

CometAPI를 통해 Gemini 2.5 Flash-Lite를 시작하는 것은 현재 사용 가능한 가장 비용 효율적이고 지연 시간이 짧은 생성 AI 모델 중 하나를 활용할 수 있는 흥미로운 기회입니다. 이 가이드는 Google DeepMind의 최신 발표 내용, Vertex AI 문서의 상세 사양, 그리고 CometAPI를 활용한 실질적인 통합 단계를 결합하여 빠르고 효과적으로 시작하고 실행할 수 있도록 도와줍니다.
Gemini 2.5 Flash-Lite란 무엇이고 왜 구매해야 할까요?
Gemini 2.5 제품군 개요
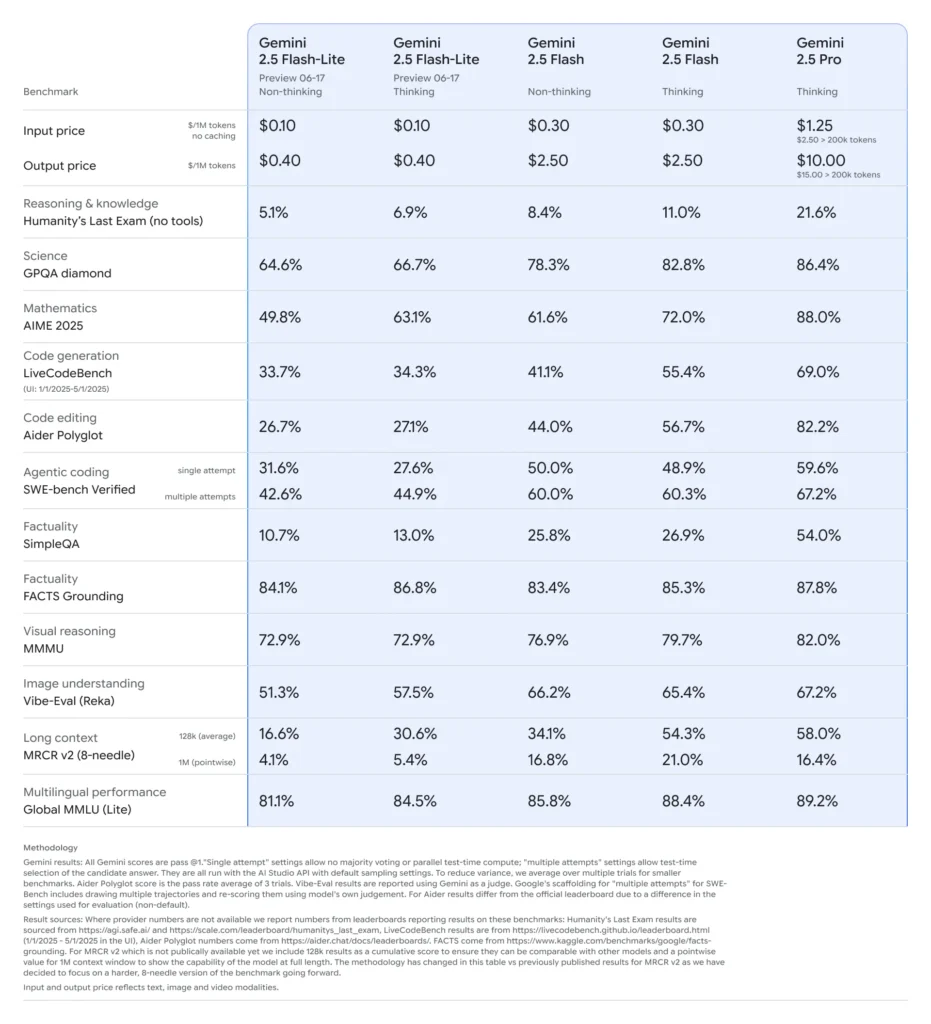
2025년 2.5월 중순, 구글 딥마인드는 제미니 2.5 시리즈를 공식 출시했습니다. 여기에는 제미니 2.5 프로와 제미니 2.5 플래시의 안정적인 GA 버전과 완전히 새롭고 가벼운 모델인 제미니 2.5 플래시-라이트의 미리보기가 포함됩니다. 속도, 비용, 성능의 균형을 맞추도록 설계된 XNUMX 시리즈는 고부하 연구 워크로드부터 대규모 비용에 민감한 배포까지 광범위한 사용 사례를 충족하려는 구글의 노력을 보여줍니다.
Flash-Lite의 주요 특징
Flash-Lite는 최대 100만 개의 토큰을 지원하는 컨텍스트 윈도우와 Google 검색, 코드 실행, 함수 호출을 포함한 도구 통합을 통해 텍스트, 이미지, 오디오, 비디오 등 멀티모달 기능을 매우 낮은 지연 시간으로 제공한다는 점에서 차별화됩니다. Flash-Lite는 "사고 예산(Thought Budget)" 제어 기능을 도입하여 개발자가 내부 토큰 예산 매개변수를 조정함으로써 추론의 깊이와 응답 시간 및 비용 간의 균형을 유지할 수 있도록 합니다.
모델 라인업에서의 포지셔닝
Flash-Lite는 형제 제품과 비교했을 때 비용 효율성 측면에서 파레토 경계에 위치합니다. 미리보기 기간 동안 입력 토큰 백만 개당 약 0.10달러, 출력 토큰 백만 개당 약 0.40달러로, Flash($0.30/$2.50)와 Pro($1.25/$10)보다 저렴하면서도 다중 모드 기능과 함수 호출 지원은 대부분 그대로 유지합니다. 따라서 Flash-Lite는 요약, 분류, 경량 대화형 에이전트와 같이 처리량이 많고 복잡도가 낮은 작업에 이상적입니다.
개발자들이 Gemini 2.5 Flash-Lite를 고려해야 하는 이유는 무엇입니까?
성능 벤치마크 및 실제 테스트
직접 비교에서 Flash-Lite는 다음과 같은 특징을 보였습니다.
- 2배 더 빠른 처리량 분류 작업에서는 Gemini 2.5 Flash보다 우수합니다.
- 3배 비용 절감 기업 규모의 요약 파이프라인을 위해.
- 경쟁력 있는 정확성 논리, 수학, 코드 벤치마크에서 기존 Flash-Lite 미리보기와 동등하거나 더 나은 성능을 보였습니다.
이상적인 사용 사례
- 대용량 챗봇: 수백만 명의 사용자에게 일관되고 지연 시간이 짧은 대화 경험을 제공합니다.
- 자동화된 콘텐츠 생성: 문서 요약, 번역, 마이크로 카피 작성을 확장합니다.
- 검색 및 추천 파이프라인: 실시간 개인화를 위해 빠른 추론을 활용합니다.
- 일괄 데이터 처리: 최소한의 컴퓨팅 비용으로 대용량 데이터 세트에 주석을 추가합니다.
CometAPI를 통해 Gemini 2.5 Flash-Lite에 대한 API 액세스를 얻고 관리하려면 어떻게 해야 합니까?
게이트웨이로 CometAPI를 사용하는 이유는 무엇입니까?
CometAPI는 Google의 Gemini 시리즈를 포함한 500개 이상의 AI 모델을 통합 REST 엔드포인트로 통합하여 제공업체 간 인증, 속도 제한 및 청구를 간소화합니다. 여러 기본 URL과 API 키를 사용하는 대신 모든 요청을 https://api.cometapi.com/v1, 페이로드에서 대상 모델을 지정하고 단일 대시보드를 통해 사용을 관리합니다.
필수 조건 및 가입
- 에 로그인 코메타피닷컴. 아직 당사 사용자가 아니신 경우 먼저 등록해 주시기 바랍니다.
- 인터페이스의 액세스 자격 증명 API 키를 받으세요. 개인 센터의 API 토큰에서 "토큰 추가"를 클릭하고 토큰 키(sk-xxxxx)를 받아 제출하세요.
- 이 사이트의 url을 받으세요: https://api.cometapi.com/
토큰 및 할당량 관리
CometAPI 대시보드는 Google, OpenAI, Anthropic 및 기타 모델에서 공유할 수 있는 통합 토큰 할당량을 제공합니다. 내장된 모니터링 도구를 사용하여 사용량 알림 및 요금 한도를 설정하여 예산 할당량을 초과하거나 예상치 못한 요금이 발생하는 것을 방지하세요.
CometAPI 통합을 위해 개발 환경을 어떻게 구성하시나요?
필수 종속성 설치
Python 통합을 위해 다음 패키지를 설치하세요.
pip install openai requests pillow
- Openai: CometAPI와 통신하기 위한 호환 SDK입니다.
- 요청: 이미지 다운로드 등의 HTTP 작업용입니다.
- 베개: 다중 모드 입력을 보낼 때 이미지를 처리합니다.
CometAPI 클라이언트 초기화
환경 변수를 사용하여 API 키를 소스 코드에 포함하지 마세요.
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
이 클라이언트 인스턴스는 이제 ID를 지정하여 지원되는 모든 모델을 타겟으로 지정할 수 있습니다(예: gemini-2.5-flash-lite-preview-06-17) 귀하의 요청에 따라.
사고 예산 및 기타 매개변수 구성
요청을 보낼 때 다음과 같은 선택적 매개변수를 포함할 수 있습니다.
- 온도/최고_p: 생성 시 무작위성을 제어합니다.
- 후보자수: 대체 출력의 수.
- max_tokens: 출력 토큰 캡.
- 생각_예산: 속도와 비용에 따라 깊이를 조절하는 Flash-Lite의 사용자 정의 매개변수입니다.
CometAPI를 통해 Gemini 2.5 Flash-Lite에 대한 기본 요청은 어떻게 되나요?
텍스트 전용 예
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
이 호출은 200ms 이내에 간결한 요약을 반환하므로 챗봇이나 실시간 분석 파이프라인에 이상적입니다.
다중 모달 입력 예
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite는 최대 7MB 이미지를 처리하고 상황에 맞는 설명을 반환하므로 문서 이해, UI 분석 및 자동 보고에 적합합니다.
스트리밍 및 함수 호출과 같은 고급 기능을 어떻게 활용할 수 있나요?
실시간 애플리케이션을 위한 스트리밍 응답
챗봇 인터페이스나 실시간 자막을 사용하려면 스트리밍 API를 사용하세요.
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
이를 통해 대화형 UI에서 인지되는 지연 시간을 줄이면서 부분적인 출력이 가능해짐에 따라 출력을 제공합니다.
구조화된 데이터 출력을 위한 함수 호출
구조화된 응답을 적용하기 위해 JSON 스키마를 정의합니다.
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
이 접근 방식은 JSON 호환 출력을 보장하여 다운스트림 데이터 파이프라인과 통합을 간소화합니다.
Gemini 2.5 Flash-Lite를 사용할 때 성능, 비용, 안정성을 어떻게 최적화하나요?
예산 조정을 생각하다
Flash-Lite의 사고 예산 매개변수를 사용하면 모델이 소모하는 "인지 노력"의 양을 조절할 수 있습니다. 낮은 예산(예: 0)은 속도와 비용을 우선시하는 반면, 높은 예산은 지연 시간과 토큰을 희생하는 대신 더 깊은 추론을 가능하게 합니다.
토큰 한도 및 처리량 관리
- 입력 토큰: 요청당 최대 1,048,576개의 토큰.
- 출력 토큰: 기본 한도는 65,536개입니다.
- 다중 모드 입력: 이미지, 오디오, 비디오 자산을 포함하여 최대 500MB.
대용량 작업 부하에 대한 클라이언트 측 배칭을 구현하고 CometAPI의 자동 크기 조정을 활용하여 수동 개입 없이 버스트 트래픽을 처리합니다.
비용 효율성 전략
- 복잡도가 낮은 작업은 Flash-Lite에 풀링하고, 복잡한 작업에는 Pro나 표준 Flash를 사용합니다.
- CometAPI 대시보드에서 요금 제한과 예산 알림을 사용하여 걷잡을 수 없는 지출을 방지하세요.
- 모델 ID별로 사용량을 모니터링하여 요청당 비용을 비교하고 라우팅 논리를 적절히 조정합니다.
초기 통합 이후의 모범 사례와 다음 단계는 무엇입니까?
모니터링, 로깅 및 보안
- 로깅: 성능 감사를 위해 요청/응답 메타데이터(타임스탬프, 대기 시간, 토큰 사용)를 캡처합니다.
- 알림: CometAPI에서 오류율이나 비용 초과에 대한 임계값 알림을 설정합니다.
- 보안: API 키를 정기적으로 교체하고 안전한 보관소나 환경 변수에 저장합니다.
일반적인 사용 패턴
- 봇봇: 빠른 사용자 질의에는 Flash-Lite를 사용하고 복잡한 후속 조치에는 Pro를 사용하세요.
- 문서 처리: 저렴한 예산으로 PDF나 이미지를 일괄적으로 밤새 분석할 수 있습니다.
- 실시간 분석: 스트리밍 API를 통해 재무 또는 운영 데이터를 스트리밍하여 즉각적인 통찰력을 얻습니다.
더 탐구
- 하이브리드 프롬프팅을 실험해 보세요. 텍스트와 이미지 입력을 결합하여 더욱 풍부한 맥락을 제공합니다.
- 벡터 검색 도구를 Gemini 2.5 Flash-Lite와 통합하여 RAG(검색 증강 생성) 프로토타입을 제작합니다.
- 비용 및 성능 간의 균형을 검증하기 위해 경쟁사 제품(예: GPT-4.1, Claude Sonnet 4)과 비교합니다.
생산에서의 확장
- 전담 할당량 풀과 SLA 보장을 위해 CometAPI의 엔터프라이즈 계층을 활용하세요.
- 실제 사용자를 방해하지 않고 새로운 프롬프트나 예산을 테스트하기 위해 블루-그린 배포 전략을 구현합니다.
- 정기적으로 모델 사용 지표를 검토하여 추가 비용 절감이나 품질 개선 기회를 파악합니다.
시작 가이드
CometAPI는 수백 개의 AI 모델을 일관된 엔드포인트로 통합하는 통합 REST 인터페이스를 제공하며, 내장된 API 키 관리, 사용량 할당량 및 청구 대시보드를 통해 여러 공급업체 URL과 자격 증명을 일일이 관리할 필요가 없습니다.
개발자는 액세스할 수 있습니다 Gemini 2.5 Flash-Lite(미리보기) API(모델: gemini-2.5-flash-lite-preview-06-17)를 통해 코멧API, 나열된 최신 모델은 기사 발행일을 기준으로 합니다. 먼저, 모델의 기능을 살펴보세요. 운동장 그리고 상담하십시오 API 가이드 자세한 내용은 CometAPI를 참조하세요. 접속하기 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인하세요. 코멧API 공식 가격보다 훨씬 낮은 가격을 제공하여 통합을 돕습니다.
몇 단계만 거치면 CometAPI를 통해 Gemini 2.5 Flash-Lite를 애플리케이션에 통합하여 속도, 경제성, 그리고 멀티모달 인텔리전스의 강력한 조합을 경험할 수 있습니다. 설정, 기본 요청, 고급 기능 및 최적화를 포함한 위의 가이드라인을 따르면 사용자에게 차세대 AI 경험을 제공할 수 있는 유리한 위치를 선점할 수 있습니다. 비용 효율적이면서도 처리량이 높은 AI의 미래가 바로 여기에 있습니다. 지금 바로 Gemini 2.5 Flash-Lite를 시작하세요.