기술 세부사항
- Adaptive Reasoning: **
Gemini 2.5 Flash-Lite**는 온디맨드 thinking을 지원하여, 더 깊은 추론이 필요할 때에만 개발자가 연산 자원을 할당할 수 있게 합니다. - Tool Integrations: Grounding with Google Search, Code Execution, URL Context, Function Calling 등을 포함한 Gemini 2.5의 기본 도구와 완전 호환되어 원활한 멀티모달 워크플로를 제공합니다.
- Model Context Protocol (MCP): Google의 MCP를 활용해 실시간 웹 데이터를 가져와 응답이 최신이며 문맥적으로 적절하도록 보장합니다.
- Deployment Options: CometAPI, Gemini API, Vertex AI, Google AI Studio를 통해 이용 가능하며, 얼리 어답터가 실험하고 피드백을 제공할 수 있는 프리뷰 트랙을 제공합니다.
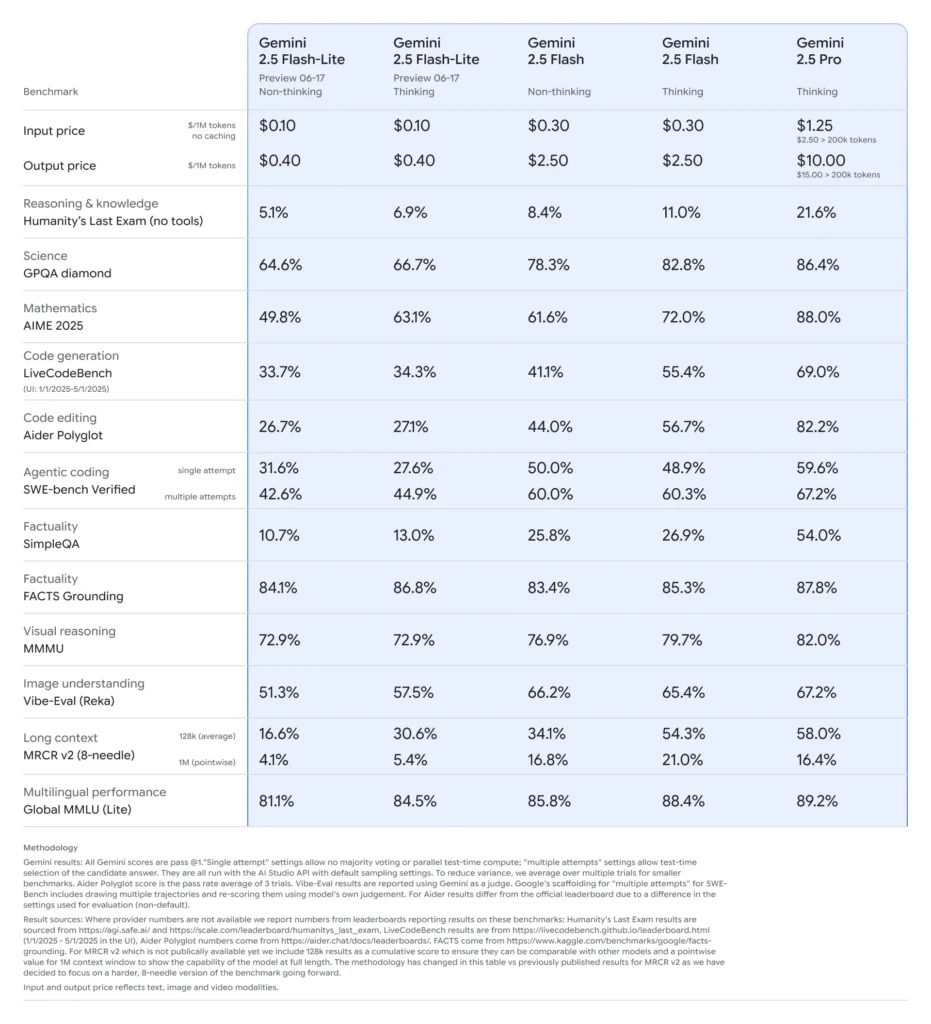
**Gemini 2.5 Flash-Lite**의 벤치마크 성능
- Latency: Gemini 2.5 Flash 대비 중앙 응답 시간이 최대 50% 낮으며, 표준 분류 및 요약 벤치마크에서 일반적으로 100 ms 미만의 지연 시간을 보입니다.
- Throughput: 대용량 워크로드에 최적화되어 분당 수만 건의 요청을 성능 저하 없이 처리합니다.
- Price-Performance: Flash 대비 1,000 토큰당 비용이 25% 절감되어, 비용에 민감한 배포에서 파레토 최적의 선택지입니다.
- Industry Adoption: 초기 사용자들은 프로덕션 파이프라인에 원활히 통합되었고, 성능 지표가 초기 예상과 일치하거나 이를 상회한다고 보고합니다.
적합한 사용 사례
- High-Frequency, Low-Complexity Tasks: 자동 태깅, 감성 분석, 대량 번역
- Cost-Sensitive Pipelines: 대규모 문서 코퍼스에서의 데이터 추출, 주기적 일괄 요약
- Edge and Mobile Scenarios: 지연 시간이 중요하지만 리소스 예산이 제한적인 경우
**Gemini 2.5 Flash-Lite**의 한계
- Preview Status: GA 이전에 API가 변경될 수 있으므로, 통합 시 버전 업 가능성을 고려해야 합니다.
- No On-the-Fly Fine-Tuning: 커스텀 가중치를 업로드할 수 없으며, 프롬프트 엔지니어링과 시스템 메시지에 의존해야 합니다.
- Reduced Creativity: 결정적이고 고처리량 작업에 맞춰 튜닝되어 있어, 개방형 생성이나 “창의적” 글쓰기에는 덜 적합합니다.
- Resource Ceiling: ~16 vCPUs까지 선형적으로 확장되며, 이를 넘어서면 처리량 향상 폭이 줄어듭니다.
- Multimodal Constraints: 이미지/오디오 입력을 지원하지만 충실도가 제한적이어서, 고강도 비전 처리나 오디오 전사 작업에는 적합하지 않습니다.
- Context-Window Trade-Off: 최대 1 M 토큰까지 수용하지만, 그 규모에서의 실제 추론은 처리량이 저하될 수 있습니다.