

GLM-5는 Zhipu AI의 새로운 공개 가중치 기반, 에이전트 중심 파운데이션 모델로, 장기 지향 코딩과 다단계 에이전트를 위해 설계되었습니다. 여러 호스팅된 API(CometAPI 및 공급자 엔드포인트 포함)와 코드·가중치를 포함한 연구 공개 버전으로 제공되며, OpenAI 호환 REST 호출, 스트리밍, SDK를 통해 통합할 수 있습니다.
Z.ai의 GLM-5란?
GLM-5는 Z.ai의 5세대 플래그십 파운데이션 모델로, 에이전트형 엔지니어링(장기 지향 계획, 다단계 도구 사용, 대규모 코드/시스템 설계)에 맞게 설계되었습니다. 2026년 2월 공개된 GLM-5는 총 ~744B 파라미터의 Mixture-of-Experts(MoE) 모델이며, 순전파마다 활성 파라미터는 40B 범위입니다. 아키텍처와 학습 선택은 장문맥 일관성, 도구 호출, 프로덕션 워크로드를 위한 비용 효율적 추론을 우선합니다. 이러한 설계는 GLM-5가 매우 긴 입력에서도 문맥을 보존하며 확장된 에이전트 워크플로우(예: 브라우징 → 계획 → 코드 작성/테스트 → 반복)를 실행하도록 합니다.
주요 기술 하이라이트:
- MoE 아키텍처: 총 ~744B / 활성 ~40B 파라미터; 규모 확대 사전학습(~28.5T 토큰 보고)으로 최전선 폐쇄형 모델과의 격차를 좁힘.
- 장문맥 지원 및 최적화(Deep Sparse Attention, DSA)를 통해 무지한 Dense 스케일링 대비 배포 비용 절감.
- 에이전트형 기능 내장: 도구/함수 호출, 상태 유지 세션 지원, 통합 출력(벤더 UI 내 에이전트 워크플로우의 일부로
.docx,.xlsx,.pdf아티팩트 생성 가능). - 공개 가중치 제공(모델 허브에 가중치 게시) 및 호스팅 액세스 옵션(벤더 API, 추론 마이크로서비스).
GLM-5의 주요 장점은?
에이전트형 계획과 장기 지향 메모리
GLM-5의 아키텍처와 튜닝은 워크플로우 전반에서 일관된 다단계 추론과 메모리를 우선시합니다. 이는 다음에 유리합니다:
- 자율 에이전트(CI 파이프라인, 태스크 오케스트레이터),
- 대형 다중 파일 코드 생성 또는 리팩터링,
- 큰 히스토리를 유지해야 하는 문서 인텔리전스.
대형 컨텍스트 윈도우
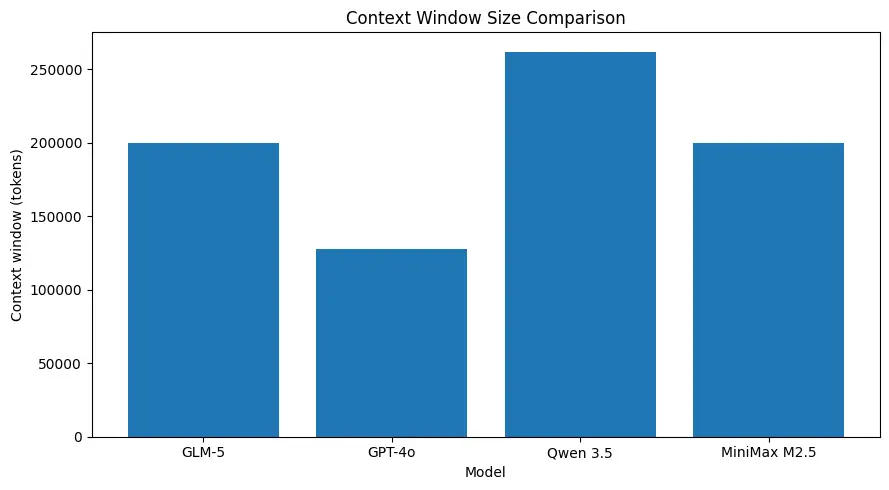
GLM-5는 공개된 모델 사양상 ~200k 토큰 수준의 매우 큰 컨텍스트 크기를 지원하여, 한 요청에 더 많은 세션을 유지하고 많은 사용 사례에서 과도한 청킹이나 외부 메모리 필요성을 줄일 수 있습니다. (아래 비교 차트를 참고하세요.)
시스템 수준 작업에서 강한 코딩 성능
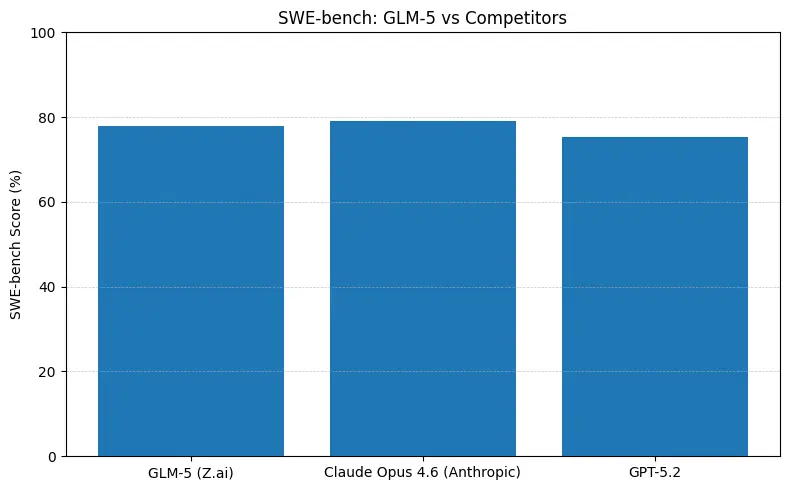
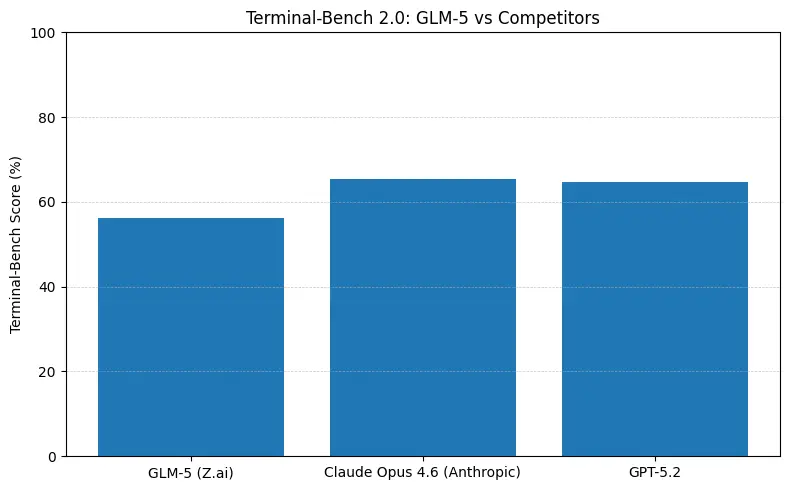
GLM-5는 소프트웨어 엔지니어링 벤치마크(SWE-bench 및 적용 코드 + 에이전트 스위트)에서 오픈 소스 최상위 성능을 보고합니다. SWE-bench-Verified에서는 ~77.8%를 보고하며, 코딩/터미널 스타일 에이전트 테스트(Terminal-Bench 2.0)에서는 중반대(50%대 중반)에 클러스터링합니다 — 이는 실용적 코딩 능력이 최전선의 독점 모델에 근접함을 보여줍니다. 이러한 지표는 GLM-5가 코드 생성, 자동 리팩터링, 다중 파일 추론, CI/CD 어시스턴트 시나리오 같은 작업에 적합함을 의미합니다.
비용/효율 트레이드오프
GLM-5는 MoE와 ‘스파스’ 어텐션 혁신을 사용하므로, 무식한 Dense 스케일링 대비 능력 단위당 추론 비용을 낮추는 것을 목표로 합니다. CometAPI는 대량 처리 에이전트형 워크로드에 적합한 경쟁력 있는 가격을 제공합니다.
CometAPI를 통해 GLM-5 API를 어떻게 사용하나요?
짧은 답: CometAPI를 OpenAI 호환 게이트웨이처럼 사용하세요 — 기본 URL과 API 키를 설정하고, 모델로 glm-5를 선택한 뒤 chat/completions 엔드포인트를 호출하면 됩니다. CometAPI는 OpenAI 스타일의 REST 인터페이스(/v1/chat/completions 같은 엔드포인트)와 SDK, 샘플 프로젝트를 제공하여 마이그레이션을 매우 간단하게 만듭니다.
아래는 실제 프로덕션 지향 요리책입니다: 인증, 기본 채팅 호출, 스트리밍, 함수/도구 호출, 비용/응답 처리.
CometAPI를 통해 GLM-5에 액세스하는 기본 단계:
- CometAPI에 가입하고 API 키를 받습니다.
- CometAPI 카탈로그에서 GLM-5의 정확한 모델 ID를 확인합니다(리스트에 따라
"glm-5"등). - 인증된 POST 요청을 CometAPI의 chat/completions 엔드포인트(OpenAI 스타일)에 보냅니다.
기본 사항(CometAPI 패턴): 플랫폼은 https://api.cometapi.com/v1/chat/completions 같은 OpenAI 스타일 경로, Bearer 인증, model 파라미터, system/user 메시지, 스트리밍을 지원하며, 문서에 curl/python 예제가 있습니다.
예시: GLM-5로 빠른 Python(requests) 채팅 컴플리션
# Python requests 예시(블로킹)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # 키를 안전하게 저장하세요URL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # GLM-5에 대한 CometAPI 모델 식별자 "messages": [ {"role": "system", "content": "당신은 유용한 DevOps 어시스턴트입니다."}, {"role": "user", "content": "매일 /etc를 백업하고 30일간 보관하는 bash 스크립트를 작성하세요."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
예시: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: "application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"다음 아키텍처 문서를 요약하세요..." }], "max_tokens": 600 }'
스트리밍 응답(실용 패턴)
CometAPI는 OpenAI 스타일 스트리밍(SSE/청크)을 지원합니다. Python에서 가장 간단한 접근은 "stream": true를 요청하고 도착하는 응답 데이터를 순차적으로 반복 처리하는 것입니다. 이는 저지연 부분 출력이 필요할 때(실시간 개발 어시스턴트, 스트리밍 UI 구축) 중요합니다.
# 스트리밍(requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"다음 함수에 대한 테스트 스캐폴드를 작성하세요..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # 각 라인은 JSON 청크(OpenAI 호환)입니다. 주의하여 파싱하세요. print(chunk)
참고: OpenAI 스타일 스트리밍 및 CometAPI 호환성 문서.
함수/도구 호출(외부 도구 호출 방법)
GLM-5는 OpenAI/애그리게이터 컨벤션과 호환되는 함수/도구 호출 패턴을 지원합니다(게이트웨이가 모델 응답에서 구조화된 함수 호출을 전달). 사용 예: GLM-5에 로컬 “run_tests” 도구 호출을 요청하면, 파싱·실행 가능한 구조화된 지시를 모델이 반환합니다.
# 요청 예시 조각(의사 JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"단위 테스트를 실행하려면 'run_tests' 도구를 호출할 수 있습니다."}, {"role":"user","content":"리포지토리 X의 테스트를 실행하고 실패를 요약하세요."} ], "functions": [ {"name":"run_tests","description":"리포지토리 루트에서 pytest를 실행합니다","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
모델이 function_call 페이로드를 반환하면 서버 측에서 도구를 실행하고, 도구 결과를 "tool" 역할의 메시지로 다시 전달한 후 대화를 이어가세요. 이 패턴은 안전한 도구 호출과 상태 유지 에이전트 흐름을 가능하게 합니다. 구체적 SDK 헬퍼는 CometAPI 문서와 예시를 참고하세요.
실무 파라미터 및 튜닝
function_call: 구조화된 도구 호출과 더 안전한 실행 흐름을 위해 사용합니다.
temperature: 코드/인프라 같은 결정적 출력에는 0–0.3, 아이데이션에는 더 높게.
max_tokens: 예상 출력 길이에 맞게 설정하세요; GLM-5는 호스팅 시 매우 긴 출력을 지원합니다(벤더 제한은 다를 수 있음).
top_p / nucleus 샘플링: 낮은 확률의 꼬리를 제한하는 데 유용합니다.
stream: 대화형 UI에서는 true.
GLM-5는 Anthropic의 Claude Opus 및 기타 최전선 모델과 어떻게 비교되나요
짧은 답: GLM-5는 에이전트형 및 코딩 벤치마크에서 최전선 폐쇄형 모델과의 격차를 줄이면서, 공개 가중치 배포와 종종 더 나은 호스팅 토큰 비용을 제공합니다. 뉘앙스: 일부 절대 코딩 벤치마크(SWE-bench, Terminal-Bench 변형)에서는 Anthropic의 Claude Opus(4.5/4.6)가 많은 공개 리더보드에서 몇 점 앞서지만 — GLM-5는 매우 경쟁력이 높고 다른 많은 오픈 모델을 능가합니다.
실제에서 숫자가 의미하는 바
- SWE-bench(~코드 정확도/엔지니어링): 공개 리더보드에서 Claude Opus가 소폭 리드(≈79% vs GLM-5 ≈77.8%)를 보입니다; 많은 실제 작업에서 그 격차는 수작업 수정의 감소로 이어지지만, 프로토타이핑이나 대규모 에이전트형 워크플로우에서 아키텍처 선택을 바꿀 정도는 아닐 수 있습니다.
- Terminal-Bench(커맨드라인 에이전트형 작업): Opus 4.6이 리드(≈65.4% vs GLM-5 ≈56.2%) — 터미널 자동화와 분포 외 셸 작업에서 최고 신뢰도를 원한다면, 변두리에서 Opus가 더 나은 편입니다.
- 에이전트형 및 장기 지향: GLM-5는 장기 지향 비즈니스 시뮬레이션(Vending-Bench 2 잔액 $4,432 보고)에서 매우 좋은 성능을 보이며, 다단계 워크플로우에 대한 강한 계획 일관성을 보여줍니다. 제품이 장시간 실행되는 에이전트(금융, 운영)라면 GLM-5가 강력합니다.
GLM-5에서 신뢰도 높은 출력을 얻기 위한 프롬프트와 시스템 설계 방법
시스템 메시지 및 명시적 제약
특히 코드나 도구 호출 작업에서는 GLM-5에 엄격한 역할과 제약을 부여하세요. 예:
{"role":"system","content":"당신은 GLM-5, 전문 엔지니어입니다. PEP8을 따르고 단위 테스트를 포함하는 간결하고 검증된 Python 코드를 반환하세요."}
각 비자명한 변경에 대해 테스트와 짧은 근거를 요청하세요.
복잡한 작업을 분해
“제품 전체를 작성” 대신 다음을 요청하세요:
- 설계 개요,
- 인터페이스 시그니처,
- 구현 및 테스트,
- 최종 통합 스크립트.
이 단계적 분해는 환각을 줄이고 검증 가능한 결정적 체크포인트를 제공합니다.
결정적 코드에는 낮은 온도 사용
코드를 요청할 때는 temperature를 0–0.2로 설정하고 max_tokens를 충분히 크게 잡으세요. 창작 글이나 설계 브레인스토밍에는 온도를 높이세요.
GLM-5 통합 시 모범 사례(CometAPI 또는 직접 호스팅)
프롬프트 엔지니어링 및 시스템 프롬프트
- 에이전트 역할, 도구 접근 정책, 안전 제약을 정의하는 명시적 시스템 지시를 사용하세요. 예: “당신은 시스템 아키텍트입니다: 로컬 단위 테스트가 통과할 때만 변경 제안을 하며, 실행할 정확한 CLI 명령어를 나열합니다.”
- 코딩 작업에서는 리포지토리 컨텍스트(파일 목록, 핵심 코드 스니펫)를 제공하고 가능하면 단위 테스트 출력을 첨부하세요. GLM-5의 장문맥 처리가 도움이 되지만 — 항상 필수 컨텍스트(역할, 작업)를 먼저, 그 다음 지원 자료를 배치하세요.
세션 및 상태 관리
- 장시간 에이전트 대화에는 세션 ID를 사용하고 이전 단계의 “메모리”를 요약 형태로 압축해 컨텍스트 팽창을 방지하세요. CometAPI와 유사 게이트웨이가 세션/상태 헬퍼를 제공하지만 — 장시간 에이전트에서는 애플리케이션 수준 상태 압축이 필수입니다.
도구 및 함수 호출(안전 + 신뢰성)
- 폭이 좁고 감사 가능한 도구 집합만 노출하세요. 사람의 감독 없이 임의 셸 실행을 허용하지 마세요. 구조화된 함수 정의를 사용하고 서버 측에서 인자를 검증하세요.
- 추적 가능성과 사후 디버깅을 위해 도구 호출과 모델 응답을 반드시 로깅하세요.
비용 제어 및 배칭
- 대량 에이전트에는 품질 타협이 가능한 경우 백그라운드 처리를 더 저렴한 모델 변형으로 라우팅하세요(CometAPI에서 모델명을 바꾸면 됩니다). 유사 요청을 배치하고 가능하면
max_tokens를 줄이세요. 입력 대비 출력 토큰 비율을 모니터링하세요 — 출력 토큰이 더 비싼 경우가 많습니다.
지연 및 처리량 엔지니어링
- 대화형 세션에는 스트리밍을 사용하세요. 백그라운드 에이전트 작업에는 async 런타임, 워커 큐, 레이트 리미터를 선호하세요. 셀프 호스팅(공개 가중치) 시에는 MoE 아키텍처에 맞게 가속기 토폴로지를 튜닝하세요 — FPGA/Ascend/특화 실리콘 옵션이 비용 이점을 줄 수 있습니다.
마무리 노트
GLM-5는 에이전트형 엔지니어링을 향한 실용적 공개 가중치 진전입니다: 대형 컨텍스트 윈도우, 계획 능력, 강한 코드 성능으로 개발자 도구, 에이전트 오케스트레이션, 시스템 수준 자동화에 매력적인 선택지입니다. 빠른 통합에는 CometAPI를 사용하고, 관리형 호스팅에는 클라우드 모델 가든을 고려하세요; 항상 자체 워크로드로 검증하고 비용 및 환각 제어를 철저히 계측하세요.
개발자는 지금 GLM-5를 CometAPI를 통해 액세스할 수 있습니다. 시작하려면 Playground에서 모델 기능을 탐색하고 자세한 지침은 API guide를 참고하세요. 액세스 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인하세요. CometAPI는 공식 가격보다 훨씬 낮은 가격을 제공하여 통합을 돕습니다.
Ready to Go?→ 오늘 M2.5에 가입하기