

지난 몇 달 동안 에이전트 코딩(agentic coding)이 급속도로 확대되었습니다. 에이전트 코딩은 단순히 일회성 프롬프트에 응답하는 것이 아니라 전체 저장소에 걸쳐 계획, 편집, 테스트 및 반복 작업을 수행하는 전문 모델입니다. 가장 주목받는 두 가지 진입 사례는 다음과 같습니다. 작곡가Cursor가 Cursor 2.0 릴리스와 함께 도입한 특수 목적의 저지연 코딩 모델입니다. GPT-5-코덱스OpenAI의 에이전트 최적화 버전인 GPT-5는 지속적인 코딩 워크플로우에 맞춰 조정되었습니다. 이 두 가지 모델은 개발자 툴링의 새로운 단층선을 보여줍니다. 속도 대 깊이, 로컬 작업 공간 인식 대 일반론적 추론, 그리고 "바이브 코딩" 편의성 대 엔지니어링 엄격성.
한눈에 보기: 직접 비교 차이점
- 디자인 의도: GPT-5-Codex - 길고 복잡한 세션을 위한 심층적이고 에이전트적인 추론과 견고성; Composer - 속도에 최적화된 빠르고 작업 공간을 인식하는 반복 기능.
- 1차 통합 표면: GPT-5-Codex — Codex 제품/응답 API, IDE, 엔터프라이즈 통합; Composer — 커서 편집기 및 커서의 다중 에이전트 UI.
- 지연/반복: Composer는 30초 이내의 턴을 강조하고 속도 측면에서 큰 이점을 주장하는 반면, GPT-5-Codex는 필요한 경우 철저함과 수 시간에 걸친 자율 주행을 우선시합니다.
나는 GPT-5-코덱스 API 제공 모델 코멧API (공식 API 가격보다 일반적으로 API 가격이 저렴한 제3자 API 집계 제공업체)에서 Cursor 2.0의 Composer 모델을 사용한 경험을 요약하고 코드 생성 판단의 다양한 측면에서 두 모델을 비교했습니다.
Composer와 GPT-5-Codex는 무엇입니까?
GPT-5-Codex란 무엇이고 어떤 문제를 해결하는 것을 목표로 합니까?
OpenAI의 GPT-5-Codex는 GPT-5의 특화된 스냅샷으로, OpenAI는 이 스냅샷이 테스트 실행, 저장소 규모의 코드 편집 수행, 그리고 검사가 통과할 때까지 자율적으로 반복되는 에이전트 코딩 시나리오에 최적화되어 있다고 밝혔습니다. 이 기능은 복잡한 리팩터링에 대한 심층 추론, 장기적 "에이전트" 작업(모델이 추론 및 테스트에 몇 분에서 몇 시간까지 소요될 수 있음), 그리고 실제 엔지니어링 문제를 반영하도록 설계된 표준화된 벤치마크에서의 더 강력한 성능 등 다양한 엔지니어링 작업에 걸친 광범위한 기능에 중점을 두고 있습니다.
Composer란 무엇이고 어떤 문제를 해결하는 것을 목표로 합니까?
Composer는 Cursor 2.0에서 처음 공개된 Cursor 최초의 네이티브 코딩 모델입니다. Cursor는 Composer를 개발자 워크플로 내에서 낮은 지연 시간과 빠른 반복을 위해 구축된 최첨단 에이전트 중심 모델로 설명합니다. 즉, 다중 파일 diff 계획, 저장소 전체에 걸친 의미 검색 적용, 그리고 대부분의 턴을 30초 이내에 완료하는 기능을 제공합니다. Composer는 루프(검색, 편집, 테스트 하네스) 내에서 도구 접근을 통해 학습되어 실제 엔지니어링 작업에서 효율성을 높이고 일상적인 코딩에서 반복되는 프롬프트-응답 사이클의 마찰을 최소화합니다. Cursor는 Composer를 개발자 속도 및 실시간 피드백 루프에 최적화된 모델로 자리매김합니다.
모델 범위 및 런타임 동작
- 작곡가: 빠르고 편집자 중심적인 상호작용과 다중 파일 일관성을 위해 최적화되었습니다. Cursor의 플랫폼 수준 통합을 통해 Composer는 저장소를 더 많이 파악하고 다중 에이전트 오케스트레이션(예: 두 개의 Composer 에이전트 대 다른 에이전트)에 참여할 수 있습니다. Cursor는 이를 통해 파일 간 종속성 누락을 줄일 수 있다고 주장합니다.
- GPT-5-코덱스: 심층적이고 가변적인 추론에 최적화되어 있습니다. OpenAI는 이 모델이 필요할 때 컴퓨팅/시간을 더 심층적인 추론으로 전환할 수 있다고 홍보합니다. 가벼운 작업에는 몇 초가 소요되는 반면, 광범위한 자율 실행에는 몇 시간이 소요되는 것으로 알려져 있으며, 이를 통해 더욱 철저한 리팩터링과 테스트 기반 디버깅이 가능합니다.
간략한 버전: Composer = Cursor의 IDE 내부, 작업 공간 인식 코딩 모델, GPT-5-Codex = Responses/Codex를 통해 제공되는 소프트웨어 엔지니어링을 위한 OpenAI의 특수 GPT-5 변형.
Composer와 GPT-5-Codex의 속도를 비교하면 어떻습니까?
판매자들은 무엇을 주장했나요?
Cursor는 Composer를 "초고속 개척자" 코더로 자리매김했습니다. 공개된 수치는 초당 토큰 단위로 측정된 생성 처리량과 Cursor 내부 하네스에서 "초기" 모델 대비 24배 빠른 대화형 코딩 완료 시간을 강조합니다. 독립적인 보도(언론 및 초기 테스터)에 따르면 Composer는 Cursor 환경에서 초당 약 200250개의 토큰으로 코드를 생성하며, 일반적인 대화형 코딩 턴을 대부분 30초 이내에 완료합니다.
커뮤니티 보고와 이슈 스레드에 따르면, OpenAI의 GPT-5-Codex는 지연 시간 실험으로 자리매김하지 않았습니다. 견고성과 심층적인 추론을 우선시하며, 비교적 높은 추론 작업 부하에서 더 큰 컨텍스트 크기에서 사용하면 속도가 느려질 수 있습니다.
우리가 속도를 벤치마킹한 방법(방법론)
공정한 속도 비교를 생성하려면 작업 유형(짧은 완료 대 긴 추론), 환경(네트워크 지연, 로컬 대 클라우드 통합)을 제어하고 두 가지를 모두 측정해야 합니다. 첫 번째 유용한 결과까지의 시간 및 엔드투엔드 벽시계 (테스트 실행이나 컴파일 단계 포함). 주요 사항:
- 선택된 작업 — 작은 스니펫 생성(API 엔드포인트 구현), 중간 작업(한 파일 리팩토링 및 가져오기 업데이트), 큰 작업(3개 파일에 걸쳐 기능 구현, 테스트 업데이트).
- 통계 — 첫 번째 토큰까지의 시간, 첫 번째 유용한 차이점까지의 시간(후보 패치가 방출될 때까지의 시간), 테스트 실행 및 검증을 포함한 총 시간입니다.
- 반복 — 각 작업은 10배로 실행되며, 네트워크 노이즈를 줄이기 위해 중간값이 사용되었습니다.
- 환경 — 안정적인 100/10Mbps 링크를 사용하여 도쿄의 개발자 컴퓨터에서 측정한 결과(실제 지연 시간을 반영함). 결과는 지역에 따라 다를 수 있습니다.
아래는 재생산 가능한 것입니다 속도 하네스 GPT-5-Codex(응답 API)에 대한 설명과 Cursor 내부에서 Composer를 측정하는 방법에 대한 설명입니다.
속도 하네스(Node.js) — GPT-5-Codex(응답 API):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
이는 공개 Responses API를 사용하여 GPT-5-Codex에 대한 종단 간 요청 지연 시간을 측정합니다(OpenAI 문서에서는 Responses API와 gpt-5-codex 모델 사용법을 설명합니다).
Composer 속도(커서)를 측정하는 방법:
Composer는 Cursor 2.0(데스크톱/VS Code 포크) 내부에서 실행됩니다. Cursor는 (이 글을 쓰는 시점에는) OpenAI의 Responses API와 같은 Composer용 일반 외부 HTTP API를 제공하지 않습니다. Composer의 강점은 다음과 같습니다. IDE 내 상태 저장 작업 공간 통합따라서 인간 개발자처럼 Composer를 측정하세요.
- Cursor 2.0 내에서 동일한 프로젝트를 엽니다.
- Composer를 사용하여 에이전트 작업(경로 생성, 리팩토링, 다중 파일 변경)으로 동일한 프롬프트를 실행합니다.
- Composer 계획을 제출하면 스톱워치를 시작합니다. Composer가 원자적 차이를 내보내고 테스트 모음을 실행하면 멈춥니다(커서 인터페이스는 테스트를 실행하고 통합된 차이를 보여줄 수 있습니다).
- 10번 반복하고 중앙값을 사용합니다.
Cursor에서 공개한 자료와 실습 리뷰에 따르면 Composer는 실제로 많은 일반적인 작업을 약 30초 이내에 완료합니다. 이는 원시 모델 추론 시간이 아니라 대화형 지연 시간 목표입니다.
테이크 아웃 : Composer의 설계 목표는 편집기 내에서 빠른 인터랙티브 편집입니다. 만약 낮은 지연 시간과 대화형 코딩 루프를 중요하게 생각한다면, Composer는 바로 그러한 사용 사례에 적합합니다. GPT-5-Codex는 장시간 세션에서 정확성과 에이전트 추론에 최적화되어 있습니다. 더 깊은 계획을 위해 약간의 지연 시간을 감수할 수 있습니다. 공급업체별 수치가 이러한 포지셔닝을 뒷받침합니다.
Composer와 GPT-5-Codex의 정확도는 어떻게 비교됩니까?
AI 코딩에서 정확도란 무엇을 의미할까?
여기서 정확성은 다각적입니다. 기능적 정확성 (코드가 컴파일되고 테스트를 통과하는가) 의미적 정확성 (동작이 사양을 충족하는지) 및 견고성 (특수한 경우와 보안 문제를 처리합니다).
공급업체 및 언론사 번호
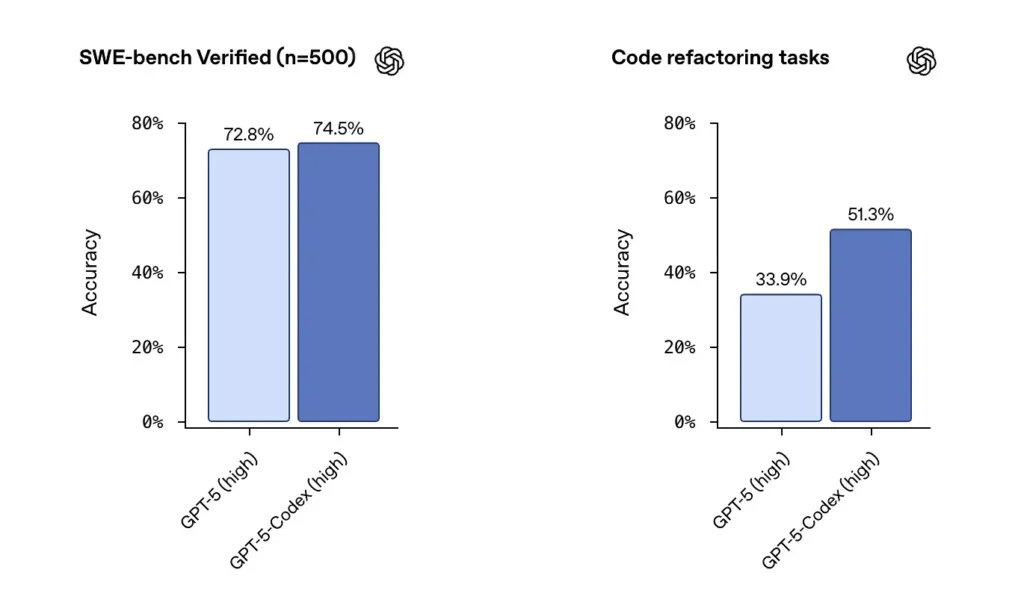
OpenAI는 SWE-bench 검증 데이터 세트에서 GPT-5-Codex의 강력한 성능을 보고하고 강조했습니다. 74.5 %의 성공률 실제 코딩 벤치마크(언론 보도에 보도됨)와 리팩토링 성공률의 눈에 띄는 증가(내부 리팩토링 테스트에서 기본 GPT-5의 33.9% 대비 51.3%)를 보였습니다.
커서 릴리스는 Composer가 편집기 통합 및 저장소 가시성이 중요한 다중 파일, 상황에 맞는 편집에서 종종 탁월한 성능을 보인다는 것을 보여줍니다. 테스트 결과, Composer는 다중 파일 리팩터링 시 종속성 누락 오류가 적었고, 일부 다중 파일 워크로드에 대한 블라인드 리뷰 테스트에서 더 높은 점수를 받았습니다. Composer의 지연 시간과 병렬 에이전트 기능 또한 반복 작업 속도 향상에 도움이 됩니다.
독립적인 정확도 테스트(권장 방법)
공정한 테스트는 다음을 혼합하여 사용합니다.
- 단위 테스트: 두 모델에 동일한 저장소와 테스트 모음을 제공합니다. 코드를 생성하고 테스트를 실행합니다.
- 리팩토링 테스트: 의도적으로 지저분한 함수를 제공하고 모델에 리팩토링과 테스트를 추가하도록 요청합니다.
- 보안 검사: 생성된 코드에 정적 분석 및 SAST 도구를 실행합니다(예: Bandit, ESLint, semgrep).
- 사람의 검토: 유지보수성과 모범 사례에 대한 숙련된 엔지니어의 코드 검토 점수입니다.
예: 자동화된 테스트 하네스(Python) - 생성된 코드 및 단위 테스트 실행
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
이 패턴을 사용하면 모델 출력이 기능적으로 올바른지(테스트 통과 여부) 자동으로 확인합니다. 리팩토링 작업의 경우, 원본 저장소와 모델의 diff를 비교하여 테스트 통과율과 커버리지 변화를 비교합니다.
테이크 아웃 : 원시 벤치마크 스위트에서 GPT-5-Codex는 우수한 수치와 강력한 리팩토링 성능을 보여줍니다. 실제 환경에서 여러 파일을 수정하고 편집기 워크플로를 사용하는 경우, Composer의 작업 영역 인식 기능은 실제 수용도가 높고 "기계적" 오류(가져오기 누락, 잘못된 파일 이름)가 줄어듭니다. 단일 파일 알고리즘 작업에서 최대한의 기능적 정확성을 요구하는 경우 GPT-5-Codex가 강력한 후보입니다. IDE 내에서 여러 파일을 다루고 컨벤션에 민감한 변경 작업을 수행하는 경우에는 Composer가 탁월한 성능을 발휘합니다.
Composer와 GPT-5: 코드 품질은 어떻게 비교되나요?
품질이란 무엇인가?
품질에는 가독성, 명명, 문서화, 테스트 커버리지, 관용적 패턴 사용, 그리고 보안 위생이 포함됩니다. 품질은 린터, 복잡성 지표와 같은 자동 측정 방식과 사람 검토를 통한 정성적 측정 방식으로 모두 측정됩니다.
관찰된 차이점
- GPT-5-코덱스: 명시적으로 요청 시 관용적인 패턴을 생성하는 데 능숙합니다. 알고리즘의 명확성이 뛰어나고, 요청 시 포괄적인 테스트 스위트를 생성할 수 있습니다. OpenAI의 Codex 도구에는 통합 테스트/보고 및 실행 로그가 포함되어 있습니다.
- 작곡가: 저장소의 스타일과 규칙을 자동으로 준수하도록 최적화되었습니다. Composer는 기존 프로젝트 패턴을 따르고 여러 파일에 대한 업데이트를 조정할 수 있습니다(이름 변경/리팩토링 전파, 업데이트 가져오기). 대규모 프로젝트에 필요한 뛰어난 온디맨드 유지 관리 기능을 제공합니다.
실행할 수 있는 예제 코드 품질 검사
- 린터 — ESLint / pylint
- 복잡성 — 라돈 / 플레이크8-복잡성
- 보안 — semgrep / Bandit
- 테스트 커버리지 — JS의 경우 coverage.py 또는 vitest/nyc를 실행합니다.
모델 패치 적용 후 이러한 검사를 자동화하여 개선 또는 회귀를 정량화합니다. 예제 명령 시퀀스(JS 저장소):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
인간 검토 및 모범 사례
실제로 모델은 모범 사례를 따르도록 지시해야 합니다. 즉, docstring, 유형 주석, 종속성 고정 또는 특정 패턴(예: async/await)을 요청해야 합니다. GPT-5-Codex는 명시적인 지시어가 주어졌을 때 매우 효과적이며, Composer는 암묵적인 저장소 컨텍스트를 활용합니다. 두 가지 방법을 병행하여 사용하세요. 모델에 명시적으로 지시하고, Cursor 내부에 있는 경우 Composer가 프로젝트 스타일을 적용하도록 하는 것입니다.
권장 사항 : IDE 내에서 다중 파일 엔지니어링 작업을 하는 경우 Composer를 선호합니다. API를 호출하고 대규모 컨텍스트를 제공할 수 있는 외부 파이프라인, 연구 작업 또는 툴체인 자동화의 경우 GPT-5-Codex가 강력한 선택입니다.
통합 및 배포 옵션
Composer는 Cursor 2.0의 일부로 Cursor 편집기와 UI에 내장되어 제공됩니다. Cursor의 접근 방식은 Composer를 다른 모델과 함께 실행하는 단일 공급업체 제어 평면을 강조합니다. 이를 통해 사용자는 동일한 프롬프트에서 여러 모델 인스턴스를 실행하고 편집기 내에서 출력을 비교할 수 있습니다. ()
GPT-5-Codex는 OpenAI의 Codex 제품군과 ChatGPT 제품군에 통합되며, ChatGPT 유료 티어와 CometAPI와 같은 타사 플랫폼에서 제공하는 API를 통해 더 나은 가성비를 제공합니다. OpenAI는 또한 Codex를 개발자 도구 및 클라우드 파트너 워크플로(예: Visual Studio Code/GitHub Copilot 통합)에 통합하고 있습니다.
Composer와 GPT-5-Codex는 앞으로 업계를 어떤 방향으로 이끌까요?
단기 효과
- 더 빠른 반복 주기: Composer와 같은 편집기 내장 모델은 사소한 수정과 PR 생성에 따른 마찰을 줄여줍니다.
- 검증에 대한 기대치 상승: Codex는 테스트, 로그, 자율 기능에 중점을 두고 있으므로 공급업체는 모델에서 생성된 코드에 대해 더욱 강력한 기본 검증을 제공하게 될 것입니다.
중장기적으로
- 다중 모델 오케스트레이션이 일반화되었습니다. 커서의 다중 에이전트 GUI는 엔지니어가 곧 여러 전문 에이전트(린팅, 보안, 리팩토링, 성능 최적화)를 병렬로 실행하고 최상의 출력을 수용하게 될 것이라는 초기 힌트입니다.
- 더욱 긴밀한 CI/AI 피드백 루프: 모델이 개선됨에 따라 CI 파이프라인은 모델 기반 테스트 생성과 자동화된 수리 제안을 점점 더 통합하게 될 것입니다. 하지만 사람이 직접 검토하고 단계적으로 출시하는 것이 여전히 중요합니다.
결론
Composer와 GPT-5-Codex는 같은 군비 경쟁에서 사용되는 동일한 무기가 아닙니다. 소프트웨어 수명 주기의 각 단계에 최적화된 상호 보완적인 도구입니다. Composer의 가치 제안은 속도입니다. 개발자들이 흐름을 유지할 수 있도록 하는 빠르고 작업 공간 기반의 반복 작업입니다. GPT-5-Codex의 가치는 깊이입니다. 에이전트 기반 지속성, 테스트 기반 정확성, 그리고 대규모 변환에 대한 감사 가능성을 제공합니다. 실용적인 엔지니어링 플레이북은 둘 다 조율하다: 일상적인 흐름을 위한 짧은 루프 Composer 유사 에이전트와, 게이트 방식의 고신뢰도 작업을 위한 GPT-5-Codex 스타일 에이전트. 초기 벤치마크 결과는 두 에이전트가 서로 대체되는 것이 아니라 단기적으로 개발자 툴킷의 일부가 될 것임을 시사합니다.
모든 차원에서 단 하나의 객관적인 승자는 없습니다. 각 모델은 서로 다른 강점을 가지고 있습니다.
- GPT-5-코덱스: 심층적인 정확성 벤치마크, 대규모 추론, 그리고 자율적인 수시간 워크플로우에서 더욱 강력합니다. 작업 복잡성으로 인해 긴 추론이나 엄격한 검증이 필요할 때 빛을 발합니다.
- 작곡가: 편집기와 긴밀하게 통합된 사용 사례, 여러 파일 컨텍스트 일관성, 그리고 Cursor 환경 내에서 빠른 반복 속도에서 더욱 강력합니다. 즉각적이고 정확한 컨텍스트 인식 편집이 필요한 일상적인 개발자 생산성 향상에 더욱 효과적일 수 있습니다.
참조 Cursor 2.0과 Composer: 멀티 에이전트가 AI 코딩을 재고하는 방식
시작 가이드
CometAPI는 OpenAI의 GPT 시리즈, Google의 Gemini, Anthropic의 Claude, Midjourney, Suno 등 주요 공급업체의 500개 이상의 AI 모델을 단일 개발자 친화적인 인터페이스로 통합하는 통합 API 플랫폼입니다. CometAPI는 일관된 인증, 요청 형식 지정 및 응답 처리를 제공하여 애플리케이션에 AI 기능을 통합하는 과정을 획기적으로 간소화합니다. 챗봇, 이미지 생성기, 음악 작곡가 또는 데이터 기반 분석 파이프라인 등 어떤 제품을 구축하든 CometAPI를 사용하면 AI 생태계 전반의 최신 혁신 기술을 활용하면서 반복 작업을 더 빠르게 수행하고 비용을 관리하며 공급업체에 구애받지 않을 수 있습니다.
개발자는 액세스할 수 있습니다 GPT-5-코덱스 APICometAPI를 통해 최신 모델 버전 공식 웹사이트에서 항상 업데이트됩니다. 시작하려면 모델의 기능을 살펴보세요. 운동장 그리고 상담하십시오 API 가이드 자세한 내용은 CometAPI를 참조하세요. 접속하기 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인하세요. 코멧API 공식 가격보다 훨씬 낮은 가격을 제공하여 통합을 돕습니다.
출발 준비 되셨나요?→ 지금 CometAPI에 가입하세요 !