
Gemini 2.5 Flash API ialah model AI multimodal terbaharu Google, direka untuk tugasan berkelajuan tinggi, cekap kos dengan keupayaan penaakulan yang boleh dikawal, membenarkan pembangun menghidupkan atau mematikan ciri "pemikiran" lanjutan melalui API Gemini. Model Terkini ialah gemini-2.5-flash.
Gambaran keseluruhan Gemini 2.5 Flash
Gemini 2.5 Flash direka bentuk untuk menyampaikan respons pantas tanpa menjejaskan kualiti output. Ia menyokong input multimodal, termasuk teks, imej, audio dan video, menjadikannya sesuai untuk pelbagai aplikasi. Model ini boleh diakses melalui platform seperti Google AI Studio dan Vertex AI, menyediakan pembangun dengan alatan yang diperlukan untuk penyepaduan yang lancar ke dalam pelbagai sistem.
Maklumat Asas (Ciri)
Gemini 2.5 Flash memperkenalkan beberapa yang menonjol ciri-ciri yang membezakannya dalam keluarga Gemini 2.5:
- Penaakulan Hibrid: Pemaju boleh menetapkan a bajet_berfikir parameter untuk mengawal dengan baik berapa banyak token yang dikhaskan oleh model kepada penaakulan dalaman sebelum output.
- Pareto Frontier: Berada di titik prestasi kos yang optimum, Flash menawarkan nisbah harga-kepada-kepintaran terbaik antara 2.5 model .
- Sokongan Multimodal: Proses teks, imej, video, dan audio asli, membolehkan keupayaan perbualan dan analisis yang lebih kaya.
- Konteks 1 Juta Token: Panjang konteks yang tidak sepadan membolehkan analisis mendalam dan pemahaman dokumen yang panjang dalam satu permintaan.
Versi Model
Gemini 2.5 Flash telah beralih melalui kunci berikut versi:
- gemini-2.5-flash-lite-preview-09-2025: Kebolehgunaan alat dipertingkat: Prestasi yang dipertingkatkan pada tugasan yang kompleks dan berbilang langkah, dengan peningkatan 5% dalam skor SWE-Bench Verified (daripada 48.9% kepada 54%). Kecekapan yang dipertingkatkan: Apabila mendayakan penaakulan, output berkualiti tinggi dicapai dengan token yang lebih sedikit, mengurangkan kependaman dan kos.
- Pratonton 04-17: Keluaran akses awal dengan keupayaan "berfikir", tersedia melalui Gemini-2.5-flash-preview-04-17.
- Ketersediaan Umum Stabil (GA): Mulai 17 Jun 2025, titik akhir yang stabil Gemini-2.5-flash menggantikan pratonton, memastikan kebolehpercayaan gred pengeluaran tanpa perubahan API daripada pratonton 20 Mei .
- Penamatan Pratonton: Titik akhir pratonton dijadualkan untuk ditutup pada 15 Julai 2025; pengguna mesti berhijrah ke titik akhir GA sebelum tarikh ini.
Mulai Julai 2025, Gemini 2.5 Flash kini tersedia secara umum dan stabil (tiada perubahan daripada Gemini-2.5-flash-preview-05-20 ).Jika anda menggunakan gemini-2.5-flash-preview-04-17, harga pratonton sedia ada akan diteruskan sehingga tarikh akhir model bersara yang dijadualkan pada 15 Julai 2025, apabila ia akan ditutup. Anda boleh berhijrah ke model yang tersedia secara umum "gemini-2.5-flash".
Lebih cepat, lebih murah, lebih bijak:
- Matlamat reka bentuk: kependaman rendah + daya pengeluaran tinggi + kos rendah;
- Percepatan keseluruhan dalam penaakulan, pemprosesan multimodal, dan tugasan teks yang panjang;
- Penggunaan token dikurangkan sebanyak 20–30%, dengan ketara mengurangkan kos penaakulan.
Spesifikasi teknikal
Tetingkap Konteks Input: Sehingga 1 juta token, membolehkan pengekalan konteks yang meluas.
Token Output: Mampu menjana sehingga 8,192 token setiap respons.
Modaliti Disokong: Teks, imej, audio dan video.
Platform Penyepaduan: Tersedia melalui Google AI Studio dan Vertex AI.
Harga: Model harga berasaskan token yang kompetitif, memudahkan penggunaan kos efektif.
Butiran Teknikal
Di bawah tudung, Gemini 2.5 Flash ialah a berasaskan transformer model bahasa besar yang dilatih pada campuran data web, kod, imej dan video. kunci teknikal spesifikasi termasuk:
Latihan Multimodal: Dilatih untuk menjajarkan pelbagai modaliti, Flash boleh mencampurkan teks dengan lancar dengan lancar imej, video, Atau audio, berguna untuk tugasan seperti ringkasan video atau kapsyen audio.
Proses Pemikiran Dinamik: Melaksanakan gelung penaakulan dalaman di mana model rancangan and memecahkan gesaan yang kompleks sebelum keluaran akhir.
Belanjawan Pemikiran Boleh Dikonfigurasikan: The bajet_berfikir boleh ditetapkan daripada 0 (tiada alasan) sehingga Token 24,576, membenarkan pertukaran antara kependaman dan kualiti jawapan .
Integrasi Alat: Menyokong Asas dengan Carian Google, Pelaksanaan Kod, Konteks URL, dan Panggilan Fungsi, mendayakan tindakan dunia nyata secara langsung daripada gesaan bahasa semula jadi .
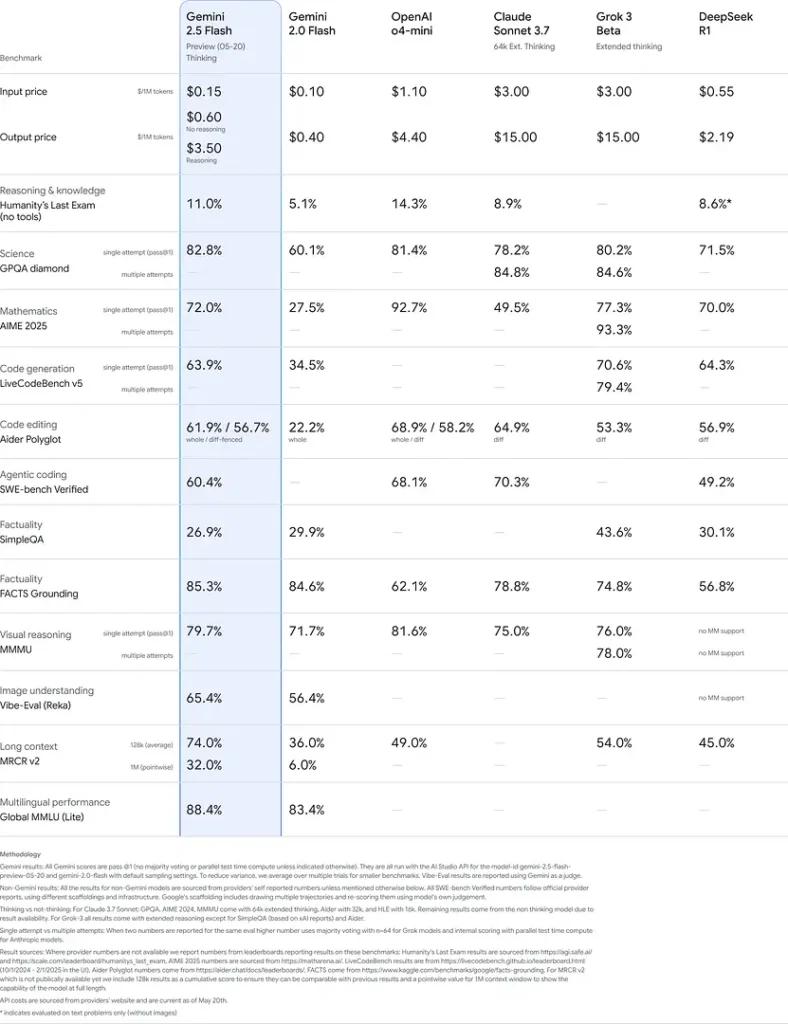
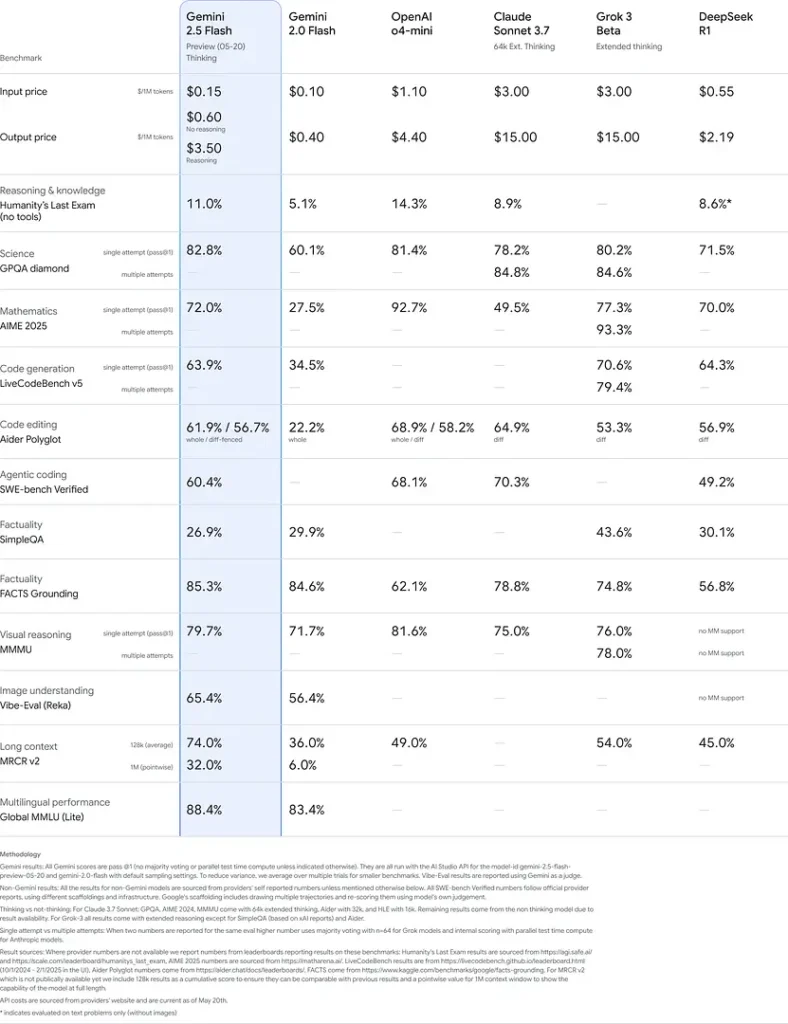
Prestasi Penanda Aras
Dalam penilaian yang ketat, Gemini 2.5 Flash menunjukkan menerajui industri prestasi:
- Gesaan Keras LMArena: Menjaringkan gol kedua selepas 2.5 Pro pada penanda aras Hard Prompts yang mencabar, mempamerkan keupayaan penaakulan pelbagai langkah yang kukuh .
- Skor MMLU 0.809: Melebihi prestasi model purata dengan a 0.809 Ketepatan MMLU, mencerminkan pengetahuan domain yang luas dan kehebatan penaakulan .
- Latensi dan Throughput: Mencapai 271.4 token/saat kelajuan penyahkodan dengan a 0.29 s Masa-ke-Pertama-Token, menjadikannya sesuai untuk beban kerja sensitif kependaman.
- Peneraju Harga-kepada-Prestasi: Pada $0.26/1 J token, Flash mengurangkan banyak pesaing sambil memadankan atau mengatasi mereka pada penanda aras utama.
Keputusan ini menunjukkan kelebihan daya saing Gemini 2.5 Flash dalam penaakulan, pemahaman saintifik, penyelesaian masalah matematik, pengekodan, tafsiran visual dan keupayaan berbilang bahasa:
Batasan
Walaupun berkuasa, Gemini 2.5 Flash mempunyai ciri tertentu batasan:
- Risiko Keselamatan: Model boleh mempamerkan a nada "berdakwah". dan mungkin menghasilkan keluaran yang munasabah tetapi tidak betul atau berat sebelah (halusinasi), terutamanya pada pertanyaan kes tepi. Pengawasan manusia yang ketat tetap penting.
- Had Kadar: Penggunaan API dikekang oleh had kadar (10 RPM, 250,000 TPM, 250 RPD pada peringkat lalai), yang boleh memberi kesan kepada pemprosesan kelompok atau aplikasi volum tinggi.
- Tingkat Perisikan: Walaupun sangat berkemampuan untuk a kilat model, ia tetap kurang tepat daripada 2.5 Pro pada tugas ejen yang paling mencabar seperti pengekodan lanjutan atau penyelarasan berbilang ejen.
- Pertukaran Kos: Walaupun menawarkan yang terbaik prestasi harga, penggunaan meluas bagi berfikir mod meningkatkan penggunaan token keseluruhan, meningkatkan kos untuk gesaan penaakulan yang mendalam.
See Also API Gemini 2.5 Pro
Kesimpulan
Gemini 2.5 Flash berdiri sebagai bukti komitmen Google untuk memajukan teknologi AI. Dengan prestasi teguh, keupayaan pelbagai mod dan pengurusan sumber yang cekap, ia menawarkan penyelesaian komprehensif untuk pembangun dan organisasi yang ingin memanfaatkan kuasa kecerdasan buatan dalam operasi mereka.
Bagaimana hendak memanggil Gemini 2.5 Flash API daripada CometAPI
Gemini 2.5 Flash Harga API dalam CometAPI,diskaun 20% daripada harga rasmi:
- Token Input: $0.24 / M token
- Token Output: $0.96/M token
Langkah yang Diperlukan
- Log masuk ke cometapi.com. Jika anda belum menjadi pengguna kami, sila daftar dahulu
- Dapatkan kunci API kelayakan akses antara muka. Klik "Tambah Token" pada token API di pusat peribadi, dapatkan kunci token: sk-xxxxx dan serahkan.
- Dapatkan url tapak ini: https://api.cometapi.com/
Kaedah Penggunaan
- Pilih "
gemini-2.5-flash” titik akhir untuk menghantar permintaan API dan menetapkan badan permintaan. Kaedah permintaan dan badan permintaan diperoleh daripada dokumen API tapak web kami. Laman web kami juga menyediakan ujian Apifox untuk kemudahan anda. - Gantikan dengan kunci CometAPI sebenar anda daripada akaun anda.
- Masukkan soalan atau permintaan anda ke dalam medan kandungan—inilah yang akan dijawab oleh model.
- . Proses respons API untuk mendapatkan jawapan yang dijana.
Untuk maklumat model lunched dalam Comet API sila lihat https://api.cometapi.com/new-model.
Untuk maklumat Harga Model dalam API Komet sila lihat https://api.cometapi.com/pricing.
Contoh Penggunaan API
Pembangun boleh berinteraksi dengan Gemini-2.5-flash melalui API CometAPI, membolehkan penyepaduan ke dalam pelbagai aplikasi. Di bawah ialah contoh Python:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Skrip ini menghantar gesaan ke Gemini 2.5 Flash model dan mencetak respons yang dijana, menunjukkan cara menggunakan Gemini 2.5 Flash untuk penjelasan yang kompleks.