

GLM-4.6 Z.ai(구 Zhipu AI)의 GLM 제품군의 최신 주요 릴리스입니다. 4세대 대규모 언어 MoE(전문가 혼합) 모델 조정됨 에이전트 워크플로, 장기 컨텍스트 추론 및 실제 코딩. 이 릴리스에서는 매우 큰 규모의 실용적인 에이전트/도구 통합을 강조합니다. 상황에 맞는 창, 그리고 지역 배포를 위한 개방형 가용성.
주요 기능
- 긴 맥락 - 토종의 200K 토큰 컨텍스트 창(128K에서 확장됨). ()
- 코딩 및 에이전트 기능 — 실제 코딩 작업에 대한 개선 사항과 에이전트를 위한 더 나은 도구 호출 기능을 시장에 내놓았습니다.
- 효율성: — 보고됨 토큰 소비량 약 30% 감소 Z.ai 테스트에서 GLM-4.5와 비교.
- 배포 및 양자화 — Cambricon 칩에 대한 FP8 및 Int4 통합을 처음 발표했습니다. vLLM을 통해 Moore Threads에서 기본적으로 FP8을 지원합니다.
- 모델 크기 및 텐서 유형 — 게시된 아티팩트는 다음을 나타냅니다. ~357B-매개변수 Hugging Face의 모델(BF16 / F32 텐서).
기술적 세부 사항
모달리티 및 형식. GLM-4.6은 텍스트 전용 LLM(입력 및 출력 방식: 텍스트). 컨텍스트 길이 = 200K 토큰; 최대 출력 = 128K 토큰.
양자화 및 하드웨어 지원. 팀 보고 FP8/Int4 양자화 Cambricon 칩과 네이티브 FP8 추론을 위해 vLLM을 사용하여 Moore Threads GPU에서 실행합니다. 이는 추론 비용을 낮추고 온프레미스 및 국내 클라우드 배포를 허용하는 데 중요합니다.
툴링 및 통합. GLM-4.6은 Z.ai의 API, 타사 공급자 네트워크(예: CometAPI)를 통해 배포되고 코딩 에이전트(Claude Code, Cline, Roo Code, Kilo Code)에 통합됩니다.
기술적 세부 사항
모달리티 및 형식. GLM-4.6은 텍스트 전용 LLM(입력 및 출력 방식: 텍스트). 컨텍스트 길이 = 200K 토큰; 최대 출력 = 128K 토큰.
양자화 및 하드웨어 지원. 팀 보고 FP8/Int4 양자화 Cambricon 칩과 네이티브 FP8 추론을 위해 vLLM을 사용하여 Moore Threads GPU에서 실행합니다. 이는 추론 비용을 낮추고 온프레미스 및 국내 클라우드 배포를 허용하는 데 중요합니다.
툴링 및 통합. GLM-4.6은 Z.ai의 API, 타사 공급자 네트워크(예: CometAPI)를 통해 배포되고 코딩 에이전트(Claude Code, Cline, Roo Code, Kilo Code)에 통합됩니다.
벤치마크 성능
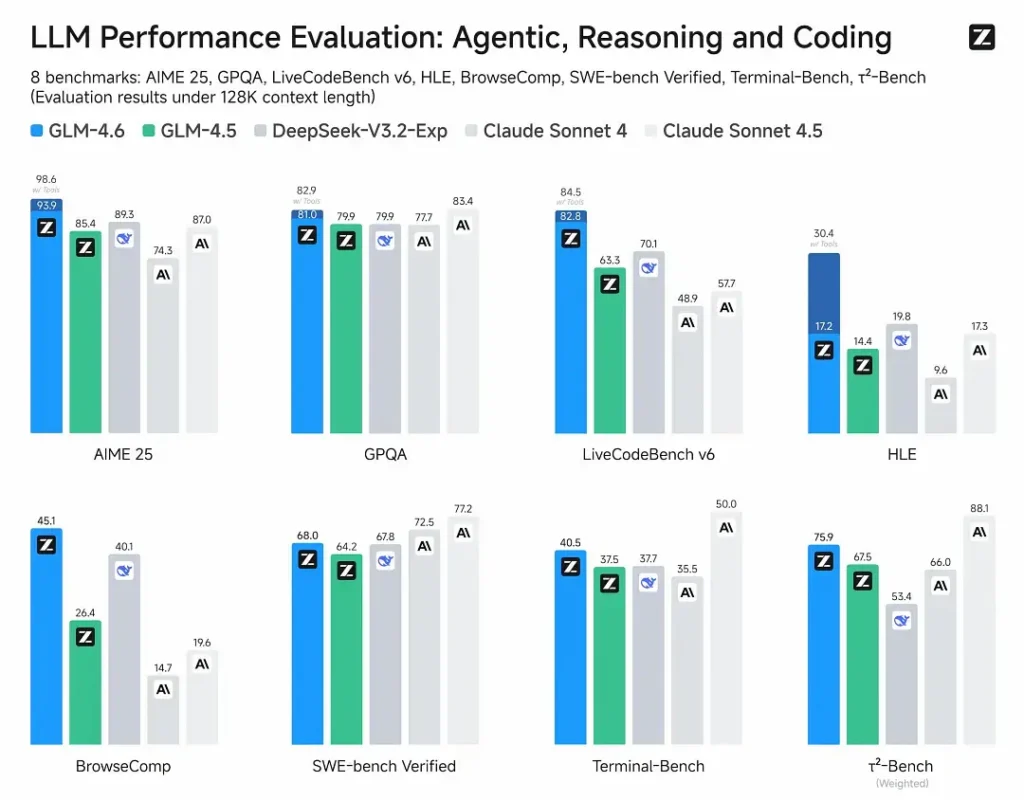
- 게시된 평가: GLM-4.6은 에이전트, 추론 및 코딩을 포함하는 8개의 공개 벤치마크에서 테스트되었으며 다음을 보여줍니다. GLM-4.5에 비해 뚜렷한 이득. 인간이 평가한 실제 코딩 테스트(확장 CC-Bench)에서 GLM-4.6은 다음을 사용합니다. 토큰이 약 15% 감소 vs GLM-4.5 및 게시물 승률 약 48.6% vs Anthropic의 클로드 소네트 4 (많은 리더보드에서 거의 동등한 수준).
- 위치 : 결과에 따르면 GLM-4.6은 국내 및 해외의 주요 모델과 경쟁력이 있는 것으로 나타났습니다(예시로는 DeepSeek-V3.1과 Claude Sonnet 4가 있습니다).
제한 사항 및 위험
- 환각과 실수: 모든 현행 LLM과 마찬가지로 GLM-4.6도 사실 오류가 발생할 수 있으며, 실제로 발생합니다. Z.ai 문서에서는 출력 결과에 오류가 포함될 수 있다고 명시적으로 경고하고 있습니다. 사용자는 중요한 콘텐츠에 대해 검증 및 검색/RAG를 적용해야 합니다.
- 모델 복잡도 및 서비스 비용: 200만 개의 컨텍스트와 매우 큰 출력으로 인해 메모리 및 대기 시간 요구 사항이 크게 증가하고 추론 비용이 높아질 수 있습니다. 대규모로 실행하려면 양자화/추론 엔지니어링이 필요합니다.
- 도메인 갭: GLM-4.6은 강력한 에이전트/코딩 성능을 보고하지만 일부 공개 보고서는 여전히 다음과 같이 언급합니다. 특정 버전에서는 지연이 발생합니다 특정 마이크로벤치마크에서 경쟁 모델의 비교(예: 일부 코딩 지표와 Sonnet 4.5 비교). 프로덕션 모델을 교체하기 전에 작업별로 평가합니다.
- 안전 및 정책: 개방형 가중치는 접근성을 높이지만 관리 문제도 제기합니다(완화책, 가드레일, 레드팀 구성은 여전히 사용자의 책임입니다).
사용 사례
- 에이전트 시스템 및 도구 오케스트레이션: 긴 에이전트 추적, 다중 도구 계획, 동적 도구 호출; 모델의 에이전트 튜닝은 주요 판매 포인트입니다.
- 실제 코딩 지원 도구: 멀티턴 코드 생성, 코드 검토 및 대화형 IDE 어시스턴트(Z.ai에 따라 Claude Code, Cline, Roo Code에 통합됨) 토큰 효율성 개선 개발자가 많이 사용하는 계획에 적합하도록 만들어줍니다.
- 긴 문서 워크플로: 요약, 다중 문서 합성, 200K 창으로 인한 긴 법률/기술 검토.
- 콘텐츠 제작 및 가상 캐릭터: 확장된 대화, 여러 턴에 걸친 시나리오에서 일관된 페르소나 유지.
GLM-4.6이 다른 모델과 비교되는 방식
- GLM-4.5 → GLM-4.6: 단계적 변화 컨텍스트 크기(128K → 200K) 및 토큰 효율성(CC-Bench에서 토큰이 약 15% 더 적음); 에이전트/도구 사용이 개선되었습니다.
- GLM-4.6 대 클로드 소네트 4 / 소네트 4.5: Z.ai 보고서 여러 리더보드에서 거의 동등 수준 CC-Bench 실제 코딩 작업에서 약 48.6%의 승률을 기록했습니다(즉, Sonnet이 여전히 앞서는 일부 마이크로벤치마크와 치열한 경쟁을 벌이고 있습니다). 많은 엔지니어링 팀에게 GLM-4.6은 비용 효율적인 대안으로 자리매김하고 있습니다.
- GLM-4.6 대 기타 장기 컨텍스트 모델(DeepSeek, Gemini 변형, GPT-4 제품군): GLM-4.6은 대규모 컨텍스트 및 에이전트 코딩 워크플로우를 강조합니다. 상대적인 강점은 지표(토큰 효율성/에이전트 통합 vs. 원시 코드 합성 정확도 또는 안전 파이프라인)에 따라 달라집니다. 경험적 선택은 작업 중심적이어야 합니다.
Zhipu AI의 최신 플래그십 모델 GLM-4.6 출시: 총 매개변수 355B개, 활성 매개변수 32B개. 모든 핵심 기능에서 GLM-4.5를 능가합니다.
- 코딩: 정렬 클로드 소네트 4중국 최고.
- 컨텍스트: 200K로 확장됨(128K에서).
- 추론: 개선되었으며, 추론 중 도구 호출을 지원합니다.
- 검색: 향상된 도구 호출 및 에이전트 성과.
- 글쓰기: 스타일, 가독성, 롤플레잉 측면에서 인간의 선호도에 더 잘 부합합니다.
- 다국어: 언어 간 번역이 강화되었습니다.
전화하는 방법 GLM-**4.**CometAPI의 6개 API
GLM‑4.6 CometAPI의 API 가격 책정, 공식 가격 대비 20% 할인:
- 입력 토큰: $0.64M 토큰
- 출력 토큰: $2.56/M 토큰
필수 단계
- 에 로그인 코메타피닷컴. 아직 당사 사용자가 아니시라면, 먼저 등록해 주시기 바랍니다.
- 에 로그인하여 CometAPI 콘솔.
- 인터페이스의 액세스 자격 증명 API 키를 받으세요. 개인 센터의 API 토큰에서 "토큰 추가"를 클릭하고 토큰 키(sk-xxxxx)를 받아 제출하세요.

사용 방법
- "
glm-4.6API 요청을 전송하고 요청 본문을 설정하는 엔드포인트입니다. 요청 메서드와 요청 본문은 웹사이트 API 문서에서 확인할 수 있습니다. 웹사이트에서는 사용자의 편의를 위해 Apifox 테스트도 제공합니다. - 바꾸다 귀하 계정의 실제 CometAPI 키를 사용합니다.
- 질문이나 요청을 콘텐츠 필드에 입력하세요. 모델이 이에 응답합니다.
- . API 응답을 처리하여 생성된 답변을 얻습니다.
CometAPI는 완벽한 호환성을 갖춘 REST API를 제공하여 원활한 마이그레이션을 지원합니다. 주요 세부 정보는 다음과 같습니다. API doc:
- 기본 URL: https://api.cometapi.com/v1/chat/completions
- 모델명 : "
glm-4.6" - 입증:
Bearer YOUR_CometAPI_API_KEY머리글 - 컨텐츠 타입:
application/json.
API 통합 및 예제
아래는 Python CometAPI API를 통해 GLM‑4.6을 호출하는 방법을 보여주는 스니펫입니다. <API_KEY> 및 <PROMPT> 따라서:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
주요 매개 변수:
- 모델: GLM‑4.6 변형을 지정합니다.
- max_tokens: 출력 길이를 제어합니다
- 온도: 창의성과 결정론을 조정합니다.
참조 클로드 소네트 4.5