GPT-4o 오디오 API: 통일된 /chat/completions Opus로 인코딩된 오디오(및 텍스트) 입력을 허용하고 구성 가능한 매개변수(모델=)를 사용하여 합성된 음성 또는 대본을 반환하는 엔드포인트 확장gpt-4o-audio-preview-<date>, speed, temperature) 일괄 및 스트리밍 음성 상호작용을 위한 기능입니다.
GPT-4o 오디오 기본 정보
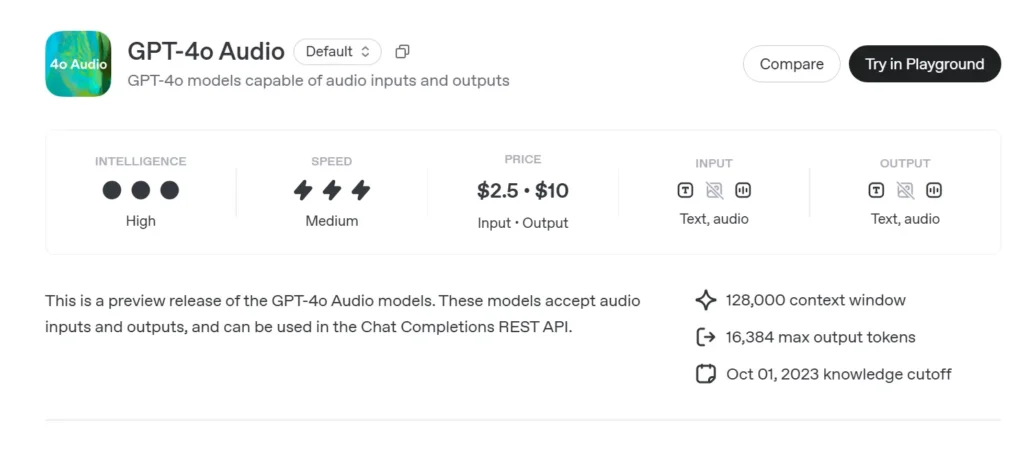
GPT-4o 오디오 미리보기 (gpt-4o-audio-preview-2025-06-03)는 OpenAI의 최신 제품입니다. 음성 중심 대규모 언어 모델 표준을 통해 제공됨 채팅 완료 API 초저지연 실시간 채널이 아닌. GPT-4o와 동일한 "옴니" 기반을 기반으로 구축된 이 변형은 고음질 음성 입력 및 출력 턴 기반 대화, 콘텐츠 제작, 접근성 도구, 그리고 밀리초 단위의 시간 측정이 필요 없는 에이전트 워크플로를 위한 솔루션입니다. GPT-4 클래스 모델의 모든 텍스트 추론 강점을 계승하는 동시에 종단간 음성 대 음성(S2S) 파이프라인, 결정론적 함수 호출, 그리고 새로운 speed 매개 변수 음성 속도 제어를 위해.
GPT-4o 오디오의 핵심 기능 세트
• 통합 음성 대 음성 처리 – 오디오는 의미가 풍부한 토큰으로 직접 변환되고, 추론되며, 외부 STT/TTS 서비스 없이 재합성되어 다음과 같은 결과를 제공합니다. 일관된 음성 음색, 음조 및 맥락 유지.
• 향상된 지시 준수 – 2025년 XNUMX월 튜닝 제공 +19 pp 패스-앳-1 2024년 4월 기준 GPT-XNUMXo 대비 음성 명령 작업에서 환각 현상이 감소하여 고객 지원 및 콘텐츠 초안 작성과 같은 분야에서 환각 현상이 감소했습니다.
• 안정적인 도구 호출 – 모델 출력 구조화된 JSON OpenAI 함수 호출 스키마를 준수하여 백엔드 API(검색, 예약, 지불)를 트리거할 수 있습니다. >95% 인수 정확도.
• speed 매개변수(0.25–4×) – 개발자는 느린 속도의 학습, 일반 내레이션 또는 빠른 "가청 스킴" 모드에 맞게 음성 재생을 조절할 수 있습니다. 없이 외부에서 텍스트를 재합성합니다.
• 방해 인식 턴테이킹 – Realtime 변형만큼 지연 시간이 길지는 않지만 미리보기는 다음을 지원합니다. 부분 스트리밍: 토큰은 계산되자마자 방출되므로, 사용자는 필요한 경우 조기에 중단할 수 있습니다.
GPT-4o의 기술 아키텍처
• 싱글 스택 변압기 – 모든 GPT-4o 파생 제품과 마찬가지로 오디오 미리보기는 다음을 사용합니다. 통합 인코더-디코더 텍스트와 음향 토큰이 동일한 주의 블록을 통과하여 교차 모달 접지를 촉진합니다.
• 계층적 오디오 토큰화 – Raw 16 kHz PCM → log-mel 패치 → 거친 음향 코드 → 의미 토큰. 이 다단계 압축은 다음을 달성합니다. 40~50배 대역폭 감소 뉘앙스를 유지하면서 컨텍스트 창당 여러 분 분량의 클립을 사용할 수 있습니다.
• NF4 양자화된 가중치 – 추론은 다음에서 제공됩니다. 4비트 일반 부동 소수점 정밀도, fp16에 비해 GPU 메모리를 절반으로 줄이고 유지 70개 이상의 스트리밍 RTF(실시간 요소) A100-80GB 노드에서.
• 스트리밍 주의 및 KV 캐싱 – 슬라이딩 윈도우 회전 임베딩은 음성의 ~30초 동안 컨텍스트를 유지하면서도 오(L) 메모리 사용량이 적어 팟캐스트 편집자나 보조 독서 도구에 적합합니다.
버전 관리 및 명명 — 날짜가 찍힌 빌드가 있는 미리보기 트랙
| 확인 | 채널 | 목적 | 날짜를 풀어 | 안정 |
|---|---|---|---|---|
| gpt-4o-오디오-미리보기-2025-06-03 | 채팅 완료 API | 턴 기반 오디오 상호작용, 에이전트 작업 | 6월 03 2025 | 시사 (피드백을 권장합니다) |
이름의 핵심 요소:
- gpt-4o – 옴니 멀티모달 패밀리.
- 오디오 – 음성 사용 사례에 최적화되었습니다.
- 시사 – API 계약은 발전할 수 있지만 아직 GA는 아닙니다.
- 2025-06-03 – 재현성을 위한 교육 및 배포 스냅샷.
CometAPI에서 GPT-4o 오디오 API를 호출하는 방법
GPT-4o Audio API CometAPI의 API 가격:
- 입력 토큰: $2 / M 토큰
- 출력 토큰: $8 / M 토큰
필수 단계
- 에 로그인 코메타피닷컴. 아직 당사 사용자가 아니신 경우 먼저 등록해 주시기 바랍니다.
- 인터페이스의 액세스 자격 증명 API 키를 받으세요. 개인 센터의 API 토큰에서 "토큰 추가"를 클릭하고 토큰 키(sk-xxxxx)를 받아 제출하세요.
- 이 사이트의 url을 받으세요: https://api.cometapi.com/
사용 방법
- "**
gpt-4o-audio-preview-2025-06-03**요청을 전송하고 요청 본문을 설정하는 엔드포인트입니다. 요청 메서드와 요청 본문은 웹사이트 API 문서에서 확인할 수 있습니다. 웹사이트에서는 사용자의 편의를 위해 Apifox 테스트도 제공합니다. - 바꾸다 귀하 계정의 실제 CometAPI 키를 사용합니다.
- 질문이나 요청을 콘텐츠 필드에 입력하세요. 모델이 이에 응답합니다.
- . API 응답을 처리하여 생성된 답변을 얻습니다.
Comet API의 모델 액세스 정보는 다음을 참조하세요. API doc.
Comet API의 모델 가격 정보는 다음을 참조하세요. https://api.cometapi.com/pricing.
API 워크플로 — 오디오 파트 및 기능 후크를 사용한 채팅 완료
- 입력 형식 -
audio/*MIME 또는base64WAV 청크가 내장됨messages[].content. - 출력 옵션 -
•mode: "text"→ 캡션을 위한 순수 텍스트.
•mode: "audio"→ 반환합니다 스트리밍 타임스탬프가 포함된 Opus 또는 µ-law 페이로드. - 함수 호출 -추가
functions:스키마; 모델이 방출합니다role: "function"JSON 인수를 사용하여 개발자는 도구 호출을 실행하고 선택적으로 결과를 다시 파이프로 전송합니다. - 속도 제어 – 세트
voice.speed=1.25재생 속도를 높이려면 안전 범위 0.25~4.0을 사용합니다. - 토큰/오디오 제한 – 출시 시 128k 컨텍스트(약 4분 분량의 음성) 4096 오디오 토큰 / 8192 텍스트 토큰 어느 쪽이 먼저인지.
샘플 코드 및 API 통합
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Highlights:
- 모델:
"gpt-4o-audio-preview-2025-06-03" - 오디오 열쇠 사용자 이진 스트림을 보낼 메시지
- 속도: 컨트롤 음성 속도 느림(0.5)과 빠름(2.0) 사이
- 온도: 잔액 창의력 대 일관성
기술 지표 — 지연 시간, 품질, 정확도
| 메트릭 | 오디오 미리보기 | GPT-4o(텍스트 전용) | 델타 |
|---|---|---|---|
| 첫 번째 토큰 지연 시간(1-샷) | 1.2들 평균 | 0.35들 | +0.85초 |
| MOS(말의 자연스러움, 5점) | 4.43 | - | - |
| 지시 준수(음성) | 92 % | 73 % | +19pp |
| 함수 호출 인수 정확도 | 95.8 % | 87 % | +8.8pp |
| 단어 오류율(암묵적 STT) | 5.2 % | N / A | - |
| GPU 메모리/스트림(A100-80GB) | 7.1 GB | 14GB(fp16) | -49% |
채팅 완료 스트리밍을 통해 실행된 벤치마크, 배치 크기 = 1.
도 참조 GPT-4o 실시간 API