
Gemini 2.5 Flash API는 제어 가능한 추론 기능을 통해 고속, 비용 효율적인 작업을 위해 설계된 Google의 최신 멀티모달 AI 모델로, 개발자는 Gemini API를 통해 고급 "사고" 기능을 켜거나 끌 수 있습니다. 최신 모델은 gemini-2.5-flash.
Gemini 2.5 Flash 개요
Gemini 2.5 Flash는 출력 품질 저하 없이 빠른 응답을 제공하도록 설계되었습니다. 텍스트, 이미지, 오디오, 비디오 등 다중 모드 입력을 지원하여 다양한 애플리케이션에 적합합니다. 이 모델은 Google AI Studio 및 Vertex AI와 같은 플랫폼을 통해 접근 가능하며, 개발자에게 다양한 시스템에 원활하게 통합하는 데 필요한 도구를 제공합니다.
기본 정보(특징)
Gemini 2.5 Flash는 여러 가지 뛰어난 기능을 선보입니다. 풍모 Gemini 2.5 제품군 내에서 구별되는 점은 다음과 같습니다.
- 하이브리드 추론: 개발자는 다음을 설정할 수 있습니다. 생각_예산 출력하기 전에 모델이 내부 추론에 얼마나 많은 토큰을 할당하는지를 정밀하게 제어하는 매개변수입니다.
- 파레토 프론티어: 위치 최적의 비용 대비 성능 지점, Flash는 2.5 모델 중에서 가격대비 지능성이 가장 뛰어납니다.
- 다중 모드 지원: 프로세스 본문, 형상, 비디오및 오디오 기본적으로 더 풍부한 대화 및 분석 기능을 제공합니다.
- 1만 토큰 컨텍스트: 일치하지 않는 컨텍스트 길이 덕분에 단일 요청으로 심층 분석과 긴 문서 이해가 가능합니다.
모델 버전 관리
Gemini 2.5 Flash는 다음 키를 통해 전환되었습니다. 버전:
- gemini-2.5-flash-lite-preview-09-2025: 도구 사용성 향상: 복잡하고 여러 단계로 구성된 작업에서 SWE-Bench Verified 점수가 5%(48.9%에서 54%) 증가하여 성능이 향상되었습니다. 효율성 향상: 추론 기능을 활성화하면 더 적은 토큰으로 더 높은 품질의 출력을 얻을 수 있어 지연 시간과 비용이 감소합니다.
- 미리보기 04-17: "생각" 기능을 갖춘 조기 액세스 릴리스, 다음을 통해 사용 가능 제미니-2.5-플래시-미리보기-04-17.
- 안정적인 일반 공급(GA): 17년 2025월 XNUMX일 기준 안정적 종착점 제미니-2.5-플래시 20월 XNUMX일 미리보기에서 API를 변경하지 않고도 프로덕션 수준의 안정성을 보장하며 미리보기를 대체합니다.
- 미리보기 사용 중단: 미리보기 엔드포인트는 15년 2025월 XNUMX일에 종료될 예정이었습니다. 사용자는 이 날짜 전에 GA 엔드포인트로 마이그레이션해야 합니다.
2025년 2.5월 현재 Gemini XNUMX Flash는 이제 공개적으로 사용 가능하며 안정적입니다(변경 사항 없음) 제미니-2.5-플래시-미리보기-05-20 ).사용하는 경우 gemini-2.5-flash-preview-04-17기존 미리보기 가격은 15년 2025월 XNUMX일 모델 엔드포인트가 예정된 종료 시점까지 유지됩니다. 일반적으로 사용 가능한 모델로 마이그레이션할 수 있습니다.gemini-2.5-flash".
더 빠르게, 더 저렴하게, 더 스마트하게:
- 설계 목표: 낮은 지연 시간 + 높은 처리량 + 낮은 비용
- 추론, 다중 모드 처리, 긴 텍스트 작업의 전반적인 속도가 향상됩니다.
- 토큰 사용량이 20~30% 감소하여 추론 비용이 크게 줄어듭니다.
기술 사양
입력 컨텍스트 창: 최대 1만 개의 토큰을 사용하여 광범위한 컨텍스트 보존이 가능합니다.
출력 토큰: 응답당 최대 8,192개의 토큰을 생성할 수 있습니다.
지원되는 모달리티: 텍스트, 이미지, 오디오, 비디오.
통합 플랫폼: Google AI Studio 및 Vertex AI를 통해 사용 가능합니다.
가격: 경쟁력 있는 토큰 기반 가격 책정 모델로 비용 효율적인 배포가 가능합니다.
기술적인 세부 사항
Gemini 2.5 Flash의 내부는 다음과 같습니다. 변압기 기반 웹, 코드, 이미지, 비디오 데이터를 혼합하여 학습된 대규모 언어 모델. 핵심 기술의 사양에는 다음이 포함됩니다.
다중 모드 훈련: 여러 모달리티를 정렬하도록 훈련된 Flash는 텍스트를 원활하게 혼합할 수 있습니다. 형상, 비디오및 오디오비디오 요약이나 오디오 캡션과 같은 작업에 유용합니다.
역동적인 사고 과정: 모델이 내부 추론 루프를 구현합니다. 계획 및 복잡한 프롬프트를 분석합니다 최종 출력 전.
구성 가능한 사고 예산다음 생각_예산 에서 설정할 수 있습니다 0 (추론 없음)까지 24,576 토큰이를 통해 지연 시간과 답변 품질 간의 균형을 유지할 수 있습니다.
도구 통합: 지원 Google 검색을 통한 접지, 코드 실행, URL 컨텍스트및 함수 호출자연어 프롬프트에서 직접 실제 작업을 수행할 수 있습니다.
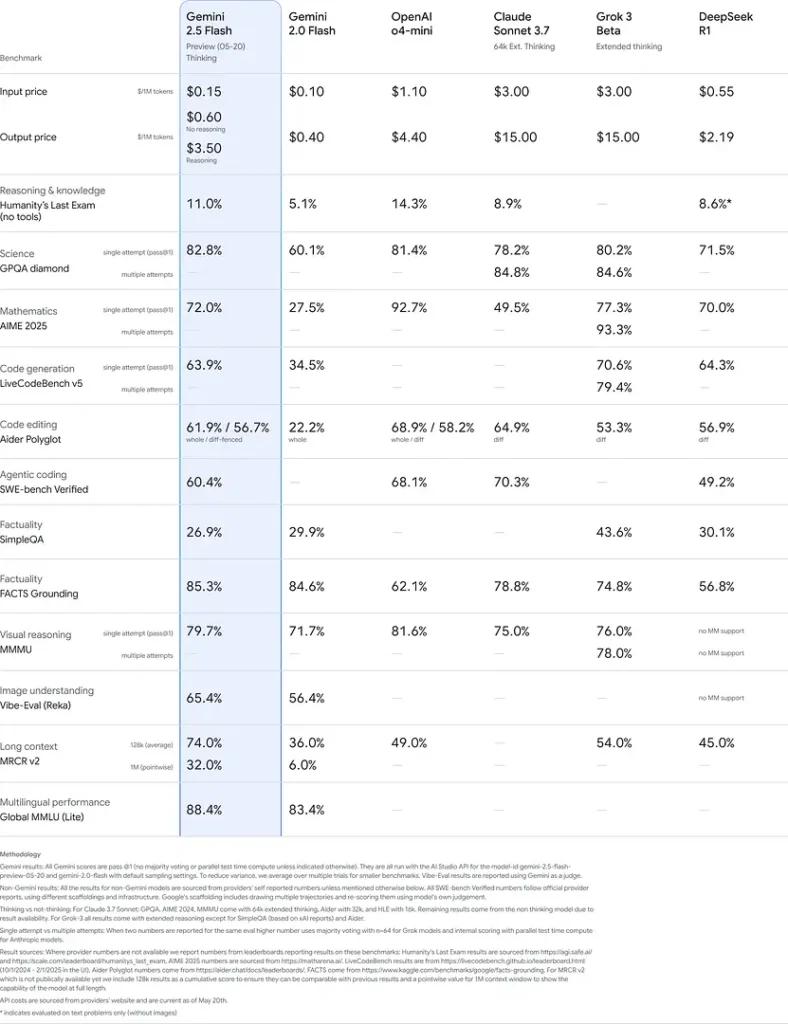
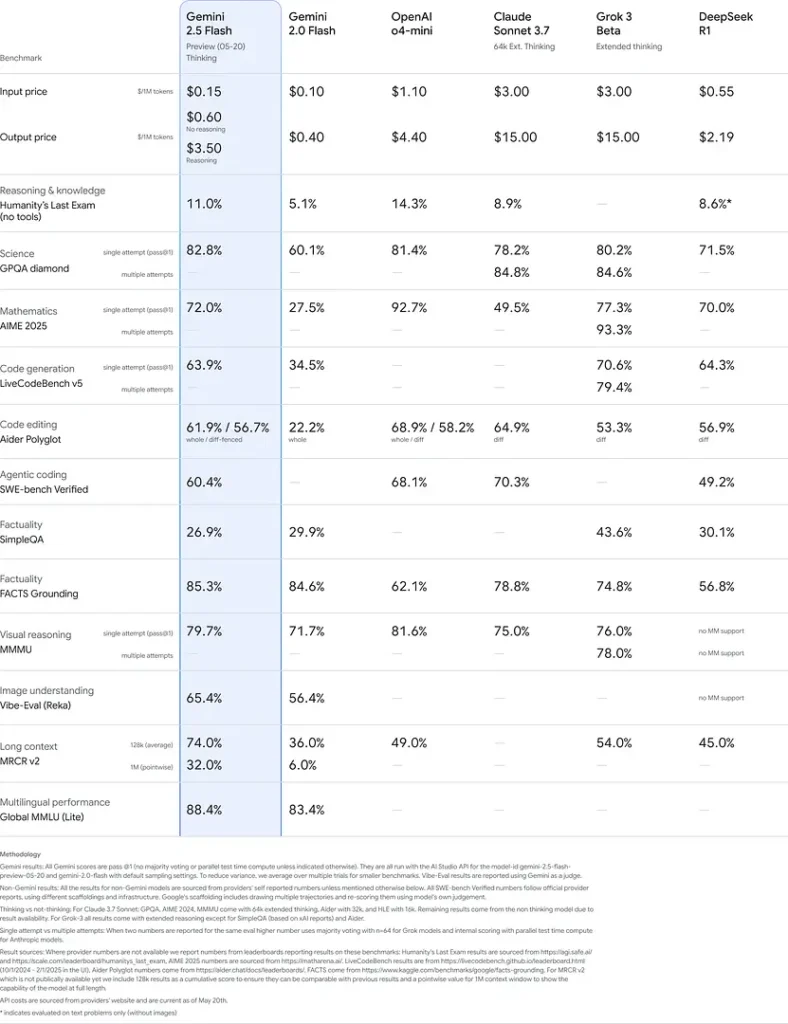
벤치마크 성능
엄격한 평가에서 Gemini 2.5 Flash는 다음과 같은 성능을 보여줍니다. 업계 최고의 공연:
- LMArena 하드 프롬프트: 득점 2.5 Pro 다음으로 까다로운 Hard Prompts 벤치마크에서 강력한 다단계 추론 능력을 보여주었습니다.
- MMLU 점수 0.809: 평균 모델 성능을 초과합니다. 0.809 MMLU의 정확도는 광범위한 도메인 지식과 추론 능력을 반영합니다.
- 대기 시간 및 처리량: 달성하다 271.4개 토큰/초 디코딩 속도 **첫 번째 토큰 생성 시간(0.29초)**따라서 지연 시간에 민감한 작업에 이상적입니다.
- 가격 대비 성능 리더: 에서 $0.26/1M 토큰플래시는 주요 벤치마크에서 경쟁사들과 동등하거나 앞지르는 성과를 거두는 동시에 많은 경쟁사보다 낮은 가격을 제시합니다.
이러한 결과는 Gemini 2.5 Flash가 추론, 과학적 이해, 수학적 문제 해결, 코딩, 시각적 해석 및 다국어 기능 측면에서 경쟁 우위를 가지고 있음을 보여줍니다.
제한 사항
Gemini 2.5 Flash는 강력하면서도 특정 기능을 제공합니다. 한계:
- 안전 위험: 모델은 다음을 나타낼 수 있습니다. "설교적인" 어조 특히 예외적인 쿼리의 경우, 그럴듯해 보이지만 부정확하거나 편향된 출력(환각)을 생성할 수 있습니다. 엄격한 인적 감독은 여전히 필수적입니다.
- 속도 제한: API 사용은 속도 제한(기본 계층에서 10 RPM, 250,000 TPM, 250 RPD)으로 제한되며, 이는 일괄 처리나 대용량 애플리케이션에 영향을 미칠 수 있습니다.
- 인텔리전스 플로어: 매우 유능한 동안 플래시 모델은 정확도가 떨어집니다. 2.5 프로 고급 코딩이나 다중 에이전트 조정과 같은 가장 까다로운 에이전트 작업에도 적합합니다.
- 비용 상충: 최고의 서비스를 제공하지만 가격 대비 성능, 광범위한 사용 생각 모드는 전반적인 토큰 소비를 증가시켜 심층적 추론 프롬프트에 대한 비용을 높입니다.
도 참조 제미니 2.5 프로 API
결론
Gemini 2.5 Flash는 AI 기술 발전에 대한 Google의 헌신을 보여주는 증거입니다. 강력한 성능, 멀티모달 기능, 효율적인 리소스 관리를 통해 운영에 인공지능의 힘을 활용하고자 하는 개발자와 조직에 포괄적인 솔루션을 제공합니다.
전화하는 방법 Gemini 2.5 Flash CometAPI의 API
Gemini 2.5 Flash CometAPI의 API 가격 책정, 공식 가격 대비 20% 할인:
- 입력 토큰: $0.24 / M 토큰
- 출력 토큰: $0.96/M 토큰
필수 단계
- 에 로그인 코메타피닷컴. 아직 당사 사용자가 아니신 경우 먼저 등록해 주시기 바랍니다.
- 인터페이스의 액세스 자격 증명 API 키를 받으세요. 개인 센터의 API 토큰에서 "토큰 추가"를 클릭하고 토큰 키(sk-xxxxx)를 받아 제출하세요.
- 이 사이트의 url을 받으세요: https://api.cometapi.com/
사용 방법
- "**
gemini-2.5-flash**API 요청을 전송하고 요청 본문을 설정하는 엔드포인트입니다. 요청 메서드와 요청 본문은 웹사이트 API 문서에서 확인할 수 있습니다. 웹사이트에서는 사용자의 편의를 위해 Apifox 테스트도 제공합니다. - 바꾸다 귀하 계정의 실제 CometAPI 키를 사용합니다.
- 질문이나 요청을 콘텐츠 필드에 입력하세요. 모델이 이에 응답합니다.
- . API 응답을 처리하여 생성된 답변을 얻습니다.
Comet API의 모델 런칭 정보는 다음을 참조하세요. https://api.cometapi.com/new-model.
Comet API의 모델 가격 정보는 다음을 참조하세요. https://api.cometapi.com/pricing.
API 사용 예
개발자는 다음과 상호 작용할 수 있습니다. 제미니-2.5-플래시 CometAPI API를 통해 다양한 애플리케이션과의 통합이 가능합니다. 아래는 Python 예제입니다.
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
이 스크립트는 프롬프트를 보냅니다. Gemini 2.5 Flash 생성된 응답을 모델화하고 인쇄하여 활용 방법을 보여줍니다. Gemini 2.5 Flash 복잡한 설명에 대해서는.