

GLM-4.6 ist die neueste Hauptversion in der GLM-Familie von Z.ai (ehemals Zhipu AI): eine 4. Generation, große Sprachen MoE-Modell (Mixture-of-Experts) abgestimmt auf Agenten-Workflows, Long-Context-Reasoning und Real-World-Coding. Die Version legt den Schwerpunkt auf die praktische Agent/Tool-Integration, eine sehr große Kontextfensterund Open-Weight-Verfügbarkeit für die lokale Bereitstellung.
Hauptmerkmale:
- Langer Kontext - einheimisch 200K-Token Kontextfenster (erweitert von 128 KB). ()
- Codierung und Agentenfähigkeit – vermarktete Verbesserungen bei realen Codierungsaufgaben und bessere Toolaufrufe für Agenten.
- Wirkungsgrad — berichtet ~30 % geringerer Token-Verbrauch vs. GLM-4.5 bei den Tests von Z.ai.
- Bereitstellung und Quantisierung – erstmals angekündigte FP8- und Int4-Integration für Cambricon-Chips; native FP8-Unterstützung auf Moore Threads über vLLM.
- Modellgröße und Tensortyp — veröffentlichte Artefakte weisen auf eine ~357B-Parameter Modell (BF16/F32-Tensoren) auf Hugging Face.
Technische Details
Modalitäten und Formate. GLM-4.6 ist ein nur Text LLM (Eingabe- und Ausgabemodalitäten: Text). Kontextlänge = 200 Token; maximale Ausgabe = 128 Token.
Quantisierung und Hardware-Unterstützung. Das Team berichtet FP8/Int4-Quantisierung auf Cambricon-Chips und natives FP8 Ausführung auf Moore Threads GPUs unter Verwendung von vLLM für die Inferenz – wichtig zur Senkung der Inferenzkosten und zur Ermöglichung von On-Premise- und inländischen Cloud-Bereitstellungen.
Werkzeuge und Integrationen. GLM-4.6 wird über die API von Z.ai und Netzwerke von Drittanbietern (z. B. CometAPI) verteilt und in Codieragenten (Claude Code, Cline, Roo Code, Kilo Code) integriert.
Technische Details
Modalitäten und Formate. GLM-4.6 ist ein nur Text LLM (Eingabe- und Ausgabemodalitäten: Text). Kontextlänge = 200 Token; maximale Ausgabe = 128 Token.
Quantisierung und Hardware-Unterstützung. Das Team berichtet FP8/Int4-Quantisierung auf Cambricon-Chips und natives FP8 Ausführung auf Moore Threads GPUs unter Verwendung von vLLM für die Inferenz – wichtig zur Senkung der Inferenzkosten und zur Ermöglichung von On-Premise- und inländischen Cloud-Bereitstellungen.
Werkzeuge und Integrationen. GLM-4.6 wird über die API von Z.ai und Netzwerke von Drittanbietern (z. B. CometAPI) verteilt und in Codieragenten (Claude Code, Cline, Roo Code, Kilo Code) integriert.
Benchmark-Leistung
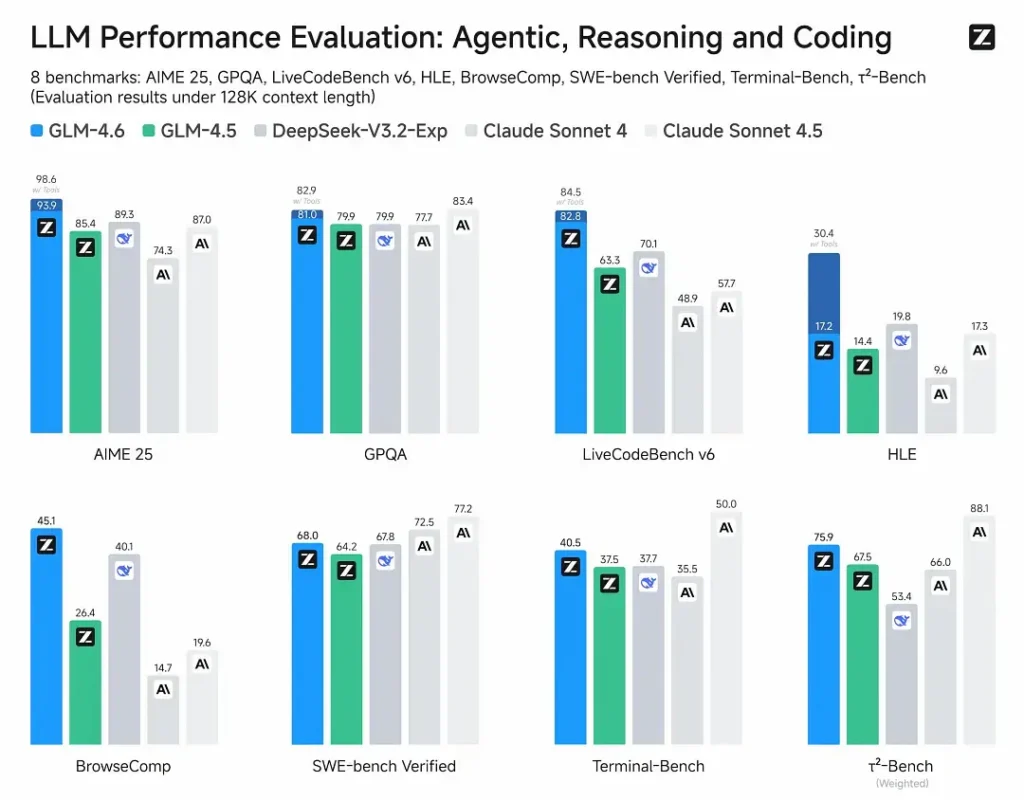
- Veröffentlichte Bewertungen: GLM-4.6 wurde an acht öffentlichen Benchmarks getestet, die Agenten, Argumentation und Kodierung abdecken und zeigt deutliche Gewinne gegenüber GLM-4.5. Bei von Menschen ausgewerteten, realen Codierungstests (erweiterter CC-Bench) verwendet GLM-4.6 ~15 % weniger Token vs GLM-4.5 und veröffentlicht eine ~48.6 % Gewinnrate vs. Anthropics Claude Sonnet 4 (nahezu Parität auf vielen Bestenlisten).
- Positionierung: Die Ergebnisse zeigen, dass GLM-4.6 mit führenden nationalen und internationalen Modellen konkurrieren kann (zu den genannten Beispielen zählen DeepSeek-V3.1 und Claude Sonnet 4).
Einschränkungen und Risiken
- Halluzinationen und Fehler: Wie alle aktuellen LLMs kann GLM-4.6 sachliche Fehler enthalten – und tut dies auch. Die Dokumentation von Z.ai weist ausdrücklich darauf hin, dass die Ausgaben Fehler enthalten können. Benutzer sollten bei kritischen Inhalten Verification & Retrieval/RAG anwenden.
- Modellkomplexität und Bereitstellungskosten: 200 Kontexte und sehr große Ausgaben erhöhen den Speicher- und Latenzbedarf drastisch und können die Inferenzkosten erhöhen. Für eine Ausführung im großen Maßstab ist eine quantisierte Inferenztechnik erforderlich.
- Domänenlücken: Während GLM-4.6 eine starke Agenten-/Codierungsleistung meldet, weisen einige öffentliche Berichte darauf hin, dass es immer noch hinkt bestimmten Versionen hinterher konkurrierender Modelle in bestimmten Mikrobenchmarks (z. B. einige Codierungsmetriken im Vergleich zu Sonnet 4.5). Bewerten Sie die einzelnen Aufgaben, bevor Sie Produktionsmodelle ersetzen.
- Sicherheit und Richtlinien: Offene Gewichte erhöhen die Zugänglichkeit, werfen aber auch Fragen zur Verwaltung auf (Minderungsmaßnahmen, Leitplanken und Red-Teaming bleiben in der Verantwortung des Benutzers).
Anwendungsszenarien
- Agentensysteme und Tool-Orchestrierung: lange Agentenspuren, Multitool-Planung, dynamischer Tool-Aufruf; die Agentenoptimierung des Modells ist ein wichtiges Verkaufsargument.
- Codierassistenten aus der Praxis: Multiturn-Codegenerierung, Codeüberprüfung und interaktive IDE-Assistenten (integriert in Claude Code, Cline, Roo Code – pro Z.ai). Verbesserungen der Token-Effizienz machen es für Entwicklerpläne mit hoher Nutzung attraktiv.
- Workflows für lange Dokumente: Zusammenfassung, Synthese mehrerer Dokumente, lange rechtliche/technische Überprüfungen aufgrund des 200K-Fensters.
- Inhaltserstellung und virtuelle Charaktere: erweiterte Dialoge, konsistente Persona-Pflege in Szenarien mit mehreren Runden.
Vergleich des GLM-4.6 mit anderen Modellen
- GLM-4.5 → GLM-4.6: sprunghafte Veränderung in Kontextgröße (128K → 200K) kombiniert mit einem nachhaltigen Materialprofil. Token-Effizienz (~15 % weniger Token auf CC-Bench); verbesserte Agenten-/Tool-Nutzung.
- GLM-4.6 vs. Claude Sonnet 4 / Sonnet 4.5: Z.ai-Berichte nahezu Parität auf mehreren Bestenlisten und eine Gewinnrate von ~48.6 % bei den CC-Bench-Codieraufgaben in der realen Welt (d. h. ein enger Wettbewerb mit einigen Mikrobenchmarks, bei denen Sonnet immer noch führt). Für viele Entwicklungsteams stellt GLM-4.6 eine kostengünstige Alternative dar.
- GLM-4.6 im Vergleich zu anderen Long-Context-Modellen (DeepSeek, Gemini-Varianten, GPT-4-Familie): GLM-4.6 legt den Schwerpunkt auf große Kontext- und agentenbasierte Codierungs-Workflows; die relativen Stärken hängen von der Metrik ab (Token-Effizienz/Agenten-Integration vs. Genauigkeit der Rohcode-Synthese oder Sicherheits-Pipelines). Die empirische Auswahl sollte aufgabenorientiert erfolgen.
Zhipu AIs neuestes Flaggschiffmodell GLM-4.6 veröffentlicht: 355 B Gesamtparameter, 32 B aktiv. Übertrifft GLM-4.5 in allen Kernfunktionen.
- Kodierung: Entspricht Claude Sonnet 4, das Beste in China.
- Kontext: Erweitert auf 200 K (von 128 K).
- Begründung: Verbessert, unterstützt Tool-Aufrufe während der Inferenz.
- Suche: Verbesserte Tool-Aufruf- und Agentenleistung.
- Schreiben: Entspricht in Stil, Lesbarkeit und Rollenspiel besser den menschlichen Vorlieben.
- Mehrsprachig: Verbesserte sprachübergreifende Übersetzung.
Wie man anruft GLM-**4.**6 API von CometAPI
GLM‑4.6 API-Preise in CometAPI, 20 % Rabatt auf den offiziellen Preis:
- Eingabe-Token: 0.64 Mio. $ Token
- Ausgabe-Token: 2.56 $/M Token
Erforderliche Schritte
- Einloggen in cometapi.com. Wenn Sie noch kein Benutzer bei uns sind, registrieren Sie sich bitte zuerst.
- Melden Sie sich in Ihrem CometAPI-Konsole.
- Holen Sie sich den API-Schlüssel für die Zugangsdaten der Schnittstelle. Klicken Sie im persönlichen Bereich beim API-Token auf „Token hinzufügen“, holen Sie sich den Token-Schlüssel: sk-xxxxx und senden Sie ihn ab.

Methode verwenden
- Wählen Sie das "
glm-4.6”-Endpunkt, um die API-Anfrage zu senden und den Anfragetext festzulegen. Die Anfragemethode und der Anfragetext stammen aus der API-Dokumentation unserer Website. Unsere Website bietet außerdem einen Apifox-Test für Ihre Bequemlichkeit. - Ersetzen mit Ihrem aktuellen CometAPI-Schlüssel aus Ihrem Konto.
- Geben Sie Ihre Frage oder Anfrage in das Inhaltsfeld ein – das Modell antwortet darauf.
- . Verarbeiten Sie die API-Antwort, um die generierte Antwort zu erhalten.
CometAPI bietet eine vollständig kompatible REST-API für eine nahtlose Migration. Wichtige Details zu API-Dokument:
- Basis-URL: https://api.cometapi.com/v1/chat/completions
- Modellnamen: "
glm-4.6" - Authentifizierung:
Bearer YOUR_CometAPI_API_KEYKopfzeile - Content-Type:
application/json.
API-Integration und Beispiele
Unten ist eine Python Snippet, das zeigt, wie GLM‑4.6 über die API von CometAPI aufgerufen wird. Ersetzen Sie <API_KEY> kombiniert mit einem nachhaltigen Materialprofil. <PROMPT> entsprechend:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
Parameter:
- Modell: Gibt die GLM‑4.6-Variante an
- max_tokens: Steuert die Ausgabelänge
- Temperatur: Gleicht Kreativität vs. Determinismus aus
Web Link Claude Sonnet 4.5