

"scale-at-all-costs(무조건 규모 확장)" 철학이 지배하는 환경—Flux.2와 Hunyuan-Image-3.0 같은 모델이 파라미터 수를 300억~800억 범위로 밀어 올리는—에서, 현상을 뒤흔들 새로운 도전자가 등장했다. Z-Image는 Alibaba의 Tongyi Lab이 개발했으며, 소비자급 하드웨어에서 구동되면서도 업계 거대 모델에 필적하는 출력 품질을 60억(6B) 파라미터의 탄탄한 아키텍처로 구현해 기대를 깨뜨렸다.
2025년 말에 공개된 Z-Image(초고속 변형인 Z-Image-Turbo 포함)는 출시 24시간 내에 500,000회 다운로드를 기록하며 AI 커뮤니티를 순식간에 사로잡았다. 단 8단계 추론만으로 포토리얼리즘 이미지를 만들어내는 Z-Image는 그저 또 하나의 모델이 아니라, 경쟁 모델들이 버거워하는 노트북에서도 고충실도 이미지를 창작 가능하게 하는 생성 AI의 민주화 동력이다.
Z-Image란?
Z-Image는 Tongyi-MAI / Alibaba Tongyi Lab 연구팀이 개발한 새로운 오픈소스 이미지 생성 파운데이션 모델이다. 텍스트 토큰, 시각적 의미 토큰, VAE 토큰을 단일 처리 스트림으로 연결하는 새로운 Scalable Single-Stream Diffusion Transformer (S3-DiT) 아키텍처를 기반으로 한 60억 파라미터 생성 모델이다. 설계 목표는 명확하다: 최상급 포토리얼리즘과 지시(Instruction) 준수를 제공하면서, 추론 비용을 대폭 줄이고 소비자급 하드웨어에서의 실사용을 가능케 하는 것. Z-Image 프로젝트는 Apache-2.0 라이선스 아래 코드, 모델 가중치, 온라인 데모를 공개한다.
Z-Image는 여러 변형으로 제공된다. 가장 널리 논의되는 릴리스는 배포 최적화된 소수 단계 증류 버전인 Z-Image-Turbo이며, 비증류 Z-Image-Base(파운데이션 체크포인트, 파인튜닝에 적합)와 Z-Image-Edit(이미지 편집용 지시 튜닝)도 함께 제공된다.
“Turbo”의 장점: 8단계 추론
주력 변형인 Z-Image-Turbo는 **Decoupled-DMD (Distribution Matching Distillation)**로 알려진 점진적 증류 기법을 활용한다. 이를 통해 표준 30~50단계의 생성 과정을 단 8단계로 압축한다.
결과: 엔터프라이즈 GPU(H800)에서는 1초 미만 생성 시간, 소비자용 카드(RTX 4090)에서는 사실상 실시간 성능을 제공하며, 다른 터보/라이트닝 모델의 흔한 "플라스틱" 느낌이나 "바랜" 품질 없이 출력한다.
Z-Image의 4가지 핵심 기능
Z-Image는 기술 개발자와 크리에이티브 전문가 모두를 위한 기능으로 가득하다.
1. 타의 추종을 불허하는 사실감과 미학
60억 파라미터에 불과함에도 Z-Image는 놀라운 선명도의 이미지를 생성한다. 특히 다음에 뛰어나다:
- 피부 질감: 인물 피부의 모공, 미세한 결점, 자연광을 정교하게 재현
- 재료 물리: 유리, 금속, 직물의 질감 정확한 렌더링
- 조명: SDXL 대비 영화적·체적 조명 처리 우수
2. 네이티브 양언어 텍스트 렌더링
AI 이미지 생성의 가장 큰 고질적 문제 중 하나가 텍스트 렌더링이다. Z-Image는 영어와 중국어 모두를 네이티브로 지원한다.
- 두 언어에서 정확한 철자와 서체로 복잡한 포스터, 로고, 간판을 생성할 수 있으며, 이는 서구 중심의 모델에는 종종 없는 기능이다.
3. Z-Image-Edit: 지시 기반 편집
베이스 모델과 함께 Z-Image-Edit가 공개되었다. 이 변형은 이미지-투-이미지 작업에 파인튜닝되어, 자연어 지시(예: "그 사람이 미소 짓게 해줘", "배경을 눈 덮인 산으로 바꿔줘")로 기존 이미지를 수정할 수 있다. 변환 중에도 동일 인물성(identity)과 조명 일관성을 높게 유지한다.
4. 소비자용 하드웨어 접근성
- VRAM 효율: 6GB VRAM(양자화)에서 16GB VRAM(풀 프리시전)까지 안정 구동
- 로컬 실행: ComfyUI와
diffusers를 통한 완전한 로컬 배포 지원으로 클라우드 의존 해소
Z-Image는 어떻게 작동하나요?
Single-stream diffusion transformer (S3-DiT)
Z-Image는 고전적 이중 스트림(텍스트와 이미지 인코더/스트림을 분리) 설계에서 벗어나, 텍스트 토큰, 이미지 VAE 토큰, 시각 의미 토큰을 단일 트랜스포머 입력으로 연결한다. 이러한 싱글 스트림 접근은 파라미터 활용을 개선하고 트랜스포머 백본 내부의 크로스모달 정렬을 단순화하여, 60억 모델에서 효율/품질의 유리한 균형을 제공한다고 저자들은 말한다.
Decoupled-DMD와 DMDR(증류 + 강화학습)
일반적인 품질 저하 없이 소수 단계(8단계) 생성을 가능케 하기 위해 팀은 Decoupled-DMD 증류 접근을 개발했다. 이 기법은 CFG(classifier-free guidance) 증강을 분포 정합과 분리하여 각각을 독립적으로 최적화한다. 이후 후처리 강화학습 단계(DMDR)를 적용해 의미 정렬과 미학을 정교화한다. 이 둘을 통해, 일반적인 확산 모델보다 훨씬 적은 NFE로도 높은 사실감을 유지하는 Z-Image-Turbo가 탄생했다.
훈련 처리량 및 비용 최적화
Z-Image는 라이프사이클 최적화 접근으로 훈련되었다: 큐레이션된 데이터 파이프라인, 간소화된 커리큘럼, 효율 인지 구현 선택. 저자들은 전체 훈련 워크플로를 약 **314K H800 GPU hours (≈ USD $630K)**에 완료했다고 보고했는데, 이는 200억+ 초대형 대안 대비 비용 효율적임을 나타내는 명시적·재현 가능한 엔지니어링 지표다.
Z-Image 모델의 벤치마크 결과
Z-Image-Turbo는 여러 최신 리더보드에서 높은 순위를 기록했으며, Artificial Analysis Text-to-Image 리더보드의 오픈소스 부문 상위권과 Alibaba AI Arena의 인간 선호 평가에서도 강력한 성능을 보였다.
하지만 실제 품질은 프롬프트 구성, 해상도, 업스케일 파이프라인, 추가 후처리에 따라 달라지기도 한다.
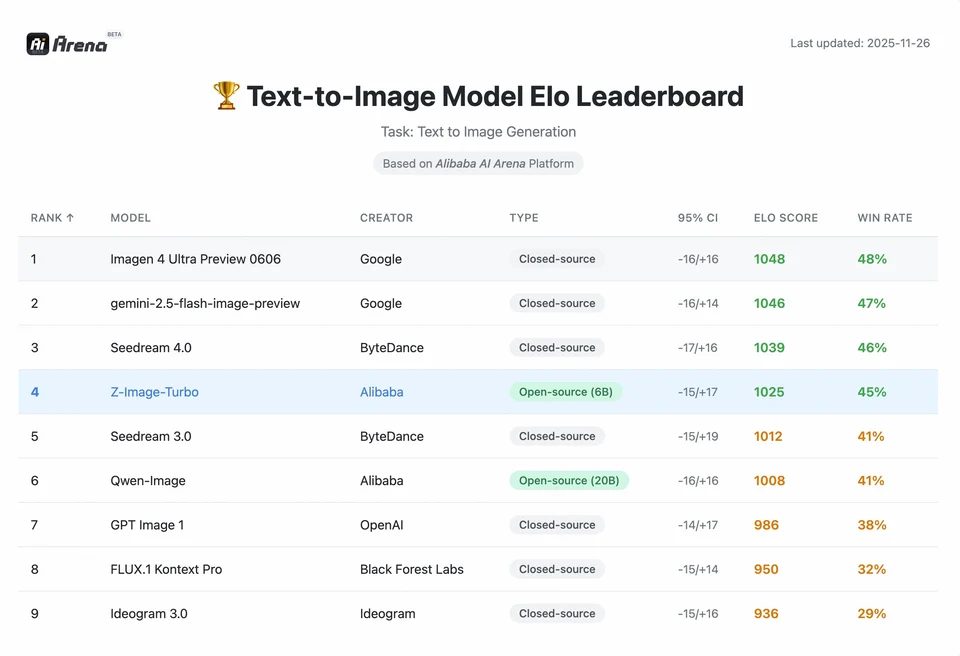
Z-Image의 성취 규모를 이해하려면 데이터를 봐야 한다. 아래는 리딩 오픈소스 및 상용 모델과 비교한 분석이다.
비교 벤치마크 요약
| 기능 / 지표 | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| 아키텍처 | S3-DiT (싱글 스트림) | MM-DiT (듀얼 스트림) | U-Net | Diffusion Transformer |
| 파라미터 수 | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| 추론 단계 | 8 Steps | 25 - 50 Steps | 1 - 4 Steps | 30 - 50 Steps |
| 필요 VRAM | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| 텍스트 렌더링 | High (EN + CN) | High (EN) | Moderate (EN) | High (CN + EN) |
| 생성 속도 (4090) | ~1.5 - 3.0 Seconds | ~15 - 30 Seconds | ~0.5 Seconds | ~20 Seconds |
| 사진적 사실감 점수 | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| 라이선스 | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
데이터 분석 및 성능 인사이트
- 속도 vs. 품질: SDXL Turbo가 더 빠르긴(1단계) 하지만 복잡한 프롬프트에서는 품질이 크게 저하된다. Z-Image-Turbo는 8단계에서 "스위트 스폿"에 도달하여, Flux.2에 필적하는 품질을 5~10배 더 빠르게 제공한다.
- 하드웨어 민주화: Flux.2는 강력하지만 합리적 성능을 내려면 사실상 24GB VRAM 카드(RTX 3090/4090) 이상이 필요하다. Z-Image는 중급 카드(RTX 3060/4060)로도 로컬에서 전문가급 1024x1024 이미지를 생성하게 한다.
개발자는 Z-Image를 어떻게 접근·사용할 수 있나요?
세 가지 일반적인 접근 방식이 있다:
- 호스티드 / SaaS(웹 UI 또는 API): z-image.ai 같은 서비스나 모델을 배포하고 웹 인터페이스 또는 유료 API를 제공하는 다른 공급자를 사용한다. 로컬 설정 없이 실험을 시작하는 가장 빠른 방법이다.
- Hugging Face + diffusers 파이프라인: Hugging Face
diffusers라이브러리는ZImagePipeline과ZImageImg2ImgPipeline을 포함하며, 일반적인from_pretrained(...).to("cuda")워크플로를 제공한다. 재현 가능한 예제를 원하는 Python 개발자에게 권장되는 경로다. - GitHub 리포에서 로컬 네이티브 추론: Tongyi-MAI 리포에는 네이티브 추론 스크립트, 최적화 옵션(FlashAttention, 컴파일, CPU 오프로딩), 최신 통합을 위해 소스에서
diffusers를 설치하는 방법이 포함되어 있다. 이 경로는 완전한 제어가 필요하거나 커스텀 훈련/파인튜닝을 실행하려는 연구자·팀에 유용하다.
최소 Python 예제는 어떻게 생겼나요?
아래는 Hugging Face diffusers를 사용해 Z-Image-Turbo로 텍스트-투-이미지 생성을 시연하는 간결한 Python 스니펫이다.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
참고:guidance_scale 기본값과 권장 설정은 Turbo 모델에서 다를 수 있다; 문서는 목표 동작에 따라 Turbo에는 낮거나 0에 가까운 가이던스를 권장할 수 있다고 제안한다.
Z-Image로 이미지-투-이미지(편집)를 어떻게 실행하나요?
ZImageImg2ImgPipeline은 이미지 편집을 지원한다. 예시:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
이는 공식 사용 패턴을 반영하며, 크리에이티브 편집 및 인페인팅 작업에 적합하다.
프롬프트와 가이던스는 어떻게 접근해야 하나요?
- 구조를 명시적으로: 복잡한 장면에서는 장면 구성, 포커스 대상, 카메라/렌즈, 조명, 분위기, 텍스트 요소를 포함하도록 프롬프트를 구조화하라. Z-Image는 상세 프롬프트에 잘 반응하며 위치/서사적 힌트를 잘 처리한다.
- guidance_scale을 신중히 튜닝: Turbo 모델에는 더 낮은 가이던스가 권장될 수 있으므로, 실험이 필요하다. 많은 Turbo 워크플로에서
guidance_scale=0.0–1.0에 시드와 고정 단계 조합이 일관된 결과를 낸다. - 제어된 편집에는 이미지-투-이미지를 사용: 구도를 유지하면서 스타일/색/객체를 바꾸고 싶다면 초기 이미지를 사용하고
strength로 변화 강도를 제어하라.
최고의 활용 사례와 모범 사례
1. 빠른 프로토타이핑 & 스토리보딩
Use Case: 영화 감독과 게임 디자이너가 장면을 즉시 시각화해야 하는 경우.
Why Z-Image? 3초 미만 생성으로, 크리에이터는 한 세션에서 수백 가지 콘셉트를 순환하며 조명과 구도를 실시간으로 다듬을 수 있고 렌더링을 기다릴 필요가 없다.
2. 이커머스 & 광고
Use Case: 상품의 배경이나 라이프스타일 샷 생성.
Best Practice: Z-Image-Edit를 사용하라.
원본 제품 사진을 업로드하고 "이 향수 병을 햇살 가득한 정원의 나무 테이블 위에 놓아줘." 같은 지시 프롬프트를 사용한다. 모델은 제품의 정체성을 보존하면서 포토리얼리즘 배경을 자연스럽게 생성한다.
3. 양언어 콘텐츠 제작
Use Case: 서구와 아시아 시장 모두를 대상으로 하는 글로벌 마케팅 캠페인.
Best Practice: 텍스트 렌더링 기능을 활용하라.
- Prompt: "어두운 골목에서 'OPEN'과 '营业中'이 빛나는 네온사인."
- Z-Image는 영어와 중국어 문자를 정확히 렌더링한다. 대부분의 다른 모델이 실패하는 부분이다.
4. 저자원 환경
Use Case: 엣지 디바이스나 일반 사무용 노트북에서 AI 생성을 실행.
Optimization Tip: INT8 양자화 버전의 Z-Image를 사용하라. 품질 손실을 거의 없이 VRAM 사용량을 6GB 이하로 줄여, 게이밍 노트북이 아닌 로컬 앱에서도 가능하게 한다.
결론: 누가 Z-Image를 써야 할까?
Z-Image는 높은 품질의 포토리얼리즘을 실용적 지연시간과 비용으로 원하고, 오픈 라이선스와 온프레미스 또는 커스텀 호스팅을 선호하는 조직과 개발자를 위해 설계되었다. 특히 빠른 반복(크리에이티브 도구, 제품 목업, 실시간 서비스)이 필요한 팀과, 컴팩트하면서도 강력한 이미지 모델의 파인튜닝에 관심 있는 연구자/커뮤니티에 매력적이다.
CometAPI는 제한이 비교적 적은 Grok Image 모델과 Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) 등도 제공한다—적절한 NSFW 팁과 트릭이 있다면 제한을 우회해 자유롭게 창작을 시작할 수 있다. 액세스 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인하라. CometAPI는 공식 가격보다 훨씬 낮은 가격을 제공해 통합을 도와준다.
Ready to Go?→ 무료 체험으로 시작하기 !