
.webp&w=3840&q=75)
GLM-5.1 ЖИ кеңістігіндегі бетбұрыс сәтті білдіреді. Қытайлық ЖИ компаниялары коммерциялануды жеделдетіп, алдыңғы қатарлы мүмкіндіктерді ашық етуде, бұл модель OpenAI-дің GPT-5.4, Anthropic-тің Claude Opus 4.6 және Google-дың Gemini 3.1 Pro сияқты меншікті көшбасшыларымен, әсіресе нақты әлемдегі бағдарламалық инженерияда, арақашықтықты қысқартады. GLM-5-пен бірдей 744B-параметрлі MoE архитектурасында оқытылғанымен, агенттік жұмыс ағындарына қатты оңтайландырылған, ол көптеген LLM-дер сүрінетін жерде озады: мыңдаған құрал шақырулары барысында жоспарлау, эксперимент жүргізу, дебагтау және өзін-өзі түзетуді қажет ететін ұзақ, екіұшты, итеративті тапсырмалар.
Енді CometAPI GLM-5.1 мен GLM-5-ті біріктірді, ал әзірлеушілер басқа да Батыстың үздік модельдерін көріп, оларды өте төмен API бағасымен пайдалана алады (бұл да CometAPI-дің өзге бәсекелестерге қарағандағы артықшылығы).
GLM-5.1 дегеніміз не?
GLM-5.1 — Z.ai компаниясының ең жаңа флагман тілдік моделі және компанияның ұзақ мерзімді, агент-стильді софт әзірлеуге бағытталған соңғы қадамы. Z.ai-дың өз сөздерімен айтқанда, ол бір реттік жауаптан гөрі үздіксіз орындалуды қажет ететін тапсырмаларға арналған және бір ұзартылған іске қосылу аясында жоспарлайтын, орындайтын, жетілдіретін және жеткізетін модель ретінде позицияланады. Z.ai-дың релиз ескертпелерінде GLM-5.1 көп-кезеңді қадағаланатын ұсақ баптау, нығайтпалы оқыту және үдеріс сапасын бағалау қаңқасы арқылы құрастырылғаны, сондай-ақ ұзақ тапсырмалар бойы тұрақтылық, бірізділік және құралдарды қолдануды жақсартқаны айтылған.
Бұл позиция маңызды, себебі GLM-5.1 жай ғана «тағы бір чат моделі» ретінде сатылмайды. Ол мақсатты есте сақтап, аралық қадамдарды атқарып, тақырыптан жаңылмай қателерден қалпына келуі керек инженерлік жұмыс ағымдарына бағытталған; автономды жоспарлау, үздіксіз орындау, багтарды түзету және стратегияны итерациялау үшін арналған — бұл жай әңгімелесетін көмекші не қысқа-контексті код-коэкпилоттан мүлде басқа өнім тарихы.
Пайдалы практикалық деталь: GLM-5.1 тек мәтінмен жұмыс істейді, GLM Coding Plan-да қолдау бар және Claude Code пен OpenClaw сияқты танымал кодтау агенттерінде пайдалануға болады, бұл модельді бар әзірлеуші жұмыс ағымына кірістіруді қалайтын командалар үшін ерекше өзекті етеді, оны алмастырудың қажеті жоқ.
Негізгі техникалық сипаттамалар (GLM-5-тен мұраланған және жетілдірілген):
- Архитектура: Mixture-of-Experts (MoE), жалпы 744 млрд параметр, бір инференс кезінде шамамен 40 млрд белсенді параметр.
- Контекст терезесі: 203K–204.8K токен (шығыста 131K токенге дейін қолдау).
- Негізгі жетілдірулер: Ұзын контексті тиімді өңдеу және орналастыру құнын азайту үшін DeepSeek Sparse Attention (DSA); пост-оқытуды тиімдірек ету мақсатында жетілдірілген асинхронды нығайтпалы оқыту инфрақұрылымы (Z.ai-дың “slime” қаңқасы арқылы).
- Қолжетімділік: Ашық салмақтар (MIT лицензиясы бойынша Hugging Face-та zai-org/GLM-5.1), Z.ai платформасы мен CometAPI сияқты агрегаторлар арқылы API қолжетімділігі, сондай-ақ GLM Coding Plan құралдарына интеграция (Claude Code / OpenClaw үйлесімді).
Жалпы интеллект пен қысқа «vibe coding»-ке көбірек бағытталған ертеректегі GLM модельдерінен айырмашылығы, GLM-5.1 мақсатты түрде өндірістік деңгейдегі автономды агенттерге бағытталған. Ол адам араласуынсыз сағаттар бойы күрделі инженерлік жобаларды тәуелсіз жоспарлап, орындап, бенчмарк жасап, дебагтап, итерациялай алады — бұл оны Anthropic пен OpenAI-дың маманданған кодтау агенттеріне тікелей бәсекелес қылады.
Релиз шамамен ~10% API бағасының өсуімен (кіріс токендері ~$0.54/M, шығыс ~$4.40/M) тұспа-тұс келді, дегенмен бұл Anthropic-тің Opus 4.6 баламаларынан әлдеқайда арзан болып қала береді (250–470% қымбатырақ).
GLM-5.1 бенчмарк көрсеткіштері
Z.ai GLM-5.1-ді әлемдегі ең мықты ашық бастапқы модель және агенттік кодтауда жаһандық топ-3 көрсеткішті модель ретінде позициялайды. Өнімділік деректері SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 және тапсырыс бойынша ұзақ мерзімді сценарийлердегі ресми бағалаулардан алынған.
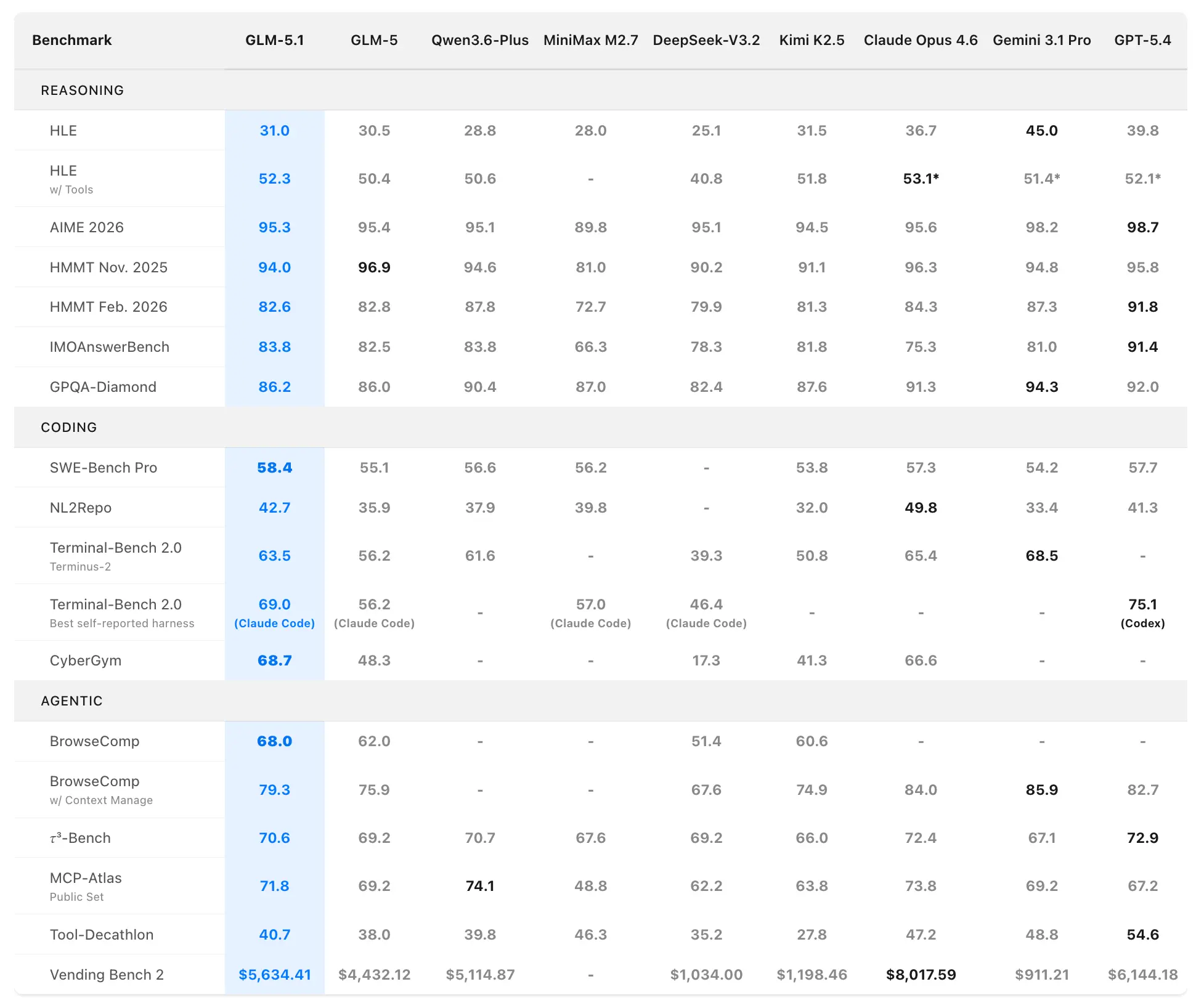
Кодтау және агенттік бенчмарктер
SWE-Bench Pro (репозиторийде шарлау, кодқа өзгеріс енгізу және функционалдық тексеруді талап ететін реалистік софт-инженерлік тапсырмалар):
- GLM-5.1: 58.4 (жаңа state-of-the-art)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 — осы қатаң бенчмаркте бірінші орынға шыққан алғашқы отандық (қытайлық) әрі ашық модель, ол кәсіби әзірлеушілердің жұмыс ағымдарын барынша шынайы бейнелейді.
NL2Repo (табиғи тілден толық репозиторий генерациясы):
- GLM-5.1: 42.7 (GLM-5-тің 35.9 нәтижесінен айқын алда)
- Бәсекелес модельдер 32.0–49.8 диапазонында (көшбасшылар harness-қа қарай өзгереді).
Terminal-Bench 2.0 (нақты терминал және жүйелік тапсырмалар):
- Terminus-2 harness: GLM-5.1 63.5 (GLM-5: 56.2)
- Ең жақсы өзіндік есеп (Claude Code): 69.0-ге дейін.
Бөлек кодтау harness бағалауында (Claude Code стилінде) GLM-5.1 45.3 ұпайға жетті — бұл Claude Opus 4.6-ның 47.9 ұпайының 94.6%, әрі GLM-5-тің 35.4 ұпайынан 28% жақсару.
Құрама рейтинг: SWE-Bench Pro + NL2Repo + Terminal-Bench бойынша #1 ашық бастапқы, #1 қытайлық модель, жаһандық #3.
Ұзақ мерзімді тапсырмалардағы өнімділік: Нақты айырмашылық
Стандартты бенчмарктер бір реттік немесе қысқа-сессиялық өнімділікті өлшейді. GLM-5.1 ұзартылған автономды іске қосылуларда жарқырайды:
- VectorDBBench Optimization (600+ итерация, 6,000+ құрал шақыру): Rust қаңқасынан бастап, GLM-5.1 индексті, қысуды, бағыттауды және қырқуды итеративті қайта жобалап, 21.5k QPS-ке (Claude Opus 4.6-ның 50-бұрылысқа дейінгі бұрынғы үздік 3,547 QPS нәтижесінен 6× жоғары) жетті және SIFT-1M дерегінде ≥95% recall сақтады. Ол әр 100–200 итерацияда құрылымдық серпілістермен “сатылап” ілгерілеуді көрсетті.
- KernelBench Level 3 (толық ML моделі оптимизациясы, 1,000+ бұрылыс): 50 күрделі мәселе бойынша геометриялық орташа жеделдету 3.6× (torch.compile max-autotune-ның 1.49× нәтижесінен жоғары). GLM-5 тоқырауға ұшырағаннан кейін де GLM-5.1 жақсаруды жалғастырды; тек Claude Opus 4.6 4.2× нәтижемен аздап озды.
- Linux Desktop Web App Build (8+ сағат, ашық ұшталған): Табиғи тілдегі промпт қана беріліп, бастапқы кодсыз, GLM-5.1 өз бетімен функционалды Linux-стильді жұмыс үстелі ортасын — тапсырмалар жолағы, терезелер, интеракциялар және полишпен — құра алды; ал бұрынғы модельдер тек қарапайым қаңқалар шығарған.
Бұл нәтижелер GLM-5.1-дің өте ұзақ көкжиектерде тұтастықты сақтап, өзін-өзі бағалап, стратегияны қайта қарап, жергілікті оптимумнан шығу қабілетін көрсетеді — мұны Z.ai нақты өмірдегі агенттік жүйелер үшін әдейі инженериялады.
GLM-5.1 GLM-5-тен несімен өзгеше?
GLM-5 пен GLM-5.1 тығыз байланысқанымен, позициялануы бөлек. GLM-5 — Z.AI-дың Agentic Engineering үшін бұрынғы іргетас моделі. Ол күрделі жүйелік инженерия мен ұзақ ауқымды агент тапсырмаларына арналған, ашық-салмақ SOTA кодтау және агенттік қабілетке ие, әрі нақты бағдарламалау сценарийлерінде Claude Opus 4.5 көрсеткішіне жақындайды. Ол SWE-bench Verified бойынша 77.8, Terminal Bench 2.0 бойынша 56.2 ұпай жинайды.
Ал GLM-5.1 ұзақ мерзімді тапсырмаларға және сенімді, үздіксіз орындалуға келесі қадам ретінде ұсынылады, ұзақ тапсырмаларда тұрақтылықты, бірізділікті және құралдарды қолдануды жақсартады және жалпы алғанда Claude Opus 4.6-пен жақсырақ үйлеседі. Яғни, GLM-5 — инженерияға бағдарланған ертеректегі іргетас модель болса, GLM-5.1 — тапсырмаға төзімділігі жоғары флагман.
Сондай-ақ GLM-5 буынында секірісті түсіндіретін архитектуралық және оқыту айырмашылықтары бар. GLM-5 355B параметрден (32B активтелген) 744B параметрге (40B активтелген) дейін кеңейді, алдын-ала оқыту дерегі 23T-ден 28.5T-ге артты, асинхронды нығайтпалы оқыту қаңқасын қосты және тиімділікті арттыра отырып, ұзын мәтіндегі сапаны сақтау үшін DeepSeek Sparse Attention-ды енгізді. Бұл бөлшектер GLM-5-ке қатысты, алайда GLM-5.1 сол негіздің үстіне тұрғызылғаны байқалады.
GLM-5.1 vs өзге шектегі модельдер
GLM-5.1 — ең мықты ашық бастапқы үміткер ретінде ерекшеленіп, баға/өнімділік бойынша тартымды.
Салыстыру кестесі: Негізгі кодтау және агенттік бенчмарктер (2026 жылғы сәуір)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness Score | Long-Horizon Sustained? | Open-Source? | Approx. API Price (Input/Output per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% of Opus) | Yes (600+ iter, 8 hrs) | Yes | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limited | Yes | Lower (pre-hike) |
| GPT-5.4 | 57.7 | — | — | — | Strong | No | Higher |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Strongest | No | ~250–470% more expensive |
| Gemini 3.1 Pro | 54.2 | — | — | — | Good | No | Higher |
Қорытынды: GLM-5.1 ашықтық, құн және ұзақ мерзімді кодтау метрикаларында жеңеді. Ол агенттік сценарийлерде жабық көшбасшылармен тең деңгейде тайталасып, озық мүмкіндіктерді демократияландырады.
GLM-5.1 қолдану сценарийлері
1) Автономды софт-инженеринг
Тапсырма шынайы инженерлік спринтке ұқсаса, GLM-5.1 өте әсерлі: код базасын оқу, өзгерісті жоспарлау, жүзеге асыру, тестілеу, регрессияларды түзету және нәтиже тұрақтанғанша итерациялау. Z.ai релиз жазбалары автономды жоспарлау, үздіксіз орындалу, багтарды түзету және стратегия итерациясына айрықша мән береді — бұл модельді кодтау агенттері мен софт жеткізу конвейерлері үшін арнайы жасалғандай етеді.
2) Ұзаққа созылатын агент жұмыс ағымдары
Егер сіздің қолдану жағдайыңыз көптеген құрал шақыруды, көпқадамды ұзын жұмыс ағымдарын немесе қайталанатын өзін-өзі түзетуді қамтыса, GLM-5.1-дің дизайны жақсы сәйкестік береді. Құжаттама құрал шақыру, құрылымдалған шығыс, MCP интеграциясы және tool-streaming қолдауын атап өтеді — мұның барлығы модель жай жауап бермей, үлкенірек жүйе ішінде әрекет еткенде пайдалы.
3) Кәсіпорындық білім жұмысы және есеп беру
GLM-5.1 PowerPoint, Word, PDF және Excel сияқты кеңсе өнімділігі тапсырмаларына да бағытталған. Z.ai күрделі контентті ұйымдастыруды, макет дизайнын, құрылымдалған шығысты және визуалды полишті жақсартатынын айтады, бұл оны есептер, оқу материалдары, зерттеу түйіндемелері және басқа да құжат-ауқымды жұмыстар үшін қисынды таңдау етеді.
4) Фронтенд прототиптеу және артефакттар
Z.ai GLM-5.1-ді веб-сайт генерациясы, интерактивті беттер және фронтенд прототиптеу үшін жақсы сәйкес келеді дейді — аз шаблондық құрылым және тапсырманы орындау сапасы жоғарырақ. Бұл қысқаша сипаттамадан жұмыс істейтін прототипке тез көпір қажет командалар үшін, әсіресе прототип тек әдемі емес, пайдалануға жарамды болуы керек кезде, жақсы үйлесім ұсынады.
5) Күрделі диалог және нұсқауды орындау
Тақырып кодтау болғанымен, GLM-5.1 ашық Q&A, күрделі нұсқаулар және көп-бұрылымды интеракцияларда да күштірек деп сипатталады. Бұл модель шектеулерді қадағалап, шығыстарды қайта қарап, ұзын әңгімелер бойы контексті сақтауы керек көмекші-стильді жұмыс ағымдары үшін пайдалы.
Қорытынды: Неліктен GLM-5.1 2026 жылы маңызды
GLM-5.1 — жай ғана кезекті инкремент емес; бұл шын мәнінде қабілетті ашық агенттік ЖИ-дің келгенін білдіреді. Нақты әлемдегі ең күрделі инженерлік бенчмарктерде үздік бола отырып, қолжетімді және ашық қала отырып, Z.ai бүкіл индустрия үшін межені жоғарылатты. Сіз жеке әзірлеуші, кәсіпорын командасы немесе зерттеуші болсаңыз да, GLM-5.1 меншікті баламалар бағасының бір бөлігіне ұзақ мерзімді кодтау тапсырмалары үшін теңдессіз автономия ұсынады.
Дайынсыз ба? Тез қол жеткізу үшін CometAPI GLM-5.1 моделін, Hugging Face репосын немесе GLM Coding Plan-ды қараңыз.