

Beberapa bulan kebelakangan ini telah menyaksikan peningkatan pesat dalam pengekodan agenik: model pakar yang bukan sahaja menjawab gesaan sekali sahaja tetapi merancang, mengedit, menguji dan mengulangi seluruh repositori. Dua daripada peserta berprofil tertinggi ialah Karang, model pengekodan kependaman rendah yang dibina khas yang diperkenalkan oleh Cursor dengan keluaran Cursor 2.0 dan GPT-5-Codex, varian GPT-5 yang dioptimumkan ejen OpenAI ditala untuk aliran kerja pengekodan yang berterusan. Bersama-sama ia menggambarkan garis kerosakan baharu dalam alatan pembangun: kelajuan vs. kedalaman, kesedaran ruang kerja tempatan lwn. penaakulan umum dan kemudahan "pengekodan getaran" berbanding keteguhan kejuruteraan.
Sepintas lalu: perbezaan kepala ke kepala
- Niat reka bentuk: GPT-5-Codex — penaakulan yang mendalam, agenik dan keteguhan untuk sesi yang panjang dan kompleks; Komposer — lelaran yang pantas dan sedar ruang kerja dioptimumkan untuk kelajuan.
- Permukaan integrasi utama: GPT-5-Codex — API produk/Respons Codex, IDE, integrasi perusahaan; Komposer — Editor kursor dan UI berbilang ejen Cursor.
- Latensi/lelaran: Komposer menekankan pusingan sub-30 saat dan menuntut kelebihan kelajuan yang besar; GPT-5-Codex mengutamakan ketelitian dan larian autonomi berbilang jam jika diperlukan.
Saya menguji API GPT-5-Codex model yang disediakan oleh CometAPI (pembekal pengagregatan API pihak ketiga, yang harga APInya biasanya lebih murah daripada yang rasmi), meringkaskan pengalaman saya menggunakan model Komposer Cursor 2.0 dan membandingkan keduanya dalam pelbagai dimensi pertimbangan penjanaan kod.
Apakah itu Komposer dan GPT-5-Codex
Apakah GPT-5-Codex dan apakah masalah yang ingin diselesaikan?
GPT-5-Codex OpenAI ialah petikan khusus GPT-5 yang OpenAI nyatakan dioptimumkan untuk senario pengekodan agenik: menjalankan ujian, melaksanakan pengeditan kod skala repositori dan mengulang secara autonomi sehingga pemeriksaan lulus. Tumpuan di sini ialah keupayaan luas merentas banyak tugas kejuruteraan — penaakulan mendalam untuk refactor kompleks, operasi "agentik" ufuk yang lebih panjang (di mana model boleh menghabiskan beberapa minit hingga berjam-jam membuat penaakulan dan ujian), dan prestasi yang lebih kukuh pada penanda aras piawai yang direka untuk mencerminkan masalah kejuruteraan dunia sebenar.
Apakah Komposer dan apakah masalah yang ingin diselesaikan?
Komposer ialah model pengekodan asli pertama Cursor, muncul dengan Cursor 2.0. Kursor menerangkan Komposer sebagai model sempadan, tertumpu kepada ejen yang dibina untuk kependaman rendah dan lelaran pantas dalam aliran kerja pembangun: merancang perbezaan berbilang fail, menggunakan carian semantik seluruh repositori dan menyelesaikan kebanyakan pusingan dalam masa kurang dari 30 saat. Ia dilatih dengan akses alat dalam gelung (cari, edit, abah-abah ujian) untuk cekap dalam tugas kejuruteraan praktikal dan untuk meminimumkan geseran kitaran gesaan → tindak balas berulang dalam pengekodan harian. Kursor meletakkan Komposer sebagai model yang dioptimumkan untuk halaju pembangun dan gelung maklum balas masa nyata.
Skop model & gelagat masa jalan
- Komposer: dioptimumkan untuk interaksi pantas, editor-centric dan konsistensi berbilang fail. Penyepaduan peringkat platform Cursor membolehkan Komposer melihat lebih banyak repositori dan mengambil bahagian dalam orkestrasi berbilang ejen (cth, dua ejen Komposer lwn. yang lain), yang Cursor berpendapat mengurangkan kebergantungan yang terlepas merentas fail.
- GPT-5-Codex: dioptimumkan untuk penaakulan panjang yang lebih mendalam. OpenAI mengiklankan keupayaan model untuk memperdagangkan pengiraan/masa untuk alasan yang lebih mendalam apabila perlu — dilaporkan bermula dari saat untuk tugasan ringan sehingga berjam-jam untuk larian autonomi yang meluas — membolehkan refaktor yang lebih teliti dan penyahpepijatan berpandukan ujian.
Versi pendek: Komposer = Model pengekodan dalam-IDE Cursor, ruang kerja; GPT-5-Codex = Varian GPT-5 khusus OpenAI untuk kejuruteraan perisian, tersedia melalui Respons/Codex.
Bagaimanakah Komposer dan GPT-5-Codex membandingkan dalam kelajuan?
Apakah yang dituntut oleh vendor?
Kursor meletakkan Komposer sebagai pengekod "sempadan pantas": nombor yang diterbitkan menyerlahkan daya pengeluaran penjanaan yang diukur dalam token sesaat dan tuntutan 2–4× masa penyiapan interaktif lebih pantas berbanding model "sempadan" dalam abah-abah dalaman Kursor. Liputan bebas (akhbar dan penguji awal) melaporkan Komposer menghasilkan kod pada ~200–250 token/saat dalam persekitaran Kursor dan melengkapkan pusingan pengekodan interaktif biasa dalam masa kurang daripada 30 saat dalam banyak kes.
GPT-5-Codex OpenAI tidak diletakkan sebagai percubaan kependaman; ia mengutamakan keteguhan dan penaakulan yang lebih mendalam dan — pada beban kerja penaakulan tinggi yang setanding — boleh menjadi lebih perlahan apabila digunakan pada saiz konteks yang lebih tinggi, menurut laporan komuniti dan urutan isu.
Cara kami menanda aras kelajuan (metodologi)
Untuk menghasilkan perbandingan kelajuan yang saksama, anda mesti mengawal jenis tugasan (penyiapan pendek vs penaakulan panjang), persekitaran (kependaman rangkaian, penyepaduan setempat vs awan) dan mengukur kedua-duanya. masa-untuk-pertama-hasil-berguna and jam dinding hujung ke hujung (termasuk sebarang pelaksanaan ujian atau langkah penyusunan). Perkara utama:
- Tugasan yang dipilih — penjanaan coretan kecil (melaksanakan titik akhir API), tugas sederhana (refactor satu fail dan kemas kini import), tugas besar (melaksanakan ciri merentas tiga fail, ujian kemas kini).
- Metrik — token masa-ke-pertama, perbezaan-masa-ke-pertama-berguna (masa sehingga tampalan calon dipancarkan), dan jumlah masa termasuk pelaksanaan ujian & pengesahan.
- Ulangan — setiap tugas dijalankan 10×, median digunakan untuk mengurangkan hingar rangkaian.
- alam Sekitar — ukuran yang diambil daripada mesin pembangun di Tokyo (untuk mencerminkan kependaman dunia sebenar) dengan pautan 100/10 Mbps yang stabil; keputusan akan berbeza mengikut wilayah.
Di bawah adalah boleh diterbitkan semula abah-abah laju untuk GPT-5-Codex (Responses API) dan penerangan tentang cara mengukur Komposer (dalam Kursor).
Abah-abah kelajuan (Node.js) — GPT-5-Codex (API Respons):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
Ini mengukur kependaman permintaan hujung ke hujung untuk GPT-5-Codex menggunakan API Respons awam (dokumen OpenAI menerangkan API Respons dan penggunaan model gpt-5-codex).
Cara mengukur kelajuan Komposer (Kursor):
Komposer berjalan di dalam Cursor 2.0 (desktop/VS Code fork). Kursor tidak (semasa penulisan) menyediakan API HTTP luaran umum untuk Komposer yang sepadan dengan API Respons OpenAI; Kekuatan komposer ialah dalam-IDE, integrasi ruang kerja stateful. Oleh itu ukur Komposer seperti pemaju manusia akan:
- Buka projek yang sama di dalam Cursor 2.0.
- Gunakan Komposer untuk menjalankan gesaan yang sama sebagai tugas ejen (buat laluan, refactor, perubahan berbilang fail).
- Mulakan jam randik apabila anda menyerahkan pelan Komposer; berhenti apabila Komposer mengeluarkan perbezaan atom dan menjalankan suite ujian (Antara muka Kursor boleh menjalankan ujian dan menunjukkan perbezaan yang disatukan).
- Ulang 10× dan gunakan median.
Bahan terbitan Kursor dan ulasan langsung menunjukkan Komposer menyelesaikan banyak tugas biasa dalam masa kurang ~30 saat dalam amalan; ini ialah sasaran kependaman interaktif dan bukannya masa inferens model mentah.
Bawa pulang: Matlamat reka bentuk komposer ialah suntingan interaktif pantas dalam editor; jika keutamaan anda ialah kependaman rendah, gelung pengekodan perbualan, Komposer dibina untuk kes penggunaan itu. GPT-5-Codex dioptimumkan untuk ketepatan dan penaakulan agen merentasi sesi yang lebih panjang; ia boleh berdagang sedikit lebih kependaman untuk perancangan yang lebih mendalam. Nombor vendor menyokong kedudukan ini.
Bagaimanakah Komposer dan GPT-5-Codex membandingkan dalam ketepatan?
Apakah maksud ketepatan dalam pengekodan AI
Ketepatan di sini adalah pelbagai aspek: ketepatan fungsi (adakah kod menyusun dan lulus ujian), ketepatan semantik (adakah tingkah laku itu memenuhi spesifikasi), dan kekukuhan (mengendalikan kes tepi, kebimbangan keselamatan).
Nombor penjual dan akhbar
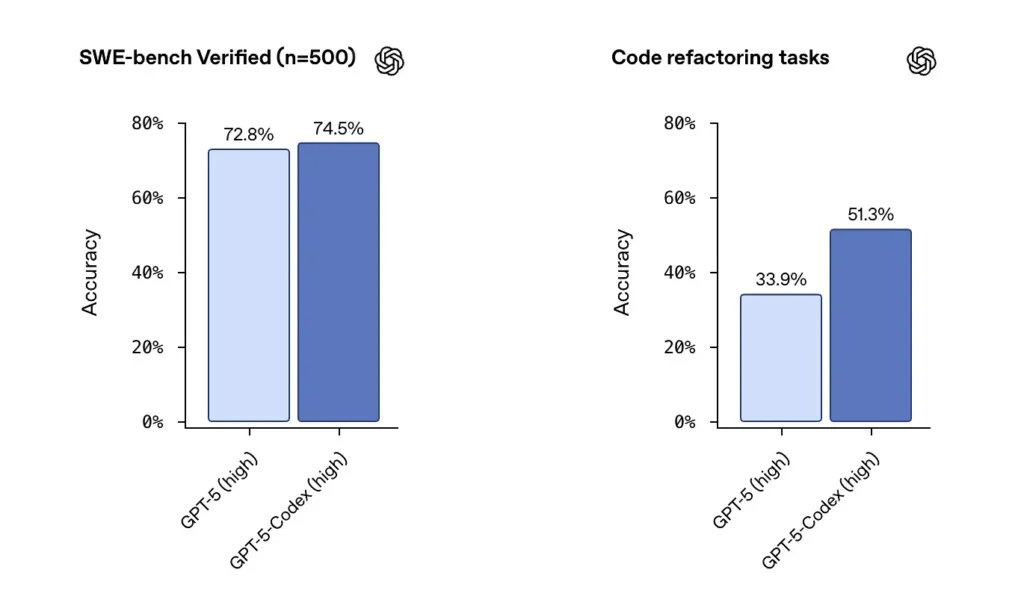
OpenAI melaporkan prestasi kukuh GPT-5-Codex pada set data yang disahkan bangku SWE dan menyerlahkan a 74.5% kadar kejayaan pada penanda aras pengekodan dunia sebenar (dilaporkan dalam liputan akhbar) dan peningkatan ketara dalam kejayaan pemfaktoran semula (51.3% berbanding 33.9 untuk asas GPT-5 pada ujian refactor dalaman mereka).
Keluaran kursor menunjukkan Komposer sering cemerlang dalam pelbagai fail, suntingan sensitif konteks di mana penyepaduan editor dan keterlihatan repo penting. Selepas ujian saya melaporkan bahawa Komposer menghasilkan lebih sedikit ralat kebergantungan terlepas semasa refactor berbilang fail dan mendapat markah lebih tinggi pada ujian semakan buta untuk beberapa beban kerja berbilang fail. Ciri kependaman dan ejen selari komposer juga membantu saya meningkatkan kelajuan lelaran.
Ujian ketepatan bebas (kaedah yang disyorkan)
Ujian adil menggunakan campuran:
- Ujian unit: suapkan repo dan suite ujian yang sama kepada kedua-dua model; menjana kod, menjalankan ujian.
- Ujian refactor: menyediakan fungsi yang sengaja tidak kemas dan minta model untuk memfaktorkan semula dan menambah ujian.
- Pemeriksaan keselamatan: jalankan analisis statik dan alat SAST pada kod yang dijana (cth, Bandit, ESLint, semgrep).
- Kajian manusia: markah semakan kod oleh jurutera berpengalaman untuk kebolehselenggaraan dan amalan terbaik.
Contoh: abah-abah ujian automatik (Python) — jalankan ujian kod dan unit yang dijana
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
Gunakan corak ini untuk secara automatik menegaskan sama ada output model adalah betul dari segi fungsi (lulus ujian). Untuk tugas pemfaktoran semula, jalankan abah-abah terhadap repo asal ditambah perbezaan model dan bandingkan kadar lulus ujian dan perubahan liputan.
Bawa pulang: Pada suite penanda aras mentah, GPT-5-Codex melaporkan nombor yang sangat baik dan kehebatan pemfaktoran semula yang kukuh. Dalam dunia nyata, pembaikan berbilang fail dan aliran kerja editor, kesedaran ruang kerja Komposer boleh menghasilkan penerimaan praktikal yang lebih tinggi dan lebih sedikit ralat "mekanikal" (import hilang, nama fail salah). Untuk ketepatan fungsi maksimum dalam tugas algoritma fail tunggal, GPT-5-Codex ialah calon yang kuat; untuk berbilang fail, perubahan sensitif konvensyen di dalam IDE, Komposer sering bersinar.
Komposer vs GPT-5: Bagaimanakah mereka membandingkan kualiti kod?
Apa yang dikira sebagai kualiti?
Kualiti termasuk kebolehbacaan, penamaan, dokumentasi, liputan ujian, penggunaan corak idiomatik dan kebersihan keselamatan. Ia diukur secara automatik (linter, metrik kerumitan) dan secara kualitatif (semakan manusia).
Perbezaan yang diperhatikan
- GPT-5-Codex: kuat dalam menghasilkan corak idiomatik apabila ditanya secara eksplisit; cemerlang dalam kejelasan algoritma dan boleh menghasilkan suite ujian yang komprehensif apabila digesa. Alat Codex OpenAI termasuk ujian/pelaporan bersepadu dan log pelaksanaan.
- Karang: dioptimumkan untuk memerhatikan gaya dan konvensyen repo secara automatik; Komposer boleh mengikuti corak projek sedia ada dan menyelaraskan kemas kini kepada berbilang fail (penamaan semula/penyebaran semula, mengimport kemas kini). Ia menawarkan kebolehselenggaraan atas permintaan yang sangat baik untuk projek besar.
Contoh semakan Kualiti Kod yang boleh anda jalankan
- Linters — ESLint / pylint
- kerumitan — radon / flake8-kompleksiti
- Keselamatan — semgrep / Penyamun
- Liputan ujian — jalankan coverage.py atau vitest/nyc untuk JS
Automatikkan semakan ini selepas menggunakan tampalan model untuk mengukur peningkatan atau regresi. Contoh urutan arahan (repo JS):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
Kajian manusia & amalan terbaik
Dalam amalan, model memerlukan arahan untuk mengikut amalan terbaik: minta docstring, anotasi taip, penyematan kebergantungan atau corak tertentu (cth, async/menunggu). GPT-5-Codex sangat baik apabila diberikan arahan yang jelas; Komposer mendapat manfaat daripada konteks repositori tersirat. Gunakan pendekatan gabungan: arahkan model secara eksplisit dan biarkan Komposer menguatkuasakan gaya projek jika anda berada di dalam Kursor.
Syor: Untuk kerja kejuruteraan berbilang fail di dalam IDE, pilih Komposer; untuk saluran paip luaran, tugas penyelidikan atau automasi rantai alat yang membolehkan anda memanggil API dan membekalkan konteks yang besar, GPT-5-Codex ialah pilihan yang kukuh.
Pilihan integrasi dan penempatan
Komposer dihantar sebagai sebahagian daripada Kursor 2.0, dibenamkan dalam editor Kursor dan UI. Pendekatan Kursor menekankan satah kawalan vendor tunggal yang menjalankan Komposer bersama model lain — membenarkan pengguna menjalankan berbilang contoh model pada gesaan yang sama dan membandingkan output dalam editor. ()
GPT-5-Codex sedang dilancarkan ke dalam penawaran Codex OpenAI dan keluarga produk ChatGPT, dengan ketersediaan melalui peringkat berbayar ChatGPT dan API yang platform pihak ketiga seperti CometAPI menawarkan nilai yang lebih baik untuk wang. OpenAI juga menyepadukan Codex ke dalam alatan pembangun dan aliran kerja rakan kongsi awan (contohnya penyepaduan Kod Visual Studio/GitHub Copilot ).
Di manakah Komposer dan GPT-5-Codex boleh mendorong industri seterusnya?
Kesan jangka pendek
- Kitaran lelaran yang lebih pantas: Model terbenam editor seperti Komposer mengurangkan geseran pada pembaikan kecil dan penjanaan PR.
- Peningkatan jangkaan untuk pengesahan: Penekanan Codex pada ujian, log dan keupayaan autonomi akan mendorong vendor untuk menyediakan pengesahan luar kotak yang lebih kukuh untuk kod yang dihasilkan model.
Jangka pertengahan hingga panjang
- Orkestrasi berbilang model menjadi normal: GUI berbilang ejen Cursor ialah petunjuk awal bahawa jurutera akan menjangkakan untuk menjalankan beberapa ejen khusus secara selari (linting, keselamatan, pemfaktoran semula, pengoptimuman prestasi) dan menerima output terbaik.
- Gelung maklum balas CI/AI yang lebih ketat: Apabila model bertambah baik, saluran paip CI akan semakin menggabungkan penjanaan ujian dipacu model dan cadangan pembaikan automatik — tetapi semakan manusia dan pelancaran berperingkat tetap penting.
Kesimpulan
Komposer dan GPT-5-Codex bukanlah senjata yang sama dalam perlumbaan senjata yang sama; ia adalah alat pelengkap yang dioptimumkan untuk bahagian berlainan kitaran hayat perisian. Cadangan nilai komposer ialah halaju: pantas, lelaran berasaskan ruang kerja yang mengekalkan aliran pembangun. Nilai GPT-5-Codex ialah kedalaman: kegigihan agen, ketepatan dipacu ujian dan kebolehauditan untuk transformasi wajaran tinggi. Buku permainan kejuruteraan pragmatik adalah untuk mengatur kedua-duanya: ejen seperti Komposer gelung pendek untuk aliran harian, dan ejen gaya GPT-5-Codex untuk operasi berpagar, berkeyakinan tinggi. Penanda aras awal mencadangkan kedua-duanya akan menjadi sebahagian daripada kit alat pembangun jangka pendek dan bukannya satu menggantikan yang lain.
Tiada pemenang objektif tunggal merentas semua dimensi. Kekuatan perdagangan model:
- GPT-5-Codex: lebih kukuh pada penanda aras ketepatan yang mendalam, penaakulan skop besar dan aliran kerja berbilang jam autonomi. Ia bersinar apabila kerumitan tugas memerlukan penaakulan yang panjang atau pengesahan yang berat.
- Komposer: lebih kukuh dalam kes penggunaan bersepadu editor yang ketat, konsistensi konteks berbilang fail dan kelajuan lelaran pantas dalam persekitaran Kursor. Ia boleh menjadi lebih baik untuk produktiviti pembangun sehari-hari yang memerlukan pengeditan segera yang menyedari konteks yang tepat.
Lihat juga Kursor 2.0 dan Komposer: bagaimana pelbagai ejen memikirkan semula pengekodan AI yang mengejutkan
Bermula
CometAPI ialah platform API bersatu yang mengagregatkan lebih 500 model AI daripada pembekal terkemuka—seperti siri GPT OpenAI, Google Gemini, Anthropic's Claude, Midjourney, Suno dan banyak lagi—menjadi satu antara muka mesra pembangun. Dengan menawarkan pengesahan yang konsisten, pemformatan permintaan dan pengendalian respons, CometAPI secara dramatik memudahkan penyepaduan keupayaan AI ke dalam aplikasi anda. Sama ada anda sedang membina chatbots, penjana imej, komposer muzik atau saluran paip analitik terdorong data, CometAPI membolehkan anda mengulangi dengan lebih pantas, mengawal kos dan kekal sebagai vendor-agnostik—semuanya sambil memanfaatkan penemuan terkini merentas ekosistem AI.
Pembangun boleh mengakses API GPT-5-Codexmelalui CometAPI, versi model terkini sentiasa dikemas kini dengan laman web rasmi. Untuk memulakan, terokai keupayaan model dalam Taman Permainan dan berunding dengan Panduan API untuk arahan terperinci. Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda menyepadukan.
Bersedia untuk Pergi?→ Daftar untuk CometAPI hari ini !
Jika anda ingin mengetahui lebih banyak petua, panduan dan berita tentang AI, ikuti kami VK, X and Perpecahan!