

Seedance 2.0은 ByteDance의 차세대 AI 비디오 생성 모델로, 2026년 3월에 공식 출시되었습니다. 이 모델은 텍스트, 이미지, 오디오, 비디오 입력을 지원하며, 참조 자료로 최대 9장의 이미지, 3개의 비디오 클립, 3개의 오디오 클립을 사용할 수 있습니다. 또한 디렉터급 제어, 모션 안정성, 오디오-비디오 공동 생성을 목표로 설계되었습니다. 현재 Artificial Analysis의 블라인드 투표 리더보드에서, Seedance 2.0은 오디오 제외 기준 텍스트-투-비디오와 이미지-투-비디오 부문 모두에서 각각 1269와 1351의 Elo 점수로 선두를 달리고 있습니다.
Seedance 2.0이란?
Seedance 2.0은 ByteDance Seed의 차세대 비디오 제작 모델입니다. 공식적으로는 텍스트, 이미지, 오디오, 비디오 입력을 받는 통합 멀티모달 오디오-비디오 공동 생성 아키텍처를 기반으로 구축되었으며, 유례없이 폭넓은 참조 및 편집 기능을 갖춘 크리에이터 도구로 포지셔닝되어 있습니다. Seedance 2.0은 산업급 콘텐츠 워크플로를 위해 설계되었으며, 이전 1.5 버전보다 복잡한 모션 장면에서 더 강한 물리적 정확성, 사실감, 제어 가능성, 안정성을 제공합니다. 주로 텍스트-투-비디오에 집중했던 이전 모델들과 달리, Seedance 2.0은 완전히 통합된 멀티모달 생성 파이프라인을 도입하여 다음을 가능하게 합니다.
- 텍스트-투-비디오 생성
- 이미지-투-비디오 애니메이션
- 비디오-투-비디오 편집
- 오디오 동기화 출력
이로써 2026년에 사용 가능한 가장 포괄적인 AI 비디오 제작 플랫폼 중 하나가 되었습니다.
왜 이것이 중요한가요?
대부분의 비디오 생성기는 여전히 비교적 좁은 워크플로에 최적화되어 있습니다. 즉, 프롬프트를 입력하고 클립을 출력하는 방식입니다. Seedance 2.0은 한 걸음 더 나아가 비디오 생성을 디렉터의 작업 공간처럼 다룹니다. ByteDance에 따르면, 이 모델은 여러 유형의 참조를 동시에 사용할 수 있고, 피사체 일관성을 유지하며, 상세한 지시를 더 충실히 따르고, 심지어 보다 “연출적”인 방식으로 카메라 언어를 계획할 수 있습니다. 이러한 조합이 중요한 이유는 비디오 생성에서 가장 어려운 문제가 단지 미적인 요소만이 아니라, 연속성, 모션 일관성, 시간의 흐름에 따른 전개에 대한 제어이기 때문입니다.
Seedance 2.0의 새로운 점과 주요 기능은 무엇인가요?
통합 멀티모달 생성
가장 중요한 기능은 여러 모달리티를 함께 추론할 수 있는 모델의 능력입니다. Seedance 2.0은 자연어 지시와 함께 최대 9장의 이미지, 3개의 비디오, 3개의 오디오 클립을 참조로 지원하며, 최대 15초 길이의 비디오를 생성할 수 있습니다. 실질적으로 이는 한 번의 생성 과정에서 피사체와 장면뿐만 아니라 모션 스타일, 카메라 움직임, 특수 효과, 오디오 신호까지 모두 제어할 수 있음을 의미합니다.
디렉터급 제어
Seedance 2.0은 ByteDance가 말하는 디렉터급 제어를 중심으로 구축되었습니다. 크리에이터는 참조 이미지, 오디오, 비디오를 사용해 연기, 조명, 그림자, 카메라 움직임을 조형할 수 있습니다. 이 모델은 안정적인 피사체 정체성을 유지하고, 복잡한 스크립트를 정확히 재현하며, 일종의 내장된 “편집 논리”를 반영하는 방식으로 카메라 언어를 선택할 수 있습니다. 크리에이터에게 이는 기본적인 텍스트-투-비디오를 크게 넘어서는 진전입니다.
단순 생성이 아닌 편집 및 확장
또 다른 주목할 만한 업그레이드는 Seedance 2.0이 생성에만 머물지 않는다는 점입니다. Seedance 2.0은 비디오 편집 및 비디오 확장 기능을 추가해 특정 장면, 캐릭터, 동작, 줄거리 포인트를 목표로 변경할 수 있게 하고, 연속적인 후속 샷도 가능하게 합니다. 개발자 문서에서는 이 모델이 처음부터 다시 시작하는 대신 클립을 확장하는 방식으로 “계속 촬영”하는 데도 사용될 수 있다고 설명합니다. 이는 워크플로 효율성 측면에서 중요합니다. 한 구간만 수정하기 위해 전체 장면을 다시 생성할 필요를 줄여주기 때문입니다.
복잡한 모션 처리 향상
Seedance 2.0은 다수의 피사체, 상호작용, 복잡한 움직임이 있는 장면에서 훨씬 더 강력합니다. 생성 품질은 1.5 버전 대비 상당히 향상되었으며, 물리적 정확성, 사실감, 제어 가능성이 더 좋아졌습니다. Seedance 2.0의 어려운 모션 장면에서의 사용 가능률은 내부 평가 기준에서 업계 SOTA 수준에 도달했으며, 동시에 세부 안정성, 사실감, 생동감 측면에서 추가 개선이 여전히 필요하다는 점도 인정하고 있습니다.
성능 벤치마크
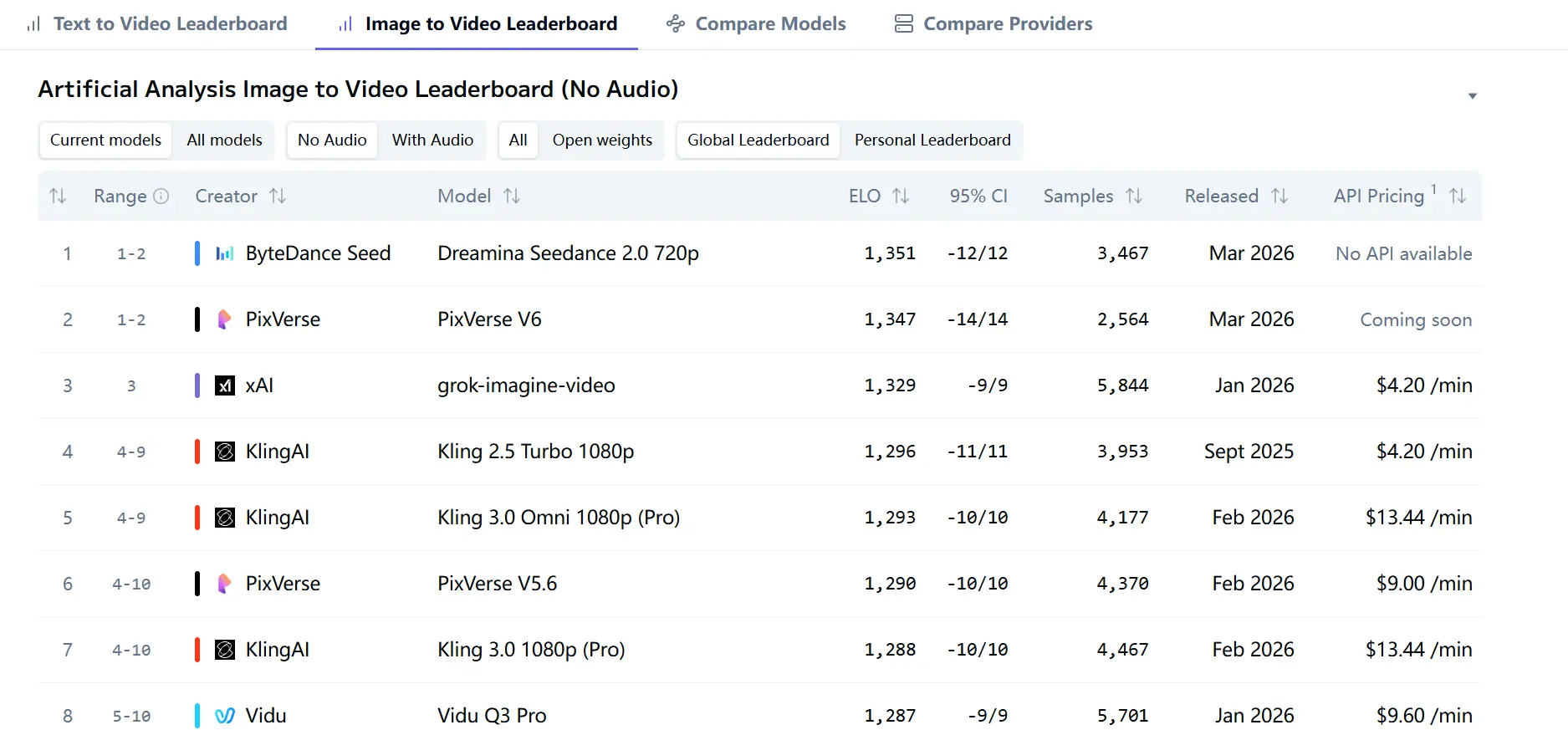
검토한 자료에서 가장 강력한 제3자 신호는 Artificial Analysis Video Arena입니다. 현재 리더보드 페이지에서 Dreamina Seedance 2.0 720p는 오디오 없는 이미지-투-비디오 Arena에서 Elo 1351, 오디오 없는 텍스트-투-비디오 Arena에서 Elo 1269로 선두를 달리고 있습니다. 리더보드 페이지는 또한 순위가 블라인드 사용자 투표를 기반으로 한다고 명시하고 있는데, 이는 모델 내부 지표만이 아니라 대규모 인간 선호도를 측정한다는 점에서 중요합니다.
이는 Seedance 2.0이 단지 성능이 좋다고 마케팅되는 데 그치지 않고, 현재 두 개의 주요 Arena에서 일대일 비교 테스트에서 실제로 사용자에게 더 선호되고 있음을 의미합니다. 오디오 없는 텍스트-투-비디오 부문에서는 Kling 3.0 1080p (Pro), SkyReels V4, PixVerse V6, Kling 3.0 Omni 1080p (Pro)를 앞서고 있습니다. 오디오 없는 이미지-투-비디오 부문에서는 PixVerse V6와 grok-imagine-video를 근소한 차이로 앞서고 있습니다.

Seedance 2.0 성능 스냅샷
| Metric | Seedance 2.0 |
|---|---|
| Image-to-Video Rank | Top 15 globally |
| ELO Score | ~1258 |
| Text-to-Video Rank | Top 25 |
| Cost | ~$1.56/min |
| Strength | Cost-performance balance |
👉 해석:
- 항상 원시 품질 기준 1위는 아님
- 하지만 탁월한 가치 대비 성능 비율
Seedance 2.0은 실제로 얼마나 뛰어난가요?
가장 큰 강점
Seedance 2.0의 가장 큰 강점은 분명합니다. 많은 비디오 모델보다 복잡한 모션을 더 잘 처리하고, 여러 참조 모달리티를 지원하며, 편집과 확장을 제공하고, 현재 오디오 없는 텍스트-투-비디오와 이미지-투-비디오 부문에서 가장 눈에 띄는 공개 Arena 순위를 이끌고 있습니다. 물리적 정확성, 사실감, 제어 가능성의 향상은 모델이 장난감 같은 데모에서 전문 워크플로로 넘어갈 때 정확히 중요한 속성들입니다.
현재의 한계
ByteDance는 Seedance를 완벽한 모델로 제시하지 않습니다. 세부 안정성, 사실감, 모션의 생동감 측면에서는 여전히 개선 여지가 있으며, 다중 피사체 일관성, 텍스트 렌더링 정확도, 복잡한 편집 효과에서도 남아 있는 과제가 있다고 언급합니다.
나의 평가
검토한 자료를 바탕으로 보면, Seedance 2.0은 소폭 업데이트라기보다 실제 프로덕션 준비가 된 비디오 시스템으로 가는 진지한 도약에 가깝습니다. 이 모델의 가장 강력한 근거는 단일한 화려한 데모가 아니라, 더 폭넓은 멀티모달 입력 스택, 직접적인 편집 제어, 클립 확장, 그리고 신뢰할 수 있는 공개 리더보드 선두라는 조합입니다. 이 점에서 Seedance 2.0은 현재 시장에서 가장 중요한 비디오 모델 중 하나이며, 특히 순수한 시네마틱 품질만큼 제어 가능성을 중시하는 팀에게 더욱 그렇습니다.
Seedance 2.0 vs Sora 2 vs Veo 3.1
비교 표 (2026 AI 비디오 리더)
| Feature | Seedance 2.0 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Developer | ByteDance | OpenAI | |
| Input Types | Text, image, audio, video | Text | Text + image |
| Audio Generation | ✅ Native | ❌ Limited | ✅ |
| Max Video Length | 15–20 sec | ~25 sec | ~8 sec (extendable) |
| Editing Capability | ⭐ Advanced (reference-based) | Moderate | Moderate |
| ELO Ranking | Top 15–25 | High | High |
| Cost Efficiency | ⭐ High | Medium | Medium |
| Commercial Use | Yes | Limited (watermark) | Yes |
| Unique Strength | Multimodal editing | Long storytelling | Visual fidelity |
핵심 요약
- Seedance 2.0 = 최고의 편집 + 멀티모달 유연성
- Sora 2 = 최고의 서사 길이
- Veo 3.1 = 최고의 이미지-투-비디오 충실도
현재 Artificial Analysis의 텍스트-투-비디오 순위에서 Seedance 2.0 720p는 오디오 없는 부문에서 Veo 3.1과 Sora 2 Pro를 모두 앞서고 있습니다. 이것이 모든 품질 논쟁을 끝내는 것은 아닙니다. 모델마다 워크플로, 안전 제약, 제품 패키징이 다르기 때문입니다. 하지만 Seedance 2.0이 가장 주목받는 서구권 모델들과 같은 최상위권에 진입했음을 보여줍니다.
Seedance 2.0의 가장 분명한 장점은 입력 범위입니다. ByteDance는 이 모델이 텍스트, 이미지, 오디오, 비디오를 함께 처리할 수 있으며, 한 번에 최대 9장의 이미지, 3개의 비디오, 3개의 오디오 클립을 사용할 수 있다고 말합니다. 반면 OpenAI의 Sora 2 문서는 입력으로 텍스트와 이미지를, 출력으로 비디오와 오디오를 나열하고 있으며, Sora 앱과 sora.com을 통해 접근할 수 있다고 설명합니다. Sora 2 Pro는 웹에서 ChatGPT Pro 사용자에게도 제공됩니다. Google의 Veo 3.1은 그 중간쯤에 위치합니다. 이미지 유도 생성과 오디오가 풍부한 비디오 생성을 중심으로 구축되었으며, 최대 3장의 참조 이미지, 장면 확장, 첫 프레임과 마지막 프레임 제어를 지원합니다.
접근 방법 및 비교할 수 있는 곳
Sora 2, Veo 3.1, 그리고 xx에 하나의 플랫폼에서 동시에 접근하고 싶다면, CometAPI를 추천합니다. CometAPI의 Playgoud는 간단한 명령이나 몇 장의 참조 이미지만으로 직접 비디오를 생성할 수 있게 해줍니다. 자체 비디오 생성 API를 프로그래밍 방식으로 구성하고 싶다면, CometAPI는 더욱 고려할 가치가 있습니다. Sora 2, Veo 3.1 등을 위한 API를 제공하며, 현재 가격은 20% 할인 중입니다.
CometAPI로 Seedance 2.0 사용하는 방법
텍스트-투-비디오 생성
장면에 대한 설명을 입력하세요. 구체적일수록 좋습니다. 카메라 움직임, 조명, 분위기, 스타일을 포함하세요. Seedance 2.0의 강력한 프롬프트 준수 성능 덕분에 출력 결과는 사용자의 의도와 밀접하게 일치하며, 시행착오용이 아니라 실제 콘텐츠 제작에 신뢰할 수 있습니다.
CometAPI Playground 내에서 프롬프트를 직접 입력하고 Seedance 2.0 모델을 사용해 비디오를 생성할 수 있습니다. 이는 소셜 미디어 콘텐츠(Reels, TikTok, YouTube Shorts), 브랜드 비디오, 짧은 내러티브 클립에 특히 유용합니다.
작동 방식:
- CometAPI를 엽니다
- Seedance 2.0 모델을 선택합니다
- 프롬프트를 입력합니다
- 매개변수(길이, 해상도, 화면비)를 조정합니다
- 생성 작업을 실행하고 결과를 기다립니다
CometAPI를 통한 이미지-투-비디오
제품 사진, 콘셉트 일러스트, 디자인 목업과 같은 정적 이미지를 업로드한 뒤, CometAPI를 통해 Seedance 2.0의 이미지-투-비디오 기능으로 애니메이션화할 수 있습니다.
결과는 시각 입력을 바탕으로 생성된 부드럽고 맥락을 이해한 모션입니다. 이는 이미 디자인 자산을 보유하고 있으며, 전체 제작 워크플로 없이 이를 비디오로 전환하고자 하는 팀에 이상적입니다.
작동 방식:
input_reference(또는 Playground의 동등한 파일 업로드 필드)를 사용합니다- 장면이 어떻게 움직여야 하는지 설명하는 모션 중심 프롬프트를 추가합니다
예시 프롬프트:
“카메라가 제품 쪽으로 천천히 밀고 들어가고, 부드러운 스튜디오 조명, 은은한 반사, 고급 상업 광고 느낌”
한 번에 오디오-비주얼 생성
먼저 비디오를 생성한 다음 별도로 오디오를 추가하는 대신, CometAPI는 Seedance 2.0의 기본 오디오-비주얼 생성 파이프라인을 지원합니다.
하나의 프롬프트에서 시각 요소와 사운드를 모두 설명함으로써, 동기화된 비디오와 오디오를 한 단계에서 생성할 수 있습니다. 이는 더 일관되고 의도적인 결과를 만들어내며, 편집 시간도 줄여줍니다.
예시 프롬프트:
“일출의 평화로운 해변, 잔잔하게 밀려오는 파도, 따뜻한 황금빛, 바다 소리와 함께 부드러운 앰비언트 음악”
출력에는 다음이 포함됩니다:
- 생성된 비디오
- 동기화된 배경 오디오
- 자연스럽게 맞춰진 타이밍과 분위기
Seedance 2.0에 CometAPI를 사용하는 이유
- API 또는 Playground를 통한 직접 접근
- 쉬운 매개변수 제어(길이, 해상도, 형식)
- 텍스트-투-비디오 및 이미지-투-비디오 워크플로 모두 지원
- 비동기 비디오 생성을 위한 내장 작업 처리
결론
Seedance 2.0은 AI 비디오 생성에서 진정한 도약처럼 보입니다. 텍스트, 이미지, 오디오, 비디오 입력을 결합하는 멀티모달 시스템이자, 텍스트-투-비디오와 이미지-투-비디오 모두에서 리더보드 선두를 달리는 모델이며, 가벼운 장난감용이 아니라 디렉터 스타일의 제어를 위해 설계된 모델입니다. 만약 순수하게 체감 품질만을 중요하게 생각한다면, 현재의 근거는 이 모델이 탁월하다고 말해줍니다.
지금 CometAPI에서 Seedance 2.0으로 제작을 시작해 보세요.