

Google dan unit penyelidikannya DeepMind secara senyap (dan kemudian tidak begitu senyap) telah mendorong satu lagi langkah besar dalam peta jalan Gemini: Gemini 3.1 Pro. Keluaran ini, dilancarkan merentas permukaan berorientasikan pengguna CometAPI, diposisikan sebagai peningkatan prestasi dan penaakulan kepada keluarga Gemini 3 — menjanjikan penaakulan bentuk panjang yang lebih mantap, pemahaman multimodal yang dipertingkat, dan kebolehskalaan yang lebih baik untuk aplikasi dunia sebenar.
Model terbaru Google — apakah Gemini 3.1 Pro?
Gemini 3.1 Pro ialah kemas kini bertahap pertama dalam keluarga Gemini 3 yang diposisikan sebagai model penaakulan “paling berkeupayaan” yang dioptimumkan untuk tugas berbilang langkah, multimodal, dan berasaskan agen. Dilancarkan dalam pratonton awam pada pertengahan Februari 2026 (pratonton diumumkan 19–20 Feb 2026), model ini disasarkan secara jelas kepada senario yang memerlukan rantaian pemikiran berterusan, penggunaan alat, dan kefahaman konteks panjang — sebagai contoh: sintesis penyelidikan berskala besar, agen kejuruteraan yang menyelaraskan alat dan sistem, serta analisis multimodal bagi dokumen yang menggabungkan teks, imej, audio dan video.
Pada tahap tinggi, Gemini 3.1 Pro digambarkan oleh pembangunnya sebagai:
- Secara asli multimodal — mampu menerima dan menalar ke atas teks, imej, audio dan video.
- Dibina untuk konteks panjang — menyokong tetingkap konteks yang sangat besar sesuai untuk keseluruhan kod asas, himpunan berbilang dokumen, atau transkrip panjang.
- Dioptimumkan untuk penaakulan yang boleh dipercayai dan aliran kerja agen, bermakna ia ditetapkan untuk merancang, memanggil alat, dan mengesahkan output merentasi tugas berbilang langkah.
Mengapa ini penting sekarang: organisasi dan pembangun sedang beralih daripada “pembantu perbualan yang baik” kepada “agen sokongan keputusan dan penyelidikan berisiko tinggi” (draf perundangan, sintesis R&D, kefahaman dokumen multimodal). Gemini 3.1 Pro direka secara jelas untuk koridor itu — untuk mengurangkan halusinasi, menghasilkan penaakulan berjejak, dan berintegrasi dengan CometAPI untuk prototaip dan produksi.
Apakah sorotan teknikal dan ciri Gemini 3.1 Pro?
Multimodal asli dan tetingkap konteks ekstrem
Gemini 3.1 Pro meneruskan fokus garis keturunan Gemini pada multimodaliti. Menurut kad model dan nota produk, model ini menerima dan menalar ke atas teks, imej, audio, dan video dalam saluran yang sama — keupayaan yang memudahkan aliran kerja apabila jenis data bercampur (contohnya, deposisi undang-undang dengan audio + transkrip + imbasan). Yang ketara, model ini menyokong tetingkap konteks 1,000,000-token dan boleh menghasilkan output panjang (nota diterbitkan meletakkan had output pada saiz yang sangat besar yang sesuai untuk tugas bentuk panjang). Skala ini menjadikannya sesuai untuk kes penggunaan seperti menganalisis keseluruhan repositori kod, dokumen berbilang bab, atau transkrip panjang tanpa pemecahan.
“Pemikiran dinamik”: penaakulan dipertingkat & perancangan berperingkat
Google menerangkan 3.1 Pro sebagai mempunyai “pemikiran” yang dipertingkat — iaitu pengendalian rantaian pemikiran dalaman yang lebih baik dan pemilihan dinamik strategi penaakulan bergantung pada kerumitan tugas. Model ini ditala untuk melibatkan perancangan berbilang langkah yang jelas apabila diperlukan, dan cekap token semasa melakukannya. Dalam amalan, ini diterjemahkan kepada lebih kurang halusinasi bagi masalah kompleks berperingkat dan konsistensi fakta yang dipertingkat pada penanda aras penaakulan berbilang langkah.
Aliran kerja berasaskan agen & penggunaan alat
Fokus reka bentuk utama untuk 3.1 Pro ialah prestasi berasaskan agen: menyelaras alat, memanggil pembumian web atau carian, menulis dan melaksanakan serpihan kod, serta mengesahkan output melalui laluan sekunder. Google telah mengintegrasikan 3.1 Pro ke dalam produk berorientasikan agen (contohnya, persekitaran pembangunan Antigravity) untuk membolehkan model menjalankan tugas yang melibatkan editor, terminal, dan pelayar — serta merakam artifak seperti tangkapan skrin dan rakaman pelayar bagi mengesahkan kemajuan. Ciri-ciri ini bertujuan mengurangkan jurang antara model “pemberi nasihat” dan model yang benar-benar melaksanakan aliran kerja berbilang alat dengan boleh dipercayai.
Submod khusus (Deep Research, Deep Think)
Google memadankan 3.1 Pro dengan “Deep Research” dan merujuk varian “Deep Think” yang akan datang. Submod ini disasarkan masing-masing kepada tugas penyelidikan berkeperluan tinggi dan kedalaman penaakulan maksimum (dengan kos pengiraan dan kependaman tambahan). Ia bertujuan untuk memenuhi keperluan penganalisis, penyelidik, dan pembangun yang memerlukan output lebih teliti, berkualiti tinggi berbanding respons terpantas dan termurah.
Bagaimanakah prestasi Gemini 3.1 Pro pada penanda aras?
Gemini 3.1 Pro mencapai peningkatan ketara berbanding keputusan Gemini 3 Pro sebelumnya, sering mendahului pada set luas ukuran penaakulan berbilang langkah dan multimodal — tetapi ketinggalan berbanding sesetengah pesaing pada tugas khusus tertentu (khususnya beberapa penkoderan lanjutan atau set soalan tahap pakar). Ringkasnya: penambahbaikan menyeluruh dengan kelebihan pesaing yang sempit dalam penanda aras khusus.
Dakwaan penanda aras utama dan angka tajuk
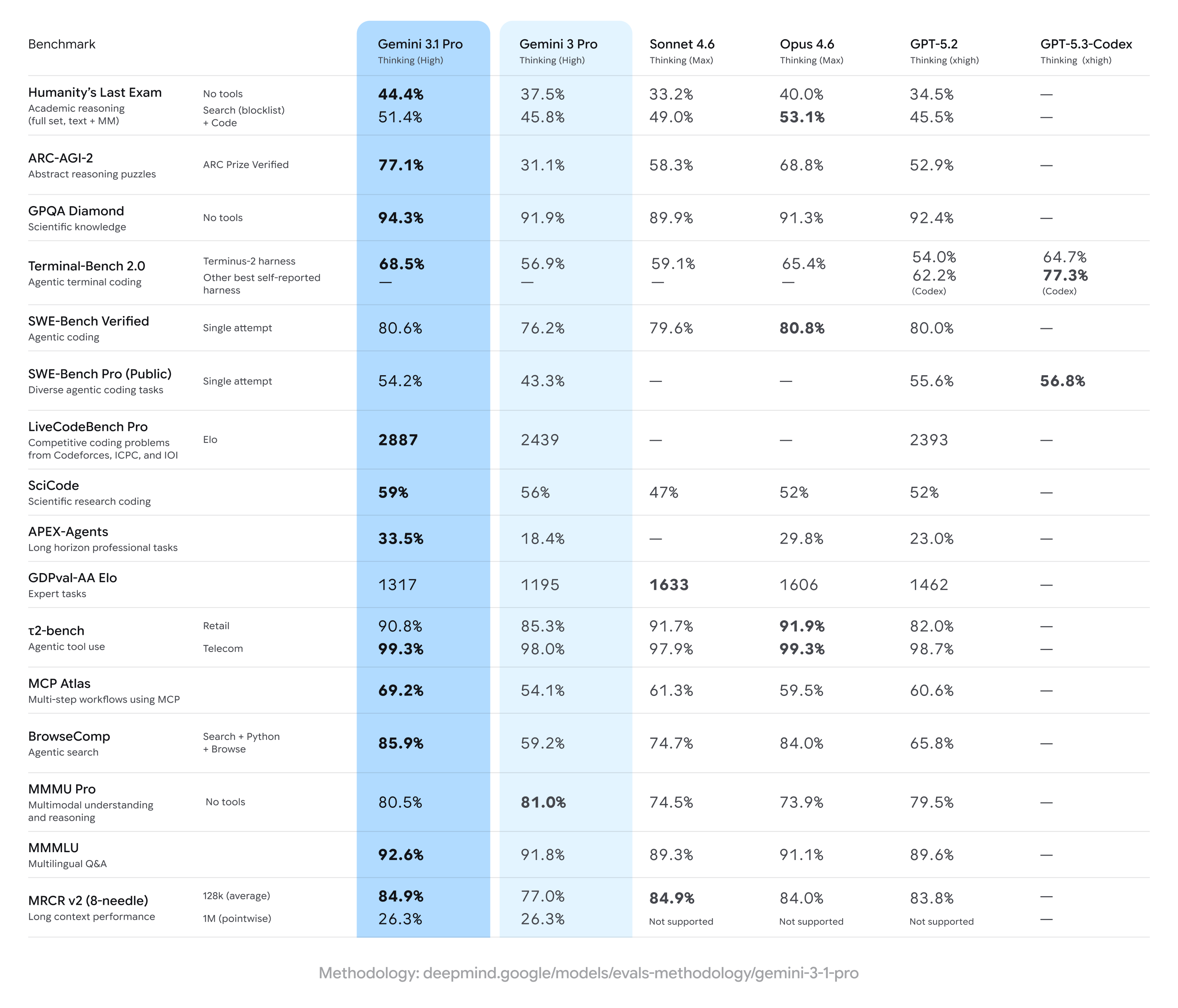
- ARC-AGI-2 (penaakulan abstrak / teka-teki sains berbilang langkah): Peningkatan yang dilaporkan bagi Gemini 3.1 Pro menunjukkan penambahbaikan besar berbanding versi Gemini 3 Pro terdahulu; satu set ujian komuniti menunjukkan peningkatan lebih dua kali ganda pada ARC-AGI-2 berbanding garis dasar Gemini 3 Pro sebelumnya dalam ujian ringkas dan berfokus. Skor khusus yang dilaporkan (ujian komuniti) meletakkan Gemini 3.1 Pro pada ~77.1% pada beberapa pengagregatan gaya ARC (pelaporan awam).
- GPQA Diamond dan penanda aras sains peringkat siswazah: Data laporan menunjukkan Gemini 3.1 Pro mencapai rekod tertinggi pada GPQA Diamond (penanda aras QA sains peringkat siswazah), mengatasi model Gemini terdahulu dan menetapkan aras tertinggi baharu bagi keluarga ini dalam larian bebas. Keuntungan ini mencerminkan penambahbaikan rantaian pemikiran dan talaan penaakulan berperingkat model.
- “Humanity’s Last Exam” dengan alat diaktifkan (berbilang alat, penaakulan berasas): Dalam perbandingan langsung dengan Claude Opus 4.6 daripada Anthropic, Claude mencapai 53.1% pada penanda aras kompleks berdaya alat ini manakala Gemini 3.1 Pro mencapai 51.4% dalam pusingan ujian yang sama — menunjukkan Gemini hampir di belakang tetapi belum teratas pada peperiksaan berbilang alat tertentu itu.
- Penanda aras pengkodan & terminal (Terminal-Bench 2.0, SWE-Bench Pro): Penanda aras pengkodan khusus menunjukkan lebih banyak perbezaan. Pada Terminal-Bench 2.0 dengan abah-abah tertentu, varian GPT-5.3-Codex mencatat sekitar 77.3% berbanding ~68.5% bagi Gemini 3.1 Pro dalam perbandingan yang sama. Pada keputusan SWE-Bench Pro yang dilaporkan secara awam, Gemini 3.1 Pro mencatat ~54.2% berbanding 56.8% bagi GPT-5.3-Codex — lebih rapat, tetapi keluarga Codex daripada OpenAI memegang kelebihan pada tugas pengaturcaraan khusus dalam larian tersebut.
- GDPval-AA Elo (penarafan tugas pakar): Dalam kedudukan agregat gaya Elo untuk tugas pakar, varian Claude Sonnet/Opus mendapat skor lebih tinggi (contohnya, ~1606–1633 mata) manakala satu laporan awam meletakkan Gemini 3.1 Pro pada ~1317 mata dalam set data yang sama — menunjukkan ruang untuk penambahbaikan pada domain pakar tertentu yang sempit.
Hasil percubaan dunia sebenar dan ujian praktikal
Penulisan penganalisis hands-on menunjukkan Gemini 3.1 Pro cemerlang khususnya dalam:
- Peringkasan konteks panjang dan sintesis berbilang dokumen, di mana tetingkap konteks 1M token mengelakkan pemecahan yang mudah terjejas artifak.
- Tugas kefahaman multimodal di mana pembumian imej + teks mempertingkat pengekstrakan fakta.
- Automasi berasaskan agen (contohnya, menyelaraskan rangkaian alat ringkas) — dengan percubaan Antigravity menunjukkan orkestrasi tugas berbilang agen boleh dilaksanakan dengan artifak yang merekod setiap langkah.
Di mana Gemini 3.1 Pro masih ketinggalan (apa yang dinyatakan oleh angka)
Tiada model yang terbaik secara seragam. Ulasan bebas dan ujian komuniti menonjolkan jurang khusus:
- Penanda aras kejuruteraan perisian dan penyelenggaraan kod (SWE-Bench Pro dan seumpamanya) — Gemini 3.1 Pro ketinggalan berbanding pesaing (Claude Opus 4.6 daripada Anthropic) pada tugas yang menguji keupayaan kejuruteraan perisian praktikal: refaktor berskala besar, triage pepijat dalam asas kod yang bersepah dan beberapa jenis pembaikan program automatik. Dengan kata lain, bagi penyelenggaraan kejuruteraan harian, model khusus masih mengekalkan kelebihan dalam sesetengah testbed.
- Mikrotugas sensitif kependaman — kerana Gemini 3.1 Pro ditala untuk kedalaman, tugas yang memerlukan kependaman ultra rendah dan throughput tinggi (contohnya, inferens mikro untuk UI perbualan ringan) mungkin lebih sesuai dengan “Flash” atau varian dioptimum dalam keluarga Gemini.
Apakah harga untuk Gemini 3.1 Pro?
Anda boleh mengakses Gemini 3.1 Pro melalui dua cara — langganan pengguna atau API pembangun — dan harga adalah berbeza bagi setiap satu.
- Pengguna (aplikasi Gemini / Google AI Pro): Akses kepada Gemini 3.1 Pro disertakan dalam langganan Google AI Pro, yang di A.S. ialah $19.99 / bulan (Google turut menawarkan peringkat lebih rendah “AI Plus” dan peringkat lebih tinggi “AI Ultra”). Google.
- Pembangun / API (berasaskan token): Jika anda memanggil model Gemini melalui API pembangun Gemini/AI, harga diukur mengikut token. Untuk pratonton Gemini 3.x Pro, harga pembangun yang diterbitkan adalah kira-kira: $2.00 bagi setiap 1M token input dan $12.00 bagi setiap 1M token output untuk jalur standard (≤200k arahan) — dengan peringkat lebih tinggi (contohnya $4/$18 bagi setiap 1M) untuk konteks yang sangat besar. (Lihat jadual harga API Gemini untuk butiran penuh dan harga kelompok.)
- Jika anda menggunakan Gemini 3.1 Pro melalui CometAPI:
| Harga Comet (USD / Juta Token) | Harga Rasmi (USD / Juta Token) |
|---|---|
| Input:$1.6/M; Output:$9.6/M | Input:$2/M; Output:$12/M |
Harga langganan pengguna (aplikasi Gemini)
Bagi pelan pengguna akhir dalam aplikasi Gemini, Google menyusun peringkat yang mengehadkan akses kepada varian model dan ciri tambahan: Google AI Pro dan Google AI Ultra. Harga berbeza mengikut pasaran dan mata wang; contoh yang diterbitkan menunjukkan Google AI Pro pada $19.99/bulan (dengan percubaan promosi tersedia) dan harga mata wang berperingkat ditunjukkan pada halaman produk (termasuk tawaran percubaan dan kadar dikurangkan jangka pendek). AI Ultra menawarkan akses lebih tinggi (contohnya, akses keutamaan kepada inovasi baharu, kredit lebih tinggi untuk penjanaan video) pada kadar bulanan yang lebih tinggi. Harga pelan pengguna ini kompetitif dengan langganan AI pengguna mewah yang lain dan diposisikan untuk memberikan pengguna berkuasa individu atau pasukan kecil akses kepada ciri 3.1 Pro tanpa integrasi API.
Petua prompt & penggunaan praktikal (apa yang saya akan lakukan)
Gunakan ini untuk mendapatkan hasil yang boleh dipercayai dan berulang:
- Perancang langkah eksplisit
Pola prompt:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Ini memanfaatkan pelaksanaan berperingkat yang lebih kuat dalam 3.1 Pro dan memberi anda titik semak. - Output berstruktur dengan skema
Minta JSON dengan skema danstrict: true. Oleh kerana 3.1 Pro menghasilkan output panjang yang mematuhi skema dengan lebih boleh dipercayai, anda akan mendapat respons tunggal yang lebih besar yang boleh dihuraikan hiliran. - Sandwic semakan alat
Apabila memanggil alat luaran (API, pelaksana kod), minta model menghasilkan: pelan → panggilan alat yang tepat (mesra salin/tampal) → langkah pengesahan. Kemudian sahkan langkah pengesahan di luar model sebelum meneruskan. - Waspada terhadap kepercayaan satu langkah
Walaupun model menulis kod atau arahan yang kelihatan sempurna, jalankan pengesahan bebas (ujian, linter, pelaksanaan dalam kotak pasir) — terutamanya untuk tindakan berasaskan agen/autonomi.
Pengalaman Langsung Dengan Gemini 3.1 Pro
Kes percubaan 1: Pembantu penyelidikan konteks panjang (NotebookLM / Deep Research)
Matlamat: Menilai keupayaan model untuk menyintesis 10–50 dokumen panjang (contohnya, laporan, kertas putih) menjadi ringkasan eksekutif berbilang halaman dengan sitasi dan item tindakan.
Persediaan: Berikan korpus berjumlah 200k–800k token; tugaskan model menghasilkan ringkasan 2–4 halaman dengan sitasi eksplisit dan cadangan “langkah seterusnya”. Gunakan templat prompt yang boleh diulang dan ukur masa, penggunaan token (kos), serta ketepatan fakta.
Keputusan: Peringkasan hujung-ke-hujung lebih pantas dengan artifak pemecahan yang lebih sedikit berbanding model lama, kesetiaan sitasi lebih tinggi dalam ringkasan, dan koheren yang dipertingkat pada skala — dengan kos penggunaan token yang signifikan (jadi rancang bajet). Penanda aras dan ujian praktikal menunjukkan Gemini 3.1 Pro cemerlang dalam sintesis berbilang dokumen kerana tetingkap 1M token.
Kes percubaan 2: Pembantu pengkodan berasaskan agen (Antigravity + GitHub Copilot)
Matlamat: Mengukur pengurangan masa untuk siap bagi tugas pembangun berbilang langkah (contohnya, melaksanakan ciri merentas beberapa fail, menjalankan ujian, membaiki ujian yang gagal).
Persediaan: Gunakan Antigravity atau GitHub Copilot dalam pratonton dengan Gemini 3.1 Pro dipilih. Tentukan tugas yang boleh diulang (penciptaan isu → pelaksanaan → jalankan ujian), log langkah dan artifak agen, dan bandingkan dengan garis dasar manusia sahaja.
Keputusan: Penyelarasan tugas berbilang langkah bertambah baik (perakam artifak, cadangan automatik calon tampalan), penaakulan berbilang fail yang lebih baik berbanding Gemini 3 Pro sebelumnya, dan penjimatan masa yang terukur bagi kerja ciri rutin. Tugas pengnyahpepijatan sistem khusus, aras rendah mungkin masih memihak kepada model khusus berfokus kod (keputusan komuniti menunjukkan jurang berbanding beberapa varian GPT-Codex pada penanda aras terminal tertentu).
Kes percubaan 3: Semakan dokumen undang-undang/perubatan multimodal
Matlamat: Gunakan model untuk mengambil korpus campuran (PDF diimbas, imej, transkrip audio), mengekstrak fakta utama, dan menghasilkan matriks risiko serta tindakan berkeutamaan.
Persediaan: Bekalkan set data dengan imej diimbas dan teks OCR, serta audio sokongan. Ukur ketepatan dalam pengekstrakan entiti bernama, kadar positif palsu, dan keupayaan model merujuk artifak sumber.
Keputusan: Penaakulan bersepadu merentas modaliti yang lebih kukuh dan output yang lebih berjejak (keupayaan menunjuk kepada imej / halaman / cap masa audio yang menyokong suatu dakwaan). Tetingkap konteks panjang mengurangkan keperluan pemecahan dan rujuk silang manual. Namun, dalam domain terkawal, output hendaklah disahkan oleh pakar domain dan satu paip pembumian/pengesahan harus digunakan.
Tanggapan awal (apa yang terasa berbeza)
- Penaakulan berperingkat yang lebih mendalam. Tugas yang sebelum ini memerlukan banyak ulang-alik — contohnya, sintesis berbilang dokumen, matematik/logik berbilang langkah — cenderung selesai dengan lebih sedikit pusingan dan dengan output gaya rantaian pemikiran yang lebih jelas (tanpa mendedahkan teks arahan dalaman). Ini adalah tajuk utama yang ditekankan oleh Google.
- Output berstruktur yang lebih panjang dan berkualiti lebih tinggi. JSON dan automasi bentuk panjang lebih konsisten dan selalunya jauh lebih panjang (sesetengah pengguna melaporkan saiz output jauh lebih besar daripada 3.0). Itu menjadikannya hebat untuk tugas penjana di mana anda mahukan satu payload besar. Jangka untuk mengendalikan output yang lebih besar dan penstriman.
- Pengendalian token/konteks yang lebih cekap. Kecekapan token yang dipertingkat dan kelakuan yang lebih “berasaskan, konsisten fakta” untuk senario penggunaan alat. Itu terserlah dalam lebih sedikit halusinasi pada carian fakta pendek.
Analisis akhir: Adakah Gemini 3.1 Pro berbaloi diterapkan sekarang?
Gemini 3.1 Pro mewakili langkah ke hadapan yang bermakna dalam keluarga Gemini dengan peningkatan dapat dibuktikan pada penanda aras penaakulan, pengkodan dan agen — disokong oleh kad model yang diterbitkan oleh Google dan penjejak bebas yang memetik lonjakan besar pada sesetengah papan pendahulu. Bagi pasukan yang memerlukan penaakulan lanjutan, penyelarasan alat berasaskan agen, atau keupayaan multimodal konteks panjang, 3.1 Pro adalah calon yang meyakinkan.
Pembangun boleh mengakses Gemini 3.1 Pro melalui CometAPI sekarang. Untuk bermula, terokai keupayaan model dalam Playground dan rujuk panduan API untuk arahan terperinci. Sebelum mengakses, pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga jauh lebih rendah daripada harga rasmi untuk membantu anda berintegrasi.
Sedia untuk bermula?→ Daftar untuk Gemini 3.1 pro hari ini !
Jika anda ingin mengetahui lebih banyak petua, panduan dan berita tentang AI ikuti kami di VK, X dan Discord!