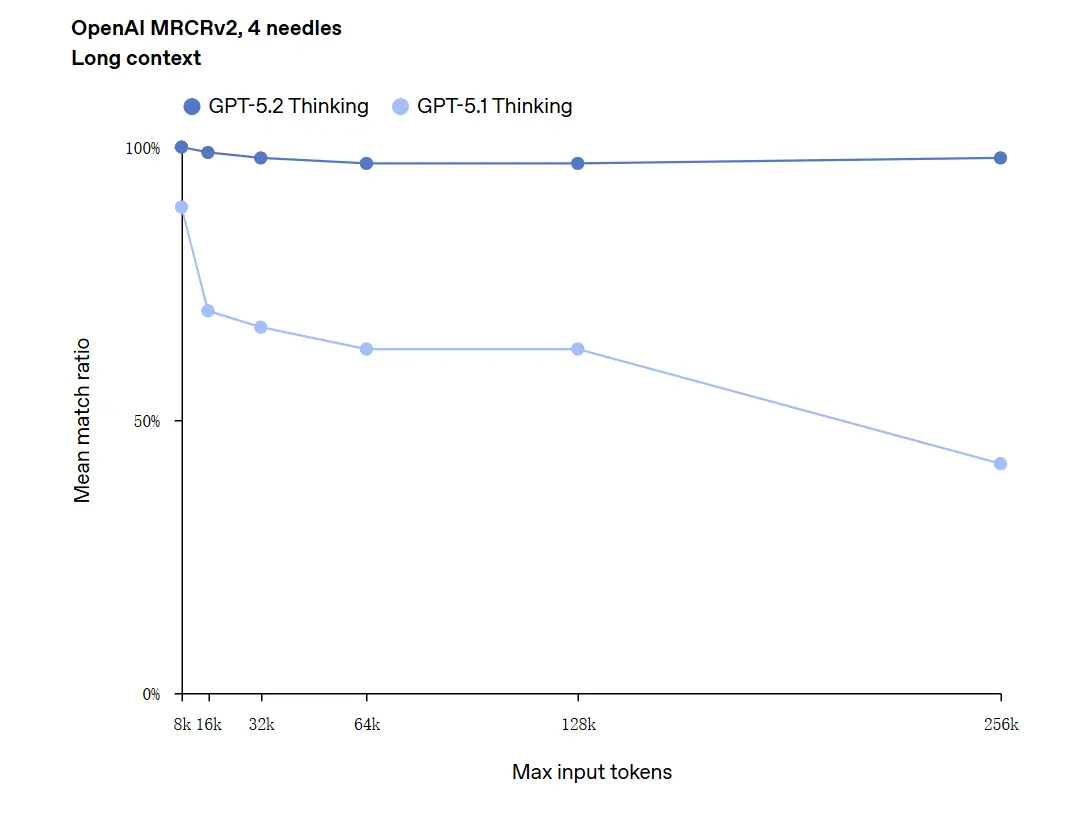
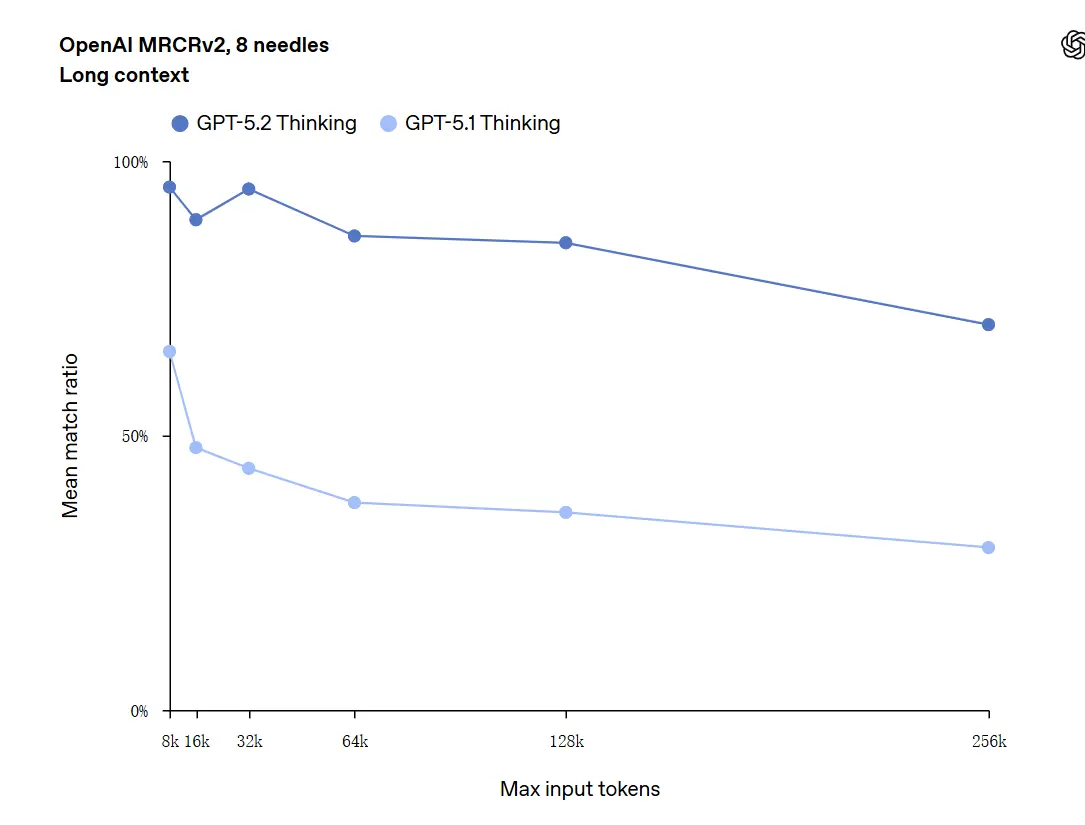
「100% の正確性」についての注意点: 改善は狭いマイクロタスクに対して「100% に近づいている」と表現されました。OpenAI のデータは「評価されたタスクで SOTA、かつ多くの場合に人間の専門家レベルに到達または上回る」と記述するのが適切で、あらゆる用途で文字通り完璧というわけではありません。ベンチマークは大きな向上を示しますが、普遍的な完全性を意味しません。
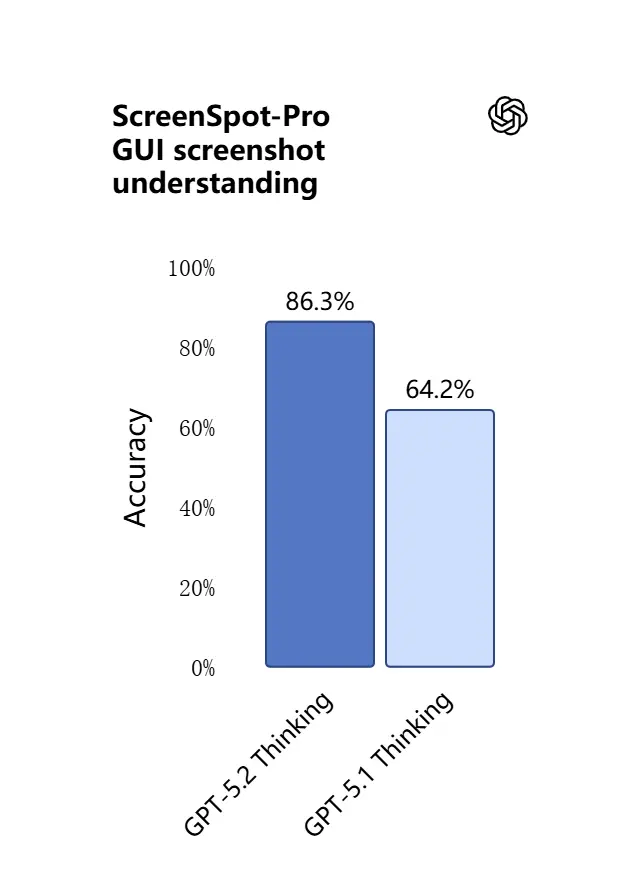
3) 視覚理解とマルチモーダル推論の新機能は?
GPT-5.2 のビジョン機能は、より鋭く実用的になりました。スクリーンショットの解釈、チャートやテーブルの読み取り、UI 要素の認識、そして長いテキスト文脈と視覚入力の結合に長けています。単なるキャプション生成ではなく、GPT-5.2 は画像から構造化データ(例: PDF 内のテーブル)を抽出し、グラフを説明し、図を下流のツール操作に役立つ形で推論できます(例: 写真のレポートからスプレッドシートを生成)。
.webp)
実務上の効果: チームはフルのスライドデッキ、スキャンされた調査レポート、画像の多いドキュメントをそのままモデルに投入し、ドキュメント横断の統合を依頼できます。手作業での抽出作業を大幅に削減します。
4) ツール呼び出しとタスク実行はどう変わったか?
GPT-5.2 はエージェント的挙動をさらに推し進め、マルチステップのタスク計画、外部ツールを呼ぶタイミングの判断、ジョブをエンドツーエンドで完了するための API/ツール呼び出しの連鎖実行が、以前のモデルより確実になりました。「エージェント的ツールコーリング」の改良により、モデルは計画を提案し、ツール(データベース、コンピュート、ファイルシステム、ブラウザ、コードランナー)を呼び、最終成果物へと結果を統合します。API にはルーティングと安全管理(許可ツールのリスト、ツール足場)が導入され、ChatGPT の UI は適切な 5.2 バリアント(Instant と Thinking)に自動ルーティングできます。
GPT-5.2 は Tau2-Bench Telecom ベンチマークで 98.7% を記録し、複雑なマルチターンタスクにおける成熟したツール呼び出し能力を示しました。
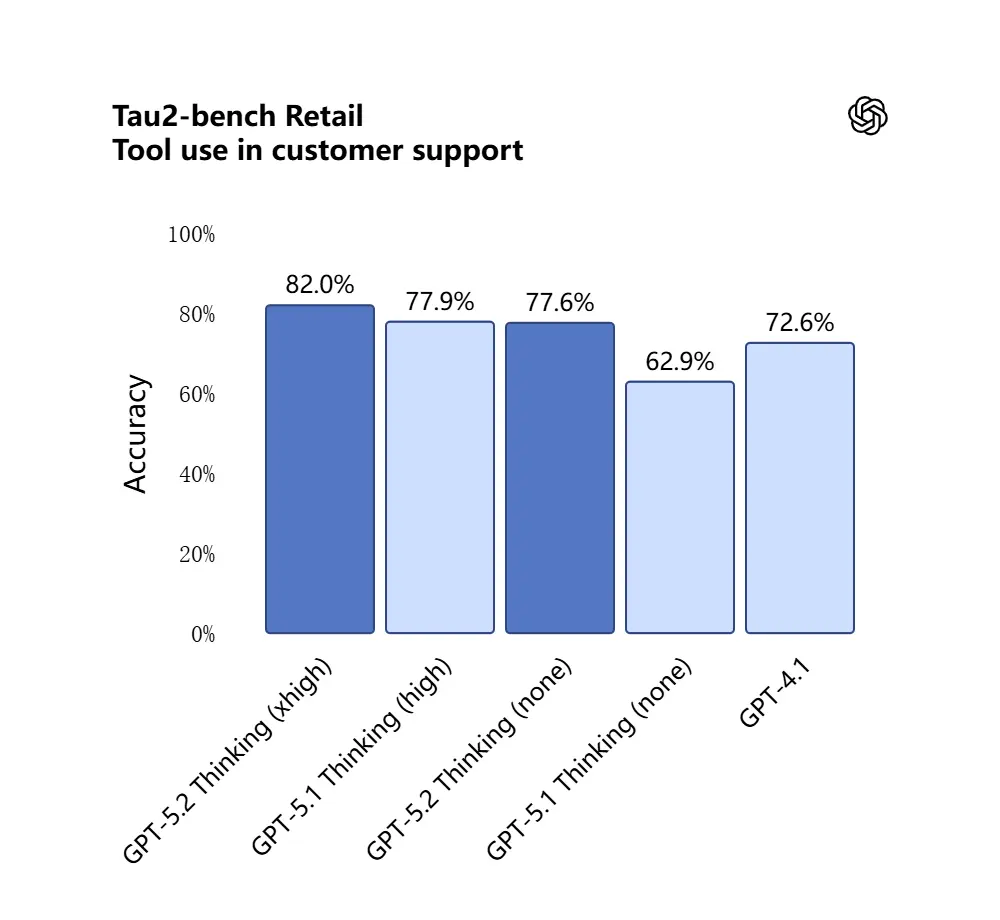
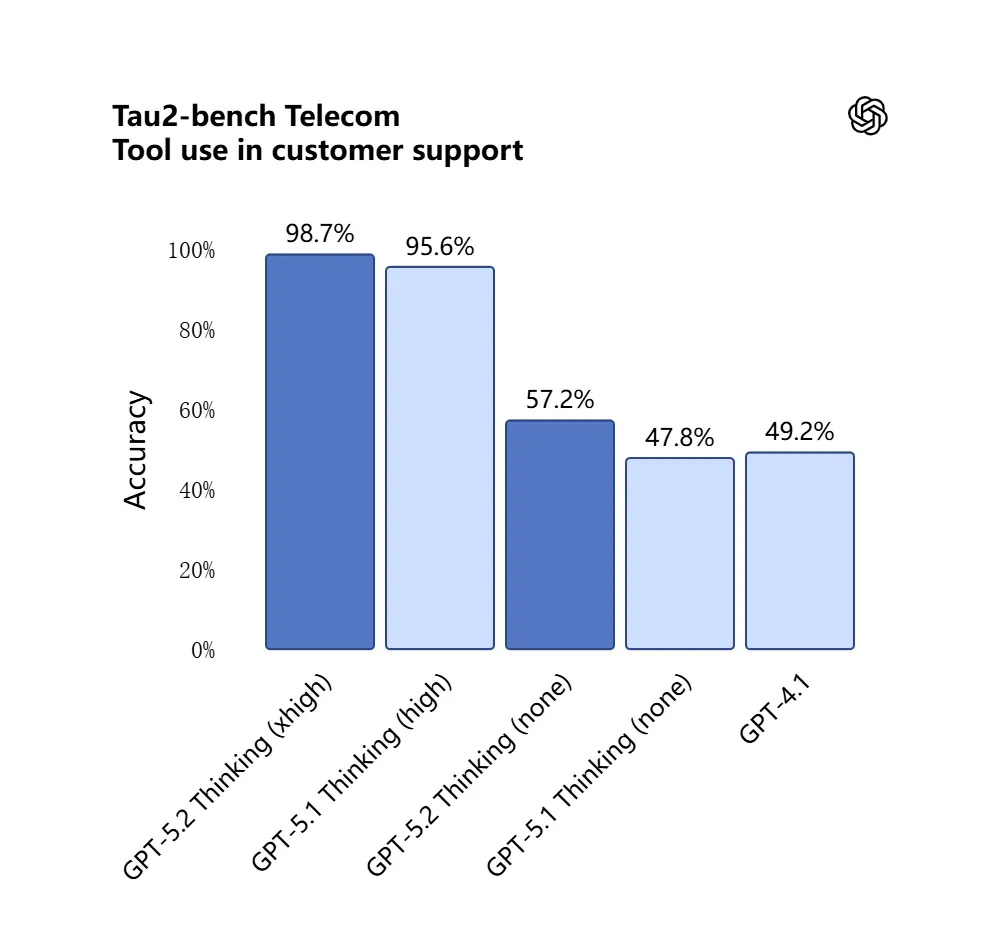
なぜ重要か: これにより、「これらの契約書を取り込み、条項を抽出し、スプレッドシートを更新して、要約メールを書く」といった、以前は綿密なオーケストレーションが必要だったワークフローにおいて、GPT-5.2 が自律アシスタントとしてより有用になります。
5) プログラミング能力の進化
GPT-5.2 はソフトウェアエンジニアリングタスクで顕著に強化されました。より完全なモジュールを書き、テストをより確実に生成・実行し、複雑なプロジェクトの依存関係グラフを理解し、「怠惰なコーディング」(ボイラープレートの省略やモジュールの結線忘れ)に陥りにくくなりました。業界水準のコーディングベンチマーク(SWE-bench Pro など)で GPT-5.2 は新記録を樹立しています。ペアプログラマとして LLM を活用するチームにとって、この改善は生成後の手動検証や手直しを減らします。
SWE-Bench Pro テスト(実世界の産業ソフトウェアエンジニアリングタスク)では、GPT-5.2 Thinking のスコアが 55.6% に向上し、SWE-Bench Verified テストでも新高値の 80% を達成しました。
_Software%20engineering.webp)
実務上の意味合い:
- 本番環境コードの自動デバッグにより、より高い安定性を実現
- 複数言語のプログラミングに対応(Python に限定されない)
- エンドツーエンドの修復タスクを自立的に完了可能
GPT-5.2 と GPT-5.1 の違いは?
短い答え: GPT-5.2 は反復的ながら実質的な改良です。GPT-5 ファミリーのアーキテクチャとマルチモーダルの基盤は維持しつつ、実用的な 4 つの側面で前進しています。
- 推論の深さと一貫性。 5.2 はマルチステップ課題での連鎖を強化し、より高い推論負荷レベルを導入。5.1 でも推論は改善していましたが、5.2 は複雑な数学や多段論理の上限を引き上げます。
- 長文脈での信頼性。 両者とも文脈は拡張されましたが、5.2 は非常に長い入力の奥深くでも正確性を維持するようチューニングされています(OpenAI は数十万トークンまでの保持改善を主張)。
- ビジョン+マルチモーダルの忠実度。 5.2 は画像とテキストの相互参照を改善—例:チャートを読み取り、そのデータをスプレッドシートに統合—し、タスクレベルの精度が向上。
- エージェント的ツール挙動と API 機能。 5.2 は新たな推論負荷パラメータ(
xhigh)やコンテキスト圧縮機能を API に公開し、ChatGPT のルーティングロジックも洗練され、UI が最適なバリアントを自動選択できます。 - エラー減少と安定性向上: GPT-5.2 は「幻覚率」(誤応答率)を 38% 低減。リサーチ、ライティング、分析に対してより信頼性の高い回答を返し、「作られた事実」の発生を減らします。複雑なタスクでは、構造化出力がより明確になり、論理の安定性が増しています。同時に、メンタルヘルス関連タスクでの応答安全性も大きく向上。自傷や自殺、情緒的依存といったセンシティブな場面でも、より堅牢に機能します。
システム評価では、GPT-5.2 Instant は「Mental Health Support」タスクで 0.995(1.0 満点)を記録し、GPT-5.1(0.883)を大きく上回りました。
定量的には、OpenAI が公開したベンチマークで GDPval、数学系(FrontierMath)、ソフトウェアエンジニアリング評価で測定可能な向上が示されています。ジュニア投資銀行業務のスプレッドシートタスクでも、GPT-5.2 は GPT-5.1 を数ポイント上回ります。
GPT-5.2 は無料か—費用はいくらか?
無料で GPT-5.2 を使えるか?
OpenAI は GPT-5.2 を有料の ChatGPT プランと API アクセスから展開開始しました。歴史的に OpenAI は最速/最深のモデルを有料層に留め、軽量バリアントを後に広く提供してきました。5.2 でも、展開は有料プラン(Plus、Pro、Business、Enterprise)から始まり、API は開発者に提供されています。つまり、即時の無料アクセスは限定的で、無料層は後に(軽量サブバリアントへのルーティングなど)段階的にアクセスが提供される可能性があります。
朗報として、CometAPI はすでに GPT-5.2 と統合しており、現在クリスマスセール中です。CometAPI を通じて GPT-5.2 を利用でき、Playground で GPT-5.2 と自由に対話できるほか、開発者は GPT-5.2 の API(CometAPI は OpenAI の 20% の価格)を使ってワークフローを構築できます。
API(開発/本番利用)での費用は?
API の利用はトークン単位で課金されます。ローンチ時に公開された OpenAI プラットフォームの価格は以下の通り(CometAPI は OpenAI の 20% の価格):
- GPT-5.2(standard chat) — 入力 1M トークンあたり $1.75、出力 1M トークンあたり $14(キャッシュ入力には割引適用)
- GPT-5.2 Pro(flagship) — 入力 1M トークンあたり $21、出力 1M トークンあたり $168(高精度・高計算量ワークロード向けのため大幅に高価)
- 参考として、GPT-5.1 はより安価でした(例:入力 $1.25 / 出力 $10/1M トークン)。
解釈: API コストは前世代より上昇。5.2 のプレミアムな推論力と長文脈性能が独立した製品階層として価格に反映されています。本番システムでは、入出力トークン量とキャッシュ入力の再利用頻度(キャッシュ入力は大幅割引)にコストが強く依存します。
実務上の意味
- ChatGPT の UI でのカジュアル利用では、月額サブスク(Plus、Pro、Business、Enterprise)が主要な経路。5.2 リリースに伴う ChatGPT サブスク価格の変更はなく、プラン価格は安定。
- 本番・開発者利用では、トークンコストを見込むべきです。長い応答のストリーミングや長文ドキュメントの処理が多い場合、出力トークンの価格(Thinking で $14/1M トークン)が支配的になりがちで、入力のキャッシュや出力の再利用を慎重に行わない限りコストが増えます。
GPT-5.2 Instant と GPT-5.2 Thinking と GPT-5.2 Pro の違い
OpenAI は用途に合わせて Instant、Thinking、Pro の 3 つの目的別バリアントで GPT-5.2 を提供しました。
- GPT-5.2 Instant: 高速・コスト効率重視。FAQ、ハウツー、翻訳、下書き作成など日常業務向け。低レイテンシで、シンプルなワークフローや初稿に適します。
- GPT-5.2 Thinking: 長文サマリー、マルチステップ計画、詳細なコードレビューなど持続的な作業における高品質な応答。レイテンシと品質のバランスが良く、プロフェッショナルタスクの既定の「主力」。
- GPT-5.2 Pro: 最高品質と信頼性。遅く高価だが、難易度が高くリスクの大きいタスク(複雑なエンジニアリング、法的統合、高付加価値の意思決定)や
xhighの推論負荷が必要な場面に最適。
比較表
| 機能 / 指標 | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| 想定用途 | 日常タスク、迅速な下書き | 深い分析、長文ドキュメント | 最高品質、複雑な問題 |
| レイテンシ | 最低 | 中程度 | 最高 |
| 推論負荷 | Standard | High | xHigh available |
| 最適な用途 | FAQ、チュートリアル、翻訳、短いプロンプト | サマリー、計画、スプレッドシート、コーディングタスク | 複雑なエンジニアリング、法的統合、リサーチ |
| API 名の例 | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| 入力トークン価格(API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| 出力トークン価格(API) | $14 / 1M | $14 / 1M | $168 / 1M |
| ChatGPT での提供状況 | 段階展開;有料プランから順次 | 有料プランへ展開 | Pro ユーザー / Enterprise(有料) |
| 典型ユースケース例 | メール下書き、小さなコード片 | 複数シートの財務モデル構築、長文レポート Q&A | コードベース監査、本番級のシステム設計の生成 |
誰が GPT-5.2 を使うべきか?
GPT-5.2 は幅広いユーザーを想定して設計されています。以下は役割別の推奨です。
企業・プロダクトチーム
知識労働向けのプロダクト(リサーチアシスタント、契約審査、分析パイプライン、開発者ツール)を構築する場合、GPT-5.2 の長文脈・エージェント機能により統合の複雑さを大きく削減できます。堅牢なドキュメント理解、自動レポーティング、インテリジェントなコパイロットを必要とする企業は Thinking/Pro を有用と感じるでしょう。Microsoft をはじめとするプラットフォームパートナーは、すでに 5.2 をプロダクティビティスタック(例:Microsoft 365 Copilot)に統合しつつあります。
開発者・エンジニアリングチーム
LLM をペアプログラマとして使ったり、コード生成/テストの自動化を進めたいチームは、5.2 のプログラミング忠実度向上の恩恵を受けます。API アクセス(thinking や pro モード)により、400k トークンのコンテキストウィンドウを活かして巨大なコードベースのより深い統合が可能です。Pro を使う場合 API コストは増えますが、手動デバッグやレビュー削減が複雑なシステムでは費用対効果をもたらす可能性があります。
研究者・データ志向のアナリスト
文献を継続的に統合し、長い技術報告書を解析し、実験設計をモデル支援したい場合、GPT-5.2 の長文脈と数学の改善はワークフローを加速します。再現可能な研究のためには、慎重なプロンプト設計と検証ステップを組み合わせると良いでしょう。
中小企業・パワーユーザー
ChatGPT Plus(およびパワーユーザー向けの Pro)では 5.2 バリアントへのルーティングアクセスが得られます。これにより、API 連携を構築せずとも、高度な自動化と高品質な出力を小規模チームが利用可能になります。非技術ユーザーでも、ドキュメント要約やスライド作成の品質向上を実感できます。
開発者・運用者向けの実務メモ
注目すべき API 機能
reasoning.effortレベル(例:medium、high、xhigh)で、内部推論に費やす計算量を指定可能。要求ごとにレイテンシと正確性のトレードオフを調整できます。- コンテキスト圧縮: 本当に関連する内容を保持するために履歴を圧縮・簡約化するツールが API に含まれます。長い連鎖で有効トークン使用量を管理するのに不可欠。
- ツール足場 & 許可ツール制御: 本番システムでは、モデルが呼び出せるツールを明示的にホワイトリスト化し、ツール呼び出しを監査ログに記録すべきです。
コスト管理のコツ
- 頻繁に使うドキュメントの埋め込みをキャッシュし、同一コーパスへの繰り返しクエリにはキャッシュ入力(大幅割引)を活用。OpenAI のプラットフォーム価格にはキャッシュ入力への大きな割引が含まれます。
- 試行・低価値の問い合わせは Instant にルーティングし、バッチジョブや最終パスには Thinking/Pro を使う。
- API コスト見積もりでは入出力トークンを厳密に見積もる。長い出力はコストを乗算的に増やします。
結論 — GPT-5.2 にアップグレードすべきか?
長文ドキュメントでの推論、ドキュメント横断の統合、マルチモーダル解釈(画像 + テキスト)、ツールを呼び出すエージェント構築に依存する業務であれば、GPT-5.2 は明確なアップグレードです。実用的な正確性が上がり、統合の手間が減ります。一方で、高ボリューム・低レイテンシのチャットボットや厳しい予算制約の用途では、Instant(や従来モデル)が依然として妥当な選択となる場合があります。
GPT-5.2 は「より良いチャット」から「より良いプロフェッショナルアシスタント」への意図的なシフトを体現しています。より多くの計算、より高い能力、より高い価格帯—しかし、信頼できる長文脈、改良された数学/推論、画像理解、エージェント的ツール実行を活用できるチームにとっては、実際の生産性向上をもたらします。
始めるには、Playground で GPT-5.2 モデル(GPT-5.2;GPT-5.2 pro, GPT-5.2 chat )の機能を試し、詳細は API guide を参照してください。アクセス前に、CometAPI にログインし API キーを取得していることを確認してください。CometAPI は公式価格より大幅に安い価格を提供しており、統合を支援します。
Ready to Go?→ Free trial of gpt-5.2 models !