

「コスト度外視のスケール至上主義」が支配する状況――Flux.2 や Hunyuan-Image-3.0 のようなモデルがパラメータ数を30B〜80Bという巨大レンジへ押し上げる中――現状を揺さぶる新たな挑戦者が登場した。Z-Image は Alibaba の Tongyi Lab によって開発され、正式にローンチ。一般向けハードウェアで動作しながら、わずか6Bの軽量アーキテクチャで業界大手に匹敵する出力品質を実現し、期待を打ち破った。
2025年末にリリースされた Z-Image(超高速変種の Z-Image-Turbo を含む)は、公開から24時間で500,000ダウンロードを突破し、瞬く間にAIコミュニティを魅了した。わずか8推論ステップでフォトリアリスティックな画像を生成する Z-Image は、単なる新モデルではなく、競合では動作が困難なノートPCでも高忠実度の生成を可能にする、生成AIの民主化を推進する存在だ。
Z-Imageとは?
Z-Image は、Tongyi-MAI / Alibaba Tongyi Lab の研究チームが開発した、オープンソースの新しい画像生成基盤モデル。テキストトークン、視覚セマンティックトークン、VAEトークンを単一の処理ストリームに連結する新規の**Scalable Single-Stream Diffusion Transformer(S3-DiT)**アーキテクチャ上に構築された、6Bパラメータの生成モデルだ。設計目標は明確で、トップクラスのフォトリアリズムと指示遵守性を提供しつつ、推論コストを大幅に削減し、一般向けハードウェアでの実用を可能にすること。Z-Image プロジェクトは、コード、モデル重み、オンラインデモを Apache-2.0 ライセンスで公開している。
Z-Image には複数のバリアントが用意されている。最も広く議論されるリリースは、デプロイ向けに最適化された少ステップ蒸留版の Z-Image-Turbo。加えて、非蒸留の Z-Image-Base(ファウンデーションチェックポイント、ファインチューニングに適)や Z-Image-Edit(画像編集向けの指示チューニング版)もある。
“Turbo”の優位性:8ステップ推論
フラッグシップである Z-Image-Turbo は、Decoupled-DMD(Distribution Matching Distillation) と呼ばれる進行的蒸留手法を用いる。これにより、世代プロセスを標準的な30〜50ステップから、わずか8ステップへ圧縮できる。
結果: 企業向けGPU(H800)でサブ秒、コンシューマ向けカード(RTX 4090)でも実質リアルタイムの生成を達成。他のターボ/ライトニング系で見られがちな「プラスチック感」や「色褪せ」を伴わない。
Z-Imageの4つの主要機能
Z-Image は技術開発者とクリエイティブ双方に訴求する機能を備えている。
1. 比類ないフォトリアリズムと美学
6Bパラメータにもかかわらず、Z-Image は驚くほどクリアな画像を生成する。以下に秀でる:
- 肌の質感: 人物の毛穴や微細な欠点、自然なライティングの再現
- 素材の物理: ガラス、金属、布のテクスチャの正確な描写
- ライティング: SDXL と比較して優れたシネマティック/ボリューメトリックライティングの扱い
2. 英中ネイティブのテキストレンダリング
AI画像生成における大きな課題だったテキスト描画を、Z-Image は英語と中国語の双方でネイティブにサポート。
- 複雑なポスター、ロゴ、看板などを、両言語で正しいスペリングと書体で生成可能。西洋中心のモデルでは欠けがちな機能だ。
3. Z-Image-Edit:指示ベースの編集
ベースモデルと併せて、Z-Image-Edit がリリースされている。このバリアントは画像から画像タスク向けにファインチューニングされ、自然言語による指示(例:「その人を笑顔にして」「背景を雪山に変えて」)で既存画像を修正できる。変換中もアイデンティティやライティングの整合性を高く維持する。
4. コンシューマ向けハードウェアでのアクセシビリティ
- VRAM効率: 6GB VRAM(量子化)〜16GB VRAM(フル精度)で快適に動作
- ローカル実行: ComfyUI と
diffusersによるローカルデプロイに完全対応し、クラウド依存から解放
Z-Imageの仕組み
Single-stream diffusion transformer(S3-DiT)
Z-Image は従来の二重ストリーム設計(テキストと画像のエンコーダ/ストリームを分離)から離れ、テキストトークン、画像VAEトークン、視覚セマンティックトークンを単一のトランスフォーマ入力へ連結する。この単一ストリーム手法は、パラメータ利用を改善し、トランスフォーマのバックボーン内でのクロスモーダル整合を簡素化する。著者らによれば、これが6Bモデルにおいて好ましい効率/品質のトレードオフにつながるという。
Decoupled-DMD と DMDR(蒸留+RL)
通常の品質低下なしに少ステップ(8ステップ)生成を可能にするため、チームはDecoupled-DMD 蒸留アプローチを開発。CFG(classifier-free guidance)の拡張と分布整合を切り離し、それぞれを独立に最適化できるようにした。さらに、ポストトレーニングの強化学習ステップ(DMDR)を適用し、セマンティック整合性と美学を洗練。これらを組み合わせることで、一般的な拡散モデルよりもはるかに少ない NFE で、リアリズムを維持した Z-Image-Turbo を実現した。
学習スループットとコスト最適化
Z-Image はライフサイクル最適化アプローチで学習された。キュレートされたデータパイプライン、精選されたカリキュラム、効率重視の実装選択を採用。著者らは、学習ワークフロー全体を約**314K H800 GPU hours(≈ USD $630K)**で完了したと報告しており、20B超の巨大モデルと比べてコスト効率に優れる再現可能なエンジニアリング指標だ。
Z-Imageモデルのベンチマーク結果
Z-Image-Turbo は複数の最新リーダーボードで高順位を獲得。Artificial Analysis Text-to-Image リーダーボードでオープンソース上位の評価を受け、Alibaba AI Arena の人間選好評価でも強いパフォーマンスを示した。
ただし、実運用での品質はプロンプト設計、解像度、アップスケーリングのパイプライン、追加の後処理にも依存する。
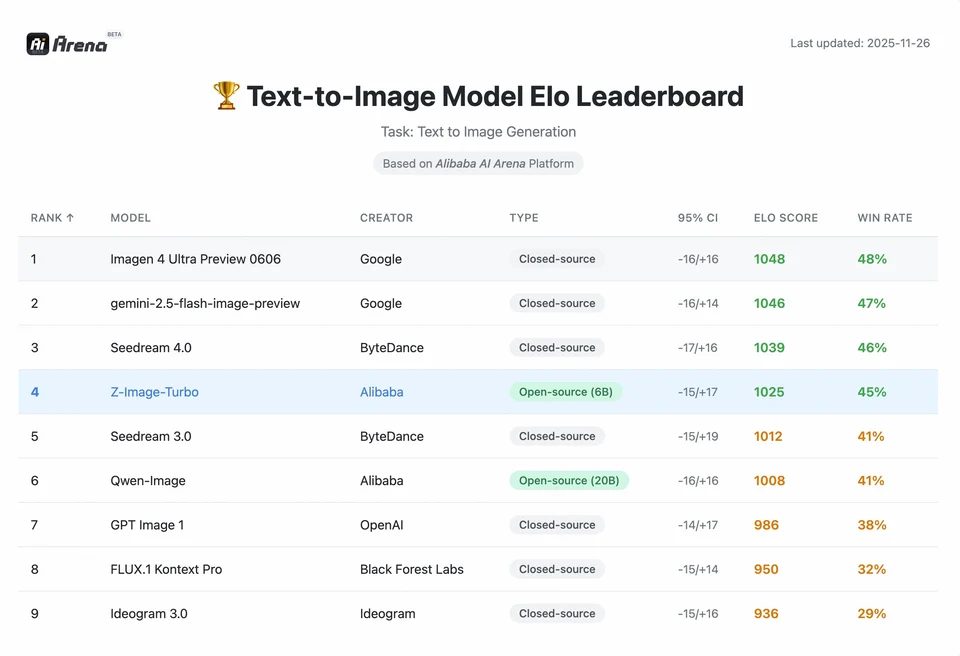
Z-Image の成果の大きさを理解するには、データを見るのが手っ取り早い。以下は、主要なオープンソース/プロプライエタリモデルと Z-Image の比較分析だ。
比較ベンチマーク概要
| 機能 / 指標 | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| アーキテクチャ | S3-DiT(単一ストリーム) | MM-DiT(デュアルストリーム) | U-Net | 拡散トランスフォーマー |
| パラメータ数 | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| 推論ステップ | 8 Steps | 25 - 50 Steps | 1 - 4 Steps | 30 - 50 Steps |
| 必要VRAM | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| テキストレンダリング | 高(EN + CN) | 高(EN) | 中(EN) | 高(CN + EN) |
| 生成速度(4090) | ~1.5 - 3.0 Seconds | ~15 - 30 Seconds | ~0.5 Seconds | ~20 Seconds |
| フォトリアリズム評価 | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| ライセンス | Apache 2.0 | 非商用(Dev) | OpenRAIL | カスタム |
データ分析とパフォーマンス考察
- 速度 vs 品質: SDXL Turbo は(1ステップで)高速だが、複雑なプロンプトでは品質が大きく低下しがち。Z-Image-Turbo は8ステップで「甘美なバランス」を達成し、Flux.2 に匹敵する品質を保ちつつ5〜10倍高速。
- ハードウェアの民主化: Flux.2 は強力だが、現実的なパフォーマンスのためには24GB VRAM(RTX 3090/4090)以上が事実上の前提。Z-Image はミドルレンジのカード(RTX 3060/4060)でも、1024x1024のプロ向け画像をローカル生成できる。
開発者はZ-Imageにどうアクセスして使う?
一般的なアプローチは3つ:
- ホスト型 / SaaS(Web UI または API): z-image.ai のようなサービスや、モデルをデプロイし Webインターフェースや有料APIで画像生成を提供するプロバイダを利用。ローカルセットアップなしで試す最速の方法。
- Hugging Face + diffusers パイプライン: Hugging Face の
diffusersライブラリにはZImagePipelineとZImageImg2ImgPipelineが含まれ、一般的なfrom_pretrained(...).to("cuda")ワークフローを提供。再現性ある例を求める Python 開発者に推奨。 - GitHub リポジトリからのローカルネイティブ推論: Tongyi-MAI のリポジトリには、ネイティブ推論スクリプト、最適化オプション(FlashAttention、コンパイル、CPUオフロード)、最新統合のために
diffusersをソースからインストールする手順が含まれる。フルコントロールを望む研究者や、カスタム学習/ファインチューニングを実行したいチームに有用。
最小のPython例はどのようなもの?
以下は、Hugging Face diffusers を用いて Z-Image-Turbo でテキストから画像生成を行う簡潔な Python スニペット。
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
注: guidance_scale のデフォルト値や推奨設定は Turbo モデルで異なる場合がある。ターゲット挙動に応じて、ガイダンスは低めまたはゼロに設定されることが文書で示唆されている。
Z-Imageで画像から画像(編集)を実行するには?
ZImageImg2ImgPipeline は画像編集をサポート。例:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
これは公式の使用パターンに近く、クリエイティブな編集やインペインティングに適している。
プロンプトとガイダンスの扱い方
- 構造を明示する: 複雑なシーンでは、シーン構成、主被写体、カメラ/レンズ、ライティング、ムード、テキスト要素を含めるようにプロンプトを構成する。Z-Image は詳細なプロンプトから恩恵を受け、位置指定/ナラティブのキューも扱える。
guidance_scaleを丁寧に調整: ターボ系モデルでは低いガイダンス値が推奨される場合がある。試行が必要。多くのターボワークフローでは、guidance_scale=0.0–1.0と固定ステップ、シードの組み合わせで一貫した結果が得られる。- 画像から画像で制御された編集: 構図を保持しつつスタイル/彩色/オブジェクトを変えたい場合は、初期画像から開始し、
strengthで変化量を制御する。
最適なユースケースとベストプラクティス
1. 迅速なプロトタイピング&絵コンテ作成
ユースケース: 映画監督やゲームデザイナーが、瞬時にシーンを可視化したい。
なぜ Z-Image? 3秒未満の生成で、クリエイターは1セッション内に何百ものコンセプトを反復可能。レンダリングを待つことなく、ライティングと構図をリアルタイムで洗練できる。
2. Eコマース&広告
ユースケース: 商品の背景やライフスタイルショットを生成する。
ベストプラクティス: Z-Image-Edit を使用。
生の商品写真をアップロードし、「この香水ボトルを日差しの差す庭の木製テーブルに置いて」 のような指示プロンプトを使う。モデルは商品の整合性を保ちながら、フォトリアリスティックな背景を仮想的に生成する。
3. バイリンガルなコンテンツ制作
ユースケース: 西洋市場とアジア市場の双方に向けたキャンペーン素材が必要。
ベストプラクティス: テキストレンダリング機能を活用。
- プロンプト: 「暗い路地で『OPEN』と『营业中』が光るネオン看板」
- Z-Image は英語と中国語の文字を正しくレンダリングでき、他の多くのモデルでは困難な機能を実現する。
4. 低リソース環境
ユースケース: エッジデバイスや一般的なオフィス向けノートPCでのAI生成。
最適化のヒント: INT8 量子化版 を使用。品質の損失をほぼ伴わずに VRAM 使用量を6GB未満へ削減でき、非ゲーミングノートのローカルアプリでも現実的になる。
結論:Z-Imageを使うべき人
Z-Image は、高品質なフォトリアリズムを実用的なレイテンシとコストで求め、オープンなライセンスやオンプレミス/カスタムホスティングを好む組織・開発者向けに設計されている。クリエイティブツール、製品モックアップ、リアルタイムサービスなどで高速な反復が必要なチーム、そしてコンパクトながら強力な画像モデルのファインチューニングに関心がある研究者/コミュニティにもとりわけ魅力的だ。
CometAPI は、制限が比較的少ない Grok Image モデルや、Nano Banana Pro、GPT- image 1.5、Sora 2(Can Sora 2 generate NSFW content? How can we try it?)などのモデルも提供しており、適切なNSFWのティップスとトリックがあれば、制限を回避して自由に作成を開始できる。アクセス前に、CometAPI にログインして API キーを取得していることを必ず確認してほしい。CometAPI は公式価格より大幅に低い価格を提供し、統合を支援する。
Ready to Go?→ Free trial for Creating !