

«кез келген бағамен ауқымдау» философиясы үстемдік еткен ландшафтта — Flux.2 және Hunyuan-Image-3.0 сияқты модельдер параметрлер санын 30B-тан 80B-қа дейінгі орасан диапазонға итермелеп жатқанда — статус-кводы бұзуға арналған жаңа қарсылас пайда болды. Z-Image, Alibaba’s Tongyi Lab әзірлеген, ресми түрде іске қосылып, тұтынушы деңгейіндегі жабдықта жұмыс істей отырып, сала алыбтарымен бәсекелес нәтиже сапасын беретін ықшам 6 миллиард параметрлі архитектурасымен күтулерді күйретті.
2025 жылдың соңында шығарылған Z-Image (және оның аса жылдам нұсқасы — Z-Image-Turbo) бірден AI қауымдастығын баурап алып, дебютінен кейінгі алғашқы 24 сағат ішінде 500,000 жүктеп алу көрсеткішінен асты. Бар болғаны 8 инференс қадамында фотореалистік бейнелерді ұсынуымен, Z-Image жай ғана тағы бір модель емес; бұл генеративті AI-ды демократияландырушы күш, бәсекелестері «тұншықтар» ноутбуктарда жоғары дәл бейнелерді жасауға мүмкіндік береді.
Z-Image деген не?
Z-Image — Tongyi-MAI / Alibaba Tongyi Lab зерттеу тобы әзірлеген жаңа, ашық бастапқы кодты бейне генерациялаушы іргелі модель. Бұл 6 миллиард параметрлі генеративті модель, мәтін токендері, визуалды семантикалық токендер және VAE токендерін бір өңдеу ағынына тізбектейтін жаңашыл Scalable Single-Stream Diffusion Transformer (S3-DiT) архитектурасына негізделген. Дизайн мақсаты айқын: жоғары деңгейлі фотореализм мен нұсқауларға сәйкестікті жеткізу, инференс құнын күрт төмендету және тұтынушы деңгейіндегі жабдықта практикалық қолдануды мүмкін ету. Z-Image жобасы Apache-2.0 лицензиясы бойынша кодты, модель салмақтарын және онлайн демоны жариялайды.
Z-Image бірнеше нұсқада жеткізіледі. Ең көп талқыланатын релиз — Z-Image-Turbo — орналастыруға оңтайландырылған, аз қадамды, дистилденген нұсқа — және дистилденбеген Z-Image-Base (іргелі чекпойнт, fine-tuning-ке қолайлы) мен Z-Image-Edit (бейне өңдеуге арналған нұсқаулыққа бапталған).
«Turbo» артықшылығы: 8 қадамдық инференс
Флагмандық нұсқа, Z-Image-Turbo, Decoupled-DMD (Distribution Matching Distillation) деп аталатын прогрессивті дистилляция техникасын пайдаланады. Бұл модельге генерация процесін стандартты 30-50 қадамнан бар болғаны 8 қадамға сығуға мүмкіндік береді.
Нәтиже: Кәсіпорын GPU-ларында (H800) секундтан төмен генерация уақыты және тұтынушы карталарында (RTX 4090) іс жүзінде нақты уақытты өнімділік, басқа turbo/lightning модельдерге тән «пластик» немесе «жуылған» көрініссіз.
Z-Image-тің 4 негізгі мүмкіндігі
Z-Image техникалық әзірлеушілер мен шығармашылық мамандарға арналған мүмкіндіктерге бай.
1. Салыстырмас фотореализм және эстетика
Бар болғаны 6 миллиард параметрге қарамастан, Z-Image таңғаларлық айқындықпен бейнелер жасайды. Ол келесілерде үздік:
- Тері текстурасы: Адам бейнесінде кеуектерді, кемшіліктерді және табиғи жарықтануды дәл қайталау.
- Материал физикасы: Шыны, металл және мата текстураларын дәл көрсету.
- Жарықтандыру: SDXL-мен салыстырғанда киноқойылымдық және көлемдік жарықтандыруды жоғары деңгейде өңдеу.
2. Табиғи екі тілдегі мәтін рендерингі
AI арқылы бейне генерациялаудағы ең үлкен ауыртпалықтардың бірі — мәтінді дұрыс көрсету. Z-Image бұл мәселені ағылшын және қытай тілдеріне табиғи қолдау арқылы шешеді.
- Ол екі тілде дұрыс емле және каллиграфиямен күрделі постерлер, логотиптер және маңдайшалар жасай алады — бұл функция көбіне батысқа бағытталған модельдерде жоқ.
3. Z-Image-Edit: Нұсқауларға негізделген өңдеу
Негізгі модельмен қатар команда Z-Image-Edit нұсқасын шығарды. Бұл нұсқа бейнеден-бейне тапсырмалары үшін fine-tuning жасалған, пайдаланушыларға табиғи тілдегі нұсқаулар арқылы бар бейнелерді өзгертуге мүмкіндік береді (мысалы, «Адамды күлдір», «Фонды қарлы тауға ауыстыр»). Ол мұндай трансформацияларда тұлға сәйкестігін және жарықтандыруды жоғары тұрақтылықпен сақтайды.
4. Тұтынушы деңгейіндегі жабдыққа қолжетімділік
- VRAM тиімділігі: 6GB VRAM (кванттаумен) немесе 16GB VRAM (толық дәлдік) үстінде жайлы жұмыс істейді.
- Жергілікті орындау: ComfyUI және
diffusersарқылы жергілікті орналастыруды толық қолдайды, пайдаланушыларды бұлтқа тәуелділіктен босатады.
Z-Image қалай жұмыс істейді?
Бір ағынды диффузиялық трансформер (S3-DiT)
Z-Image классикалық қос ағынды дизайндардан (жеке мәтін және бейне энкодерлері/ағындары) бас тартып, мәтін токендерін, бейне VAE токендерін және визуалды семантикалық токендерді жалғыз трансформер енгізуіне тізбектейді. Бұл бір ағынды тәсіл параметрлерді пайдалануды жақсартады және трансформер арқауында кросс-модальды сәйкестікті қарапайымдатады, авторлардың айтуынша, бұл 6B модель үшін тиімділік/сапа арасындағы қолайлы компромисс береді.
Decoupled-DMD және DMDR (дистилляция + RL)
Аз қадамды (8-қадам) генерацияны әдеттегі сапа айыбынсыз мүмкін ету үшін команда Decoupled-DMD дистилляция тәсілін әзірледі. Техника CFG (classifier-free guidance) аугментациясын үлестірімді сәйкестендіруден бөліп, әрқайсысын тәуелсіз оңтайландыруға мүмкіндік береді. Одан кейін олар семантикалық сәйкестік пен эстетиканы жетілдіру үшін оқытудан кейінгі күшейту арқылы оқыту қадамын (DMDR) қолданады. Бірлесіп, бұлар Z-Image-Turbo-ны әдеттегі диффузиялық модельдерге қарағанда әлдеқайда аз NFE санымен, жоғары реализмді сақтай отырып шығарады.
Оқыту өткізу қабілеті және шығынды оңтайландыру
Z-Image өмірлік циклді оңтайландыру тәсілімен оқытылды: мұқият курирленген деректер конвейерлері, ықшамдалған оқу бағдарламасы және тиімділікке бағдарланған іске асыру таңдаулары. Авторлар толық оқыту жұмыс ағынын шамамен 314K H800 GPU сағатына (≈ USD $630K) аяқтағанын хабарлайды — бұл өте үлкен (>20B) баламаларға қатысты шығын тиімділігін көрсететін айқын, қайталанатын инженерлік метрика.
Z-Image моделінің бенчмарк нәтижелері
Z-Image-Turbo бірнеше заманауи лидербордтарда жоғары орындарға ие болды, соның ішінде Artificial Analysis Text-to-Image лидербордында ашық бастапқы кодты модельдер арасында жоғарғы позиция және Alibaba AI Arena адамдық қалаулар бағалауларында күшті көрсеткіштер.
Бірақ нақты әлемдегі сапа промптты құрастыруға, рұқсатқа, апскейл конвейеріне және қосымша пост-өңдеуге де байланысты.
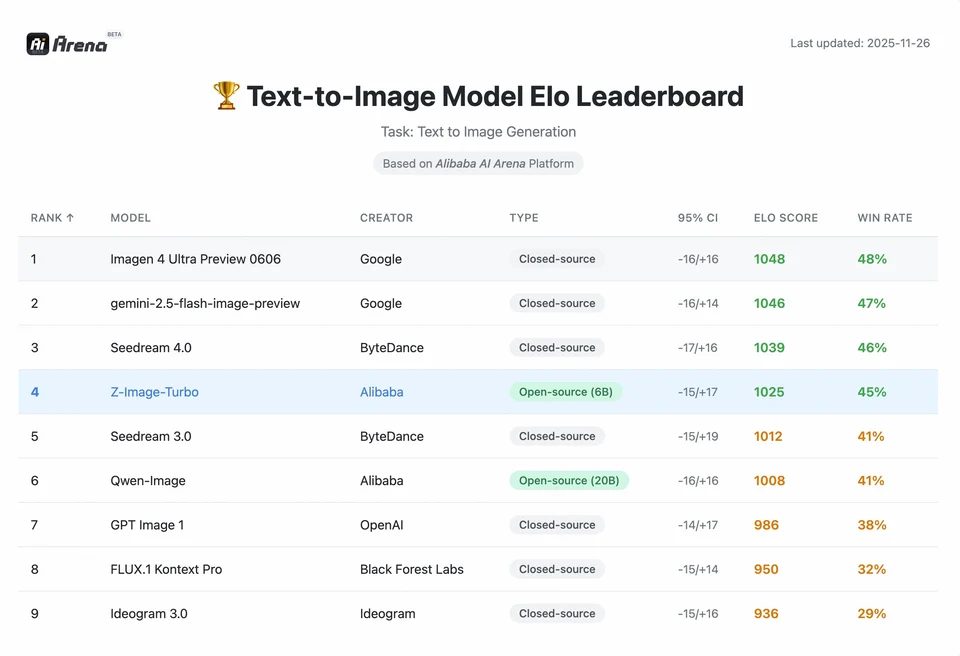
Z-Image жетістігінің ауқымын түсіну үшін деректерге қарау керек. Төменде Z-Image-ті жетекші ашық және меншік моделдермен салыстырмалы талдау берілген.
Салыстырмалы бенчмарк қысқаша мазмұны
| Ерекшелік / Метрика | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Архитектура | S3-DiT (Single Stream) | MM-DiT (Dual Stream) | U-Net | Diffusion Transformer |
| Параметрлер | 6 миллиард | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Инференс қадамдары | 8 қадам | 25 - 50 қадам | 1 - 4 қадам | 30 - 50 қадам |
| Қажетті VRAM | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Мәтін рендерингі | Жоғары (EN + CN) | Жоғары (EN) | Орташа (EN) | Жоғары (CN + EN) |
| Генерация жылдамдығы (4090) | ~1.5 - 3.0 секунд | ~15 - 30 секунд | ~0.5 секунд | ~20 секунд |
| Фотореализм ұпайы | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| Лицензия | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
Деректер талдауы және өнімділік инсайттары
- Жылдамдық пен сапа: SDXL Turbo жылдамырақ (1-қадам) болғанымен, күрделі промпттарда сапасы айтарлықтай төмендейді. Z-Image-Turbo 8 қадамда «алтын ортаны» табады, Flux.2-ның сапасына теңесе отырып, 5x–10x жылдамырақ.
- Құрал-жабдыққа қолжетімділікті кеңейту: Flux.2 қуатты болса да, іс жүзінде 24GB VRAM карталарына (RTX 3090/4090) тәуелді. Z-Image орта деңгейлі карталары бар пайдаланушыларға (RTX 3060/4060) кәсіби деңгейдегі, 1024x1024 бейнелерді жергілікті жасауға мүмкіндік береді.
Әзірлеушілер Z-Image-ке қалай қол жеткізіп, қалай пайдалана алады?
Үш типтік тәсіл бар:
- Hosted / SaaS (web UI немесе API): z-image.ai сияқты қызметтерді пайдаланыңыз немесе модельді орналастырып, бейне генерация үшін веб-интерфейс немесе ақылы API ұсынатын басқа провайдерлерді қолданыңыз. Бұл жергілікті орнатусыз эксперименттер үшін ең жылдам жол.
- Hugging Face + diffusers конвейерлері: Hugging Face
diffusersкітапханасыZImagePipelineжәнеZImageImg2ImgPipelineқамтып, әдеттегіfrom_pretrained(...).to("cuda")жұмыс процестерін ұсынады. Бұл Python әзірлеушілері үшін тікелей интеграция және қайталанатын мысалдар үшін ұсынылатын жол. - GitHub реподан жергілікті native инференс: Tongyi-MAI репосы native инференс скрипттерін, оңтайландыру опцияларын (FlashAttention, компиляция, CPU offload) және ең соңғы интеграция үшін
diffusers-ті бастапқыдан орнату жөніндегі нұсқауларды қамтиды. Бұл жол зерттеушілер мен толық бақылау алғысы келетін немесе custom training/fine-tuning жүргізгісі келетін командалар үшін пайдалы.
Минимал Python мысалы қандай көрінеді?
Төменде Hugging Face diffusers пайдаланып, Z-Image-Turbo арқылы мәтіннен бейне генерациясын көрсететін ықшам Python үзіндісі берілген.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Ескертпе: guidance_scale үшін әдепкі және ұсынылған параметрлер Turbo модельдерде өзгеше; құжаттама Turbo үшін мақсатты мінез-құлыққа байланысты бағыттау мәнін төмен немесе нөлге қоюды ұсынады.
Z-Image арқылы image-to-image (edit) қалай іске қосасыз?
ZImageImg2ImgPipeline бейне өңдеуді қолдайды. Мысал:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Бұл ресми қолдану үлгілерін қайталайды және шығармашылық өңдеу мен inpainting тапсырмаларына жарамды.
Промпттар мен guidance-ке қалай жақындау керек?
- Құрылымды айқын көрсетіңіз: Күрделі көріністер үшін промпттарды көрініс композициясын, негізгі объектіні, камера/линзаны, жарықтандыруды, көңіл-күйді және кез келген мәтін элементтерін қамтитындай құрылымдаңыз. Z-Image егжей-тегжейлі промпттардан пайда көреді және позициялық/нарративтік нұсқауларды жақсы өңдейді.
guidance_scale-ді мұқият баптаңыз: Turbo модельдер үшін төмен guidance мәндері ұсынылуы мүмкін; эксперимент қажет. Көптеген Turbo жұмыс ағындары үшінguidance_scale=0.0–1.0мәні, seed және бекітілген қадамдармен тұрақты нәтижелер береді.- Бақыланатын өзгерістер үшін image-to-image пайдаланыңыз: Композицияны сақтап, стиль/түстерді/объектілерді өзгерту керек болғанда, бастапқы бейнеден бастаңыз және өзгеріс ауқымын басқару үшін
strengthпараметрін қолданыңыз.
Ең жақсы қолданылу сценарийлері және үздік тәжірибелер
1. Жылдам прототиптеу және сторибординг
Қолданылу: Режиссерлер мен ойын дизайнерлеріне көріністерді бірден визуализациялау қажет.
Неліктен Z-Image? 3 секундтан қысқа генерациямен, авторлар бір сессияда жүздеген концептті қайталап, жарықтандыру мен композицияны нақты уақытта күтусіз жетілдіре алады.
2. E-Commerce және жарнама
Қолданылу: Тауарларға арналған өнім фонын немесе өмір салты кадрларын генерациялау.
Үздік тәжірибе: Z-Image-Edit қолданыңыз.
Өнімнің өңделмеген фотосын жүктеп, «Бұл әтір бөтелкесін күн сәулелі бақтағы ағаш үстелге қой» сияқты нұсқаулық промптты пайдаланыңыз. Модель өнімнің тұтастығын сақтай отырып, фотореалистік фонды «галлюцинациялайды».
3. Екі тілдегі контентті жасау
Қолданылу: Батыс және Азия нарықтарына қатар бағытталған жаһандық маркетинг кампаниялары.
Үздік тәжірибе: Мәтін рендеринг мүмкіндігін пайдаланыңыз.
- Сұраныс: "A neon sign that says 'OPEN' and '营业中' glowing in a dark alley."
- Z-Image ағылшын және қытай таңбаларын дұрыс көрсетеді — бұл мүмкіндікті басқа көптеген модельдер орындай алмайды.
4. Төмен ресурсты орта
Қолданылу: Шеткі құрылғыларда немесе стандартты офис ноутбуктарында AI генерациясын іске қосу.
Оңтайландыру кеңесі: Z-Image-тің INT8 квантталған нұсқасын қолданыңыз. Бұл VRAM тұтынуды 6GB-тан төменге түсіреді және сапаға әсері елеусіз, ойынға арналмаған ноутбуктардағы жергілікті қолданбалар үшін мүмкін етеді.
Қорытынды: Z-Image-ті кім қолдануы керек?
Z-Image жоғары сапалы фотореализмді практикалық кідіріс пен құнмен қалайтын және ашық лицензияны әрі on-premises немесе custom hosting-ті қалайтын ұйымдар мен әзірлеушілерге арналған. Ол жылдам итерация қажет командаларға (шығармашылық құралдар, өнім моксаптары, нақты уақыт қызметтері) және ықшам, бірақ қуатты бейне моделін fine-tuning жасағысы келетін зерттеушілер/қауымдастық мүшелеріне ерекше тартымды.
CometAPI ұқсас түрде шектеулері аз Grok Image модельдерін, сондай-ақ Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) сияқты модельдерді ұсынады — дұрыс NSFW кеңестері мен амалдары арқылы шектеулерден айналып өтіп, еркін құруды бастауға болады. Қол жеткізбестен бұрын, CometAPI-ге кіргеніңізге және API кілтін алғаныңызға көз жеткізіңіз. CometAPI интеграцияға көмектесу үшін ресми бағадан әлдеқайда төмен баға ұсынады.
Дайынсыз ба?→ Құруға арналған тегін сынақ !