

빠르게 발전하는 인공지능 환경에서 2025년은 대규모 언어 모델(LLM) 분야에서 상당한 발전을 이루었습니다. 선두 주자로는 알리바바의 Qwen2.5, DeepSeek의 V3 및 R1 모델, 그리고 OpenAI의 ChatGPT가 있습니다. 이러한 각 모델은 고유한 기능과 혁신을 제공합니다. 이 글에서는 Qwen2.5의 최신 개발 동향을 살펴보고, DeepSeek 및 ChatGPT와 기능 및 성능을 비교하여 현재 AI 경쟁에서 어떤 모델이 선두를 달리고 있는지 파악합니다.
Qwen2.5이란 무엇인가요?
회사 개요
Qwen 2.5는 Alibaba Cloud의 최신 고밀도 디코더 전용 대용량 언어 모델로, 0.5B에서 72B까지의 매개변수 크기로 제공됩니다. 명령어 수행, 구조화된 출력(예: JSON, 테이블), 코딩 및 수학 문제 해결에 최적화되어 있습니다. 29개 이상의 언어를 지원하고 최대 128개의 토큰에 달하는 컨텍스트 길이를 제공하는 Qwen 2.5는 다국어 및 도메인별 애플리케이션에 적합하도록 설계되었습니다.
주요 특징
- 다국어 지원: 29개 이상의 언어를 지원하여 글로벌 사용자 기반을 충족합니다.
- 확장된 컨텍스트 길이: 최대 128K 토큰을 처리하여 긴 문서와 대화 처리가 가능합니다.
- 특수 변형: 프로그래밍 작업을 위한 Qwen2.5-Coder와 수학적 문제 해결을 위한 Qwen2.5-Math와 같은 모델이 포함되어 있습니다.
- 접근 용이성: Hugging Face, GitHub 및 새로 출시된 웹 인터페이스와 같은 플랫폼을 통해 사용 가능 채팅.qwenlm.ai.
Qwen 2.5를 로컬로 사용하는 방법은?
다음은 단계별 가이드입니다. 7 B 채팅 체크포인트; 더 큰 크기는 GPU 요구 사항에서만 다릅니다.
1. 하드웨어 전제 조건
| 모델 | 8비트용 vRAM | 4비트용 vRAM(QLoRA) | 디스크 크기 |
|---|---|---|---|
| 퀀 2.5‑7B | 14GB | 10GB | 13GB |
| 퀀 2.5‑14B | 26GB | 18GB | 25GB |
단일 RTX 4090(24GB)은 7비트 정밀도에서 16B 추론에 충분합니다. 이러한 카드 두 개 또는 CPU 오프로드와 양자화를 통해 14B를 처리할 수 있습니다.
2. 설치
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. 빠른 추론 스크립트
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
The trust_remote_code=True Qwen은 맞춤형 제품을 배송하므로 플래그가 필요합니다. 회전 위치 임베딩 싸개.
4. LoRA를 통한 미세 조정
매개변수 효율적인 LoRA 어댑터 덕분에 단일 50GB GPU에서 24시간 이내에 약 XNUMXK 도메인 쌍(예: 의료)에서 Qwen을 전문적으로 훈련할 수 있습니다.
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
생성된 어댑터 파일(~120MB)은 필요에 따라 다시 병합하거나 로드할 수 있습니다.
선택 사항: Qwen 2.5를 API로 실행
CometAPI는 여러 주요 AI 모델의 API를 위한 중앙 허브 역할을 하므로, 여러 API 제공자와 별도로 협력할 필요가 없습니다. 코멧API Qwen API 통합을 위해 공식 가격보다 훨씬 저렴한 가격을 제공하며, 등록 및 로그인 시 계정에 1달러가 적립됩니다! CometAPI에 가입하여 직접 경험해 보세요. Qwen 2.5를 애플리케이션에 통합하려는 개발자 여러분:
1단계: 필요한 라이브러리 설치:
bash
pip install requests
2단계: API 키 얻기
3 단계 : API 호출 구현
API 자격 증명을 활용하여 Qwen 2.5에 요청을 합니다. 귀하 계정의 실제 CometAPI 키를 사용합니다.
예를 들어, Python에서는:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
이 통합을 통해 Qwen 2.5의 기능을 다양한 애플리케이션에 원활하게 통합하여 기능과 사용자 경험을 향상시킬 수 있습니다. “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” API 요청을 전송하고 요청 본문을 설정하는 엔드포인트입니다. 요청 메서드와 요청 본문은 웹사이트 API 문서에서 확인할 수 있습니다. 웹사이트에서는 사용자의 편의를 위해 Apifox 테스트도 제공합니다.
를 참조하십시오 Qwen 2.5 최대 API 통합 세부 정보.CometAPI가 최신 버전을 업데이트했습니다. QwQ-32B APIComet API의 자세한 모델 정보는 다음을 참조하세요. API doc.
모범 사례 및 팁
| 시나리오 | 추천 |
|---|---|
| 긴 문서 Q&A | 지연 시간을 줄이기 위해 구절을 ≤16K 토큰으로 나누고 단순한 100K 컨텍스트 대신 검색 강화 프롬프트를 사용합니다. |
| 구조화된 출력 | 시스템 메시지에 다음을 접두사로 추가합니다. You are an AI that strictly outputs JSON. Qwen 2.5의 정렬 훈련은 제한된 생성에 탁월합니다. |
| 코드 완성 | 세트 temperature=0.0 및 top_p=1.0 결정론을 최대화하려면 여러 빔을 샘플링합니다.num_return_sequences=4) 순위를 매기세요. |
| 안전 필터링 | Alibaba의 오픈 소스 "Qwen‑Guardrails" 정규식 번들이나 OpenAI의 text‑moderation‑004를 첫 번째 방법으로 사용하세요. |
Qwen 2.5의 알려진 제한 사항
- 즉시 주사에 대한 감수성. 외부 감사 결과, Qwen 18‑VL의 탈옥 성공률은 2.5%로 나타났습니다. 이는 단순히 모델 크기만으로는 적대적인 명령에 대한 면역성을 확보할 수 없다는 점을 상기시켜줍니다.
- 라틴 문자가 아닌 OCR 노이즈. 시각 언어 작업에 맞춰 미세 조정한 경우, 모델의 엔드투엔드 파이프라인은 때때로 전통 중국어 문자와 간체 중국어 문자를 혼동하여 도메인별 수정 레이어가 필요할 수 있습니다.
- GPU 메모리가 128K로 클리프됨. FlashAttention‑2는 RAM을 오프셋하지만, 72K 토큰에 걸친 128B 고밀도 포워드 패스는 여전히 120GB 이상의 vRAM을 요구합니다. 실무자는 윈도우 참석 또는 KV 캐시를 사용해야 합니다.
로드맵 및 커뮤니티 생태계
Qwen 팀은 암시했습니다. 퀀 3.0하이브리드 라우팅 백본(Dense + MoE)과 통합 음성-비전-텍스트 사전 학습을 목표로 합니다. 한편, 이 생태계는 이미 다음을 호스팅하고 있습니다.
- Q‑에이전트 – Qwen 2.5‑14B를 정책으로 사용하는 ReAct 스타일의 사고 사슬 에이전트.
- 중국 금융 알파카 – 2.5M개의 규제 서류로 훈련된 Qwen7‑1B의 LoRA.
- Open Interpreter 플러그인 – VS Code에서 GPT‑4를 로컬 Qwen 체크포인트로 바꿉니다.
지속적으로 업데이트되는 체크포인트, 어댑터 및 평가 하네스 목록을 보려면 Hugging Face "Qwen2.5 컬렉션" 페이지를 확인하세요.
비교 분석: Qwen2.5 대 DeepSeek 및 ChatGPT
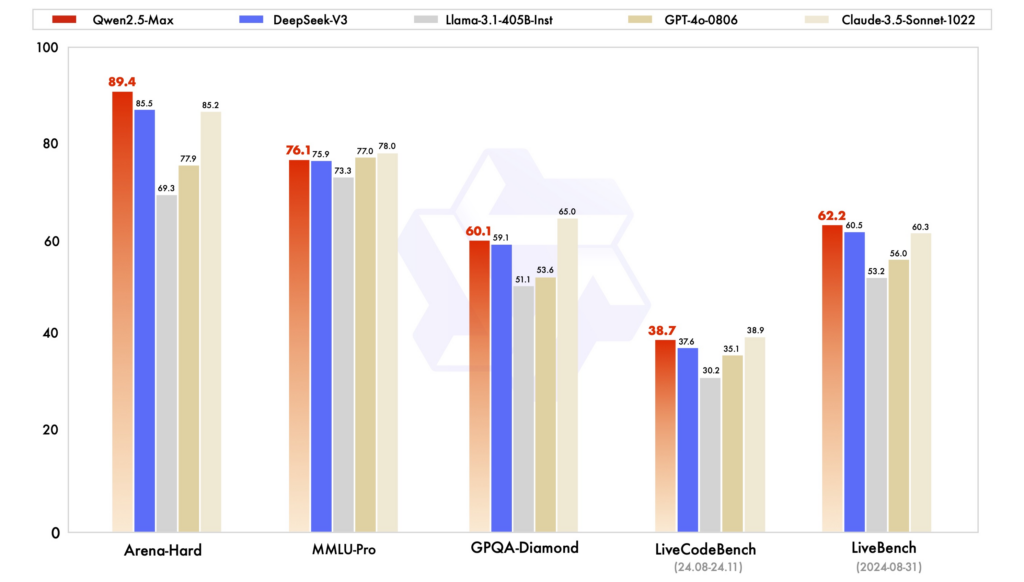
성능 벤치마크: 다양한 평가에서 Qwen2.5는 추론, 코딩, 다국어 이해가 필요한 작업에서 뛰어난 성능을 보였습니다. MoE 아키텍처를 기반으로 하는 DeepSeek-V3는 효율성과 확장성이 뛰어나며, 적은 계산량으로도 높은 성능을 제공합니다. ChatGPT는 특히 범용 언어 작업에서 여전히 강력한 모델로 평가받고 있습니다.
효율성과 비용: DeepSeek 모델은 비용 효율적인 학습 및 추론으로 유명하며, MoE 아키텍처를 활용하여 토큰당 필요한 매개변수만 활성화합니다. Qwen2.5는 밀도가 높지만 특정 작업에 대한 성능을 최적화하는 특수 변형을 제공합니다. ChatGPT의 학습에는 상당한 연산 리소스가 사용되었으며, 이는 운영 비용에도 반영됩니다.
접근성 및 오픈 소스 가용성: Qwen2.5와 DeepSeek은 GitHub 및 Hugging Face와 같은 플랫폼에서 모델을 제공하는 등 다양한 측면에서 오픈 소스 원칙을 수용했습니다. Qwen2.5는 최근 웹 인터페이스를 출시하여 접근성을 더욱 강화했습니다. ChatGPT는 오픈 소스는 아니지만 OpenAI 플랫폼 및 통합 기능을 통해 널리 접근 가능합니다.
결론
Qwen 2.5는 다음 사이의 적절한 지점에 있습니다. 폐쇄형 프리미엄 서비스 및 완전 개방형 취미 모델관대한 라이센싱, 다국어 강점, 장기적 맥락 역량 및 광범위한 매개변수 척도가 결합되어 연구와 생산 모두에 강력한 기반을 제공합니다.
오픈 소스 LLM 환경이 앞으로 나아가면서 Qwen 프로젝트는 다음을 보여줍니다. 투명성과 성과는 공존할 수 있다개발자, 데이터 과학자, 정책 입안자 모두에게 Qwen 2.5를 지금 바로 숙지하는 것은 더욱 다원적이고 혁신 친화적인 AI 미래에 대한 투자입니다.