

Am 3. März 2026 stellte Google Gemini 3.1 Flash-Lite vor, das neueste Mitglied der Gemini-3-Familie, das speziell als Engine mit hohem Durchsatz, niedriger Latenz und hoher Kosteneffizienz für Entwickler- und Enterprise-Workloads entwickelt wurde. Google positioniert Flash-Lite als das „schnellste und kosteneffizienteste“ Modell der Gemini-3-Reihe: eine leichtgewichtige Variante, die auf Streaming-Interaktionen, großskalige Hintergrundverarbeitung und hochfrequente Produktionstasks (zum Beispiel Übersetzung, Extraktion, UI-Generierung und Klassifizierung in großen Mengen) abzielt – und dies zu einem deutlich niedrigeren Preis als die Pro-Varianten.
Im Folgenden erläutern wir, was Flash-Lite ist.
Was ist Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite ist ein Mitglied der Gemini-3-Familie von Google, das bewusst einen Teil der höchsten Reasoning-Tiefe gegen Geschwindigkeit und Kosteneffizienz eintauscht. Es ist in der Gemini-Linie nativ multimodal (kann Text, Bilder und andere Modalitäten als Eingabe akzeptieren), wurde jedoch speziell darauf abgestimmt und bereitgestellt, einen maximalen Tokens-pro-Sekunde-Durchsatz und deutlich niedrigere Abrechnung pro Token für Workloads zu liefern, die schnelle, wiederholte Inferenz statt maximaler kognitiver Tiefe erfordern. Das Modell wird als von der 3.1-Pro-Architektur abgeleitet beschrieben, jedoch auf Durchsatz, Latenz und Kosten optimiert.
Zentrale Konstruktionskompromisse
Die Bezeichnung „Lite“ signalisiert den ingenieurtechnischen Schwerpunkt des Modells:
- Durchsatz statt schwergewichtigem Reasoning: Flash-Lite reduziert die Rechenleistung pro Token bewusst, um eine schnellere Time-to-First-Token (TTFT) und eine kontinuierlich hohe Ausgabe-Geschwindigkeit zu erzielen. Das macht es ideal für Pipelines, in denen jede Anfrage schnell und in großem Maßstab bedient werden muss (z. B. Safety-Filter, Echtzeit-Assistenten, Generierung in hohem Volumen).
- Kosteneffizienz für hohe Volumina: Durch die Senkung des Compute-Anteils pro Token kann das Modell zu niedrigeren Preisen pro Million Token angeboten werden, was die Grenzkosten in groß angelegten Anwendungen reduziert (z. B. Millionen bis Milliarden Token pro Monat). Googles Vorschaupreise zeigen einen deutlichen Unterschied gegenüber der Pro-Stufe.
- Qualität auf pragmatische Aufgaben abgestimmt: Laut frühen Bewertungssummen hält Flash-Lite starke Ergebnisse bei Standardklassifikation, Mehrsprachigkeit und vielen multimodalen Aufgaben, ist jedoch nicht darauf ausgerichtet, Pro bei den komplexesten Multi-Step-Reasoning- oder Codegenerierungs-Benchmarks zu schlagen, bei denen Tiefe entscheidend ist.
Diese Workloads erfordern zuverlässige Ausgaben und hohen Durchsatz, benötigen jedoch nicht immer die komplexen mehrstufigen Reasoning-Fähigkeiten von Flaggschiffmodellen.
Zentrale Funktionen von Gemini 3.1 Flash-Lite
1. Geringe Latenz und schnelle Zeit bis zum ersten Token
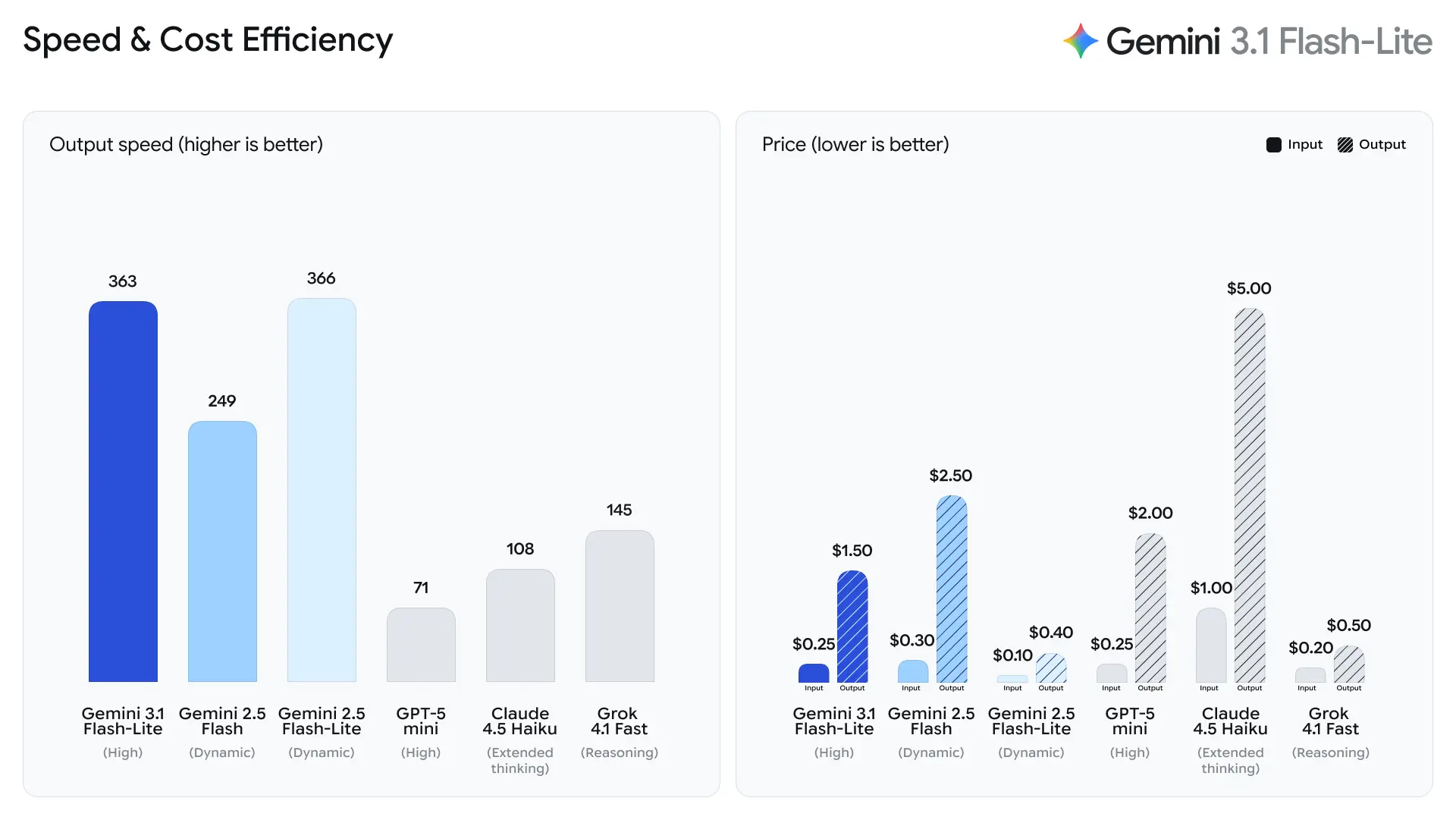
Google betont die Zeit bis zum ersten Antwort-Token als primäre Metrik für Flash-Lite. Das Unternehmen berichtet von einer ~2.5× schnelleren Zeit bis zum ersten Token im Vergleich zu Gemini 2.5 Flash und von bis zu 45% schnellerer Ausgabeerzeugung — Verbesserungen, die die wahrgenommene Reaktionsfähigkeit für Endnutzer und die Durchsatzkosten für Back-End-Systeme direkt beeinflussen. Diese Zugewinne machen Flash-Lite gut geeignet für interaktive Funktionen (z. B. Chatbots in Apps) und High-QPS-Pipelines, in denen Mikrosekunden zählen.
Diese Verbesserung steigert Echtzeitanwendungen deutlich, etwa:
- konversationelle KI
- KI-gestützte Suchassistenten
- interaktive Chatbots
- Live-Übersetzungsdienste
Geringere Latenz verbessert die Nutzererfahrung, indem die Wartezeit reduziert und flüssigere Interaktionen ermöglicht werden.
2. Kosteneffiziente Token-Preise
KI-Inferenzkosten werden häufig pro Token berechnet, wodurch die Preisgestaltung für groß angelegte Bereitstellungen ein kritischer Faktor ist.
Gemini 3.1 Flash-Lite führt eine äußerst wettbewerbsfähige Preisstruktur ein:
| Tokentyp | Preis |
|---|---|
| Eingabetoken | $0.25 pro 1M Token |
| Ausgabetoken | $1.50 pro 1M Token |
Dies stellt eine Reduktion gegenüber früheren Flash-Modellen dar und macht das Modell attraktiv für Organisationen mit großen Workloads.
Zum Vergleich:
| Modell | Eingabepreis | Ausgabepreis |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Diese Preisstrategie ermöglicht es Entwicklern, KI im großen Maßstab zu betreiben, ohne die Betriebskosten dramatisch zu erhöhen.
Wenn Sie einen noch besseren Preis suchen, bietet Gemini Flash-Lite einen Rabatt von 20% auf CometAPI.
3. „Denkstufen“ (steuerbare Inferenztiefe)
Gemini 3.1 Flash-Lite umfasst die Fähigkeit der „Denkstufen“ — ein von Entwicklern konfigurierbarer Regler, der das Modell anweist, bei trivialen Aufgaben schnelleres, oberflächlicheres Verarbeiten zu bevorzugen und bei schwierigeren Aufgaben tieferes Reasoning einzusetzen. Dies ist in der Praxis wichtig, weil es dynamische Kosten-/Latenz-Trade-offs pro Anfrage ermöglicht, ohne die Modelle zu wechseln.
Entwickler können die Reasoning-Tiefe des Modells an die Komplexität der Aufgabe anpassen. Denkstufen: Unterstützt vier Stufen: Minimal, Low, Medium und High.
Dieser dynamische Ansatz ermöglicht es Anwendungen, den Ressourceneinsatz zu optimieren, während die Qualität dort erhalten bleibt, wo sie zählt. Die praktische Strategie sieht ungefähr wie folgt aus:
- Minimal/Low: Geeignet für hochgradig gleichzeitige, aber logisch einfache Aufgaben wie Übersetzung, Klassifikation und Sentimentanalyse; priorisiert maximale Geschwindigkeit und minimale Kosten.
- Medium: Geeignet für die meisten Produktionsaufgaben, mit einem Ausgleich zwischen Qualität und Effizienz.
- High: Geeignet für Aufgaben, die tiefes Reasoning erfordern, wie das Generieren von Benutzeroberflächen, das Erstellen von Simulationen und das Ausführen komplexer Anweisungen.
4. Multimodale Fähigkeiten mit „leichtem“ Footprint
Obwohl Flash-Lite auf Geschwindigkeit und Kosten optimiert ist, behält es die multimodalen Grundlagen der Gemini-3-Reihe bei: Es kann Bildeingaben für Klassifikation oder leichtes multimodales Reasoning akzeptieren, wenn der Anwendungsfall dies erfordert — Entwickler sollten jedoch erwarten, dass das wirtschaftliche Design kürzere, begrenzte multimodale Operationen gegenüber sehr großen, bildlastigen Workflows bevorzugt. Wie andere Gemini-Modelle unterstützt Gemini 3.1 Flash-Lite multimodale Eingaben, sodass Entwickler unterschiedliche Datentypen verarbeiten können.
Unterstützte Eingaben umfassen:
- Text
- Bilder
- Video
- Audio
- PDFs
Die Fähigkeit des Modells, mehrere Arten von Informationen zu analysieren, ermöglicht neue Anwendungsfälle, wie:
- automatisierte Dokumentenverarbeitung
- visuelle Datenextraktion
- multimediale Zusammenfassung
Frühere Gemini-Modelle zeigten ebenfalls starke multimodale Reasoning-Fähigkeiten in visuellen und Wissens-Benchmarks.
Leistungsbenchmarks — reale Zahlen und ihre Bedeutung
Googles Ankündigung und Produktdokumentation präsentieren mehrere Benchmarkdatenpunkte, die Käufern helfen sollen zu verstehen, wo Flash-Lite im Ökosystem steht.
Entwicklerorientierte Geschwindigkeitsmetriken
- 2.5× schneller Zeit bis zum ersten Antwort-Token gegenüber Gemini 2.5 Flash (Googles angegebener interner Vergleich).
- 45% schnellere Ausgabeerzeugung gegenüber Gemini 2.5 Flash.
Dies sind performanceorientierte Metriken statt menschlich beurteilter Qualitätsmetriken; sie spiegeln Verbesserungen in der Laufzeit-Mikroarchitektur, beim Batching und bei Inferenz-Stack-Optimierungen wider, die die Latenz für kurze Antworten senken. Schnellere Zeiten bis zum ersten Token reduzieren die wahrgenommene Verzögerung in interaktiven Anwendungen und erhöhen den Gesamtdurchsatz pro Server, was die Gesamtrechenkosten bei gleicher QPS senken kann.
Tokens pro Sekunde (t/s) und Durchsatz
Laut Testdaten von Artificial Analysis erreichte 3.1 Flash-Lite eine Ausgabegeschwindigkeit von 388.8 Token pro Sekunde (der Median für Modelle in derselben Preisklasse liegt nur bei 96.7 Token/Sekunde). Diese Geschwindigkeit gehört zur Spitzenklasse unter den Modellen seiner Klasse.
Allerdings wies Artificial Analysis auch auf ein Problem hin: Die Erst-Token-Latenz (TTFT) von 3.1 Flash-Lite beträgt 5.18 Sekunden, was für Inferenzmodelle in derselben Preisklasse relativ hoch ist (der Median liegt bei 1.82 Sekunden). Zusätzlich generierte das Modell während des Evaluierungsprozesses 53 Millionen Token, was im Vergleich zum Durchschnitt von 20 Millionen relativ hoch ist. Das bedeutet, dass Sie, wenn Ihr Szenario sehr sensitiv gegenüber der Erst-Token-Latenz ist oder strenge Anforderungen an die Ausgabeknappheit hat, die Denkstufe und die Prompts optimieren sollten.
Benchmark-Ergebnisse für Reasoning und Faktentreue
Google schloss modellübergreifende Vergleiche ein, die zeigen, dass Gemini 3.1 Flash-Lite bei aggregierten Reasoning-/Faktenaufgaben stark gegenüber Wettbewerbern und früheren Gemini-Varianten abschneidet:
- Arena.ai-Elo-Wert: Gemini 3.1 Flash-Lite erreichte Berichten zufolge einen Elo von 1432 auf der Arena-Evaluierungsrangliste — ein zusammengesetztes Head-to-Head-Ranking, das eine wettbewerbsfähige relative Leistung in Direktvergleichen zeigt.
- GPQA Diamond: 86.9% (ein Maß für die Robustheit beim Beantworten von Fragen).
- MMMU Pro: 76.8% (eine multimodale/multitask Metrik, die intern/extern von einigen Labs verwendet wird).
- LiveCodeBench (Coding-Fähigkeit): 72.0%
- CharXiv Reasoning (Grafisches Reasoning): 73.2%
- Video-MMMU (Videoverständnis): 84.8%
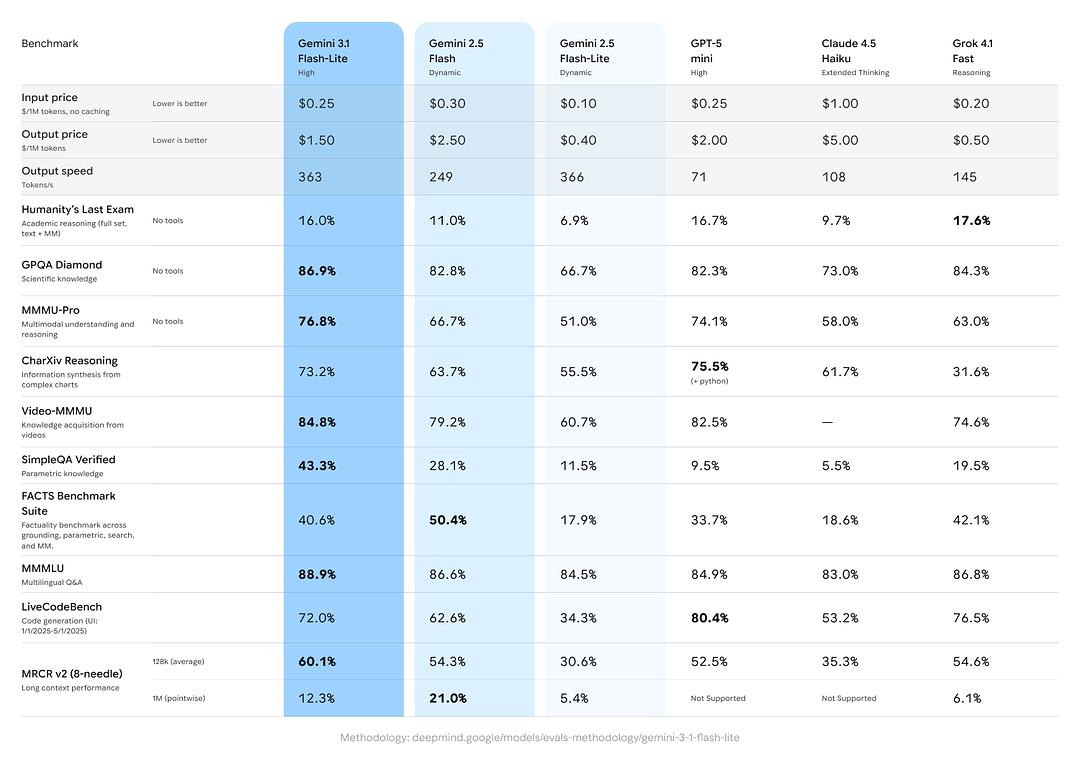
Gemini 3.1 Flash-Lite übertrifft das ältere Gemini 2.5 Flash bei mehreren dieser Metriken und liefert gleichzeitig deutlich bessere Geschwindigkeit/Kosten.
Anwendungsfälle, die zu Gemini 3.1 Flash-Lite passen
Gemini 3.1 Flash-Lite ist um eine klare Reihe praktischer Workloads herum konzipiert, bei denen hoher Durchsatz und niedrigere Kosten pro Token entscheidend sind:
Hochfrequente Konversationsagenten & Streaming-UI
Echtzeit-Chatbots, Live-Transkriptions- und Übersetzungsstreams sowie kollaborative UIs, die Teilantworten während der Generierung anzeigen, profitieren von der Streaming-Token-Ausgabe und der geringen Zeit bis zum ersten Token von Flash-Lite.
Massen-Datenverarbeitung (RAG, Transformationspipelines)
Massive Dokumentenaufnahme: Entitätsextraktion, Metadaten-Tagging, Klassifikation und Übersetzungsaufgaben über Millionen von Dokumenten — Gemini 3.1 Flash-Lite senkt die Inferenzkosten und bietet gleichzeitig eine ausreichende Genauigkeit für vorlagen- oder regelgetriebene Ausgaben.
Edge-ähnliche oder Hintergrundberechnungen
Workloads, die eingehende Telemetrie oder unstrukturierte Daten kontinuierlich verarbeiten (z. B. Klassifikationspipelines zur Inhaltsmoderation, automatisierte Berichtserstellung), sind gut geeignet, da Gemini 3.1 Flash-Lite die Kosten pro Einheit minimiert.
Entwickler-Tooling und Batch-Codevervollständigung
Für Funktionen wie Multi-File-Gerüste, großskaliges Code-Linting und Vorlagenerstellung im großen Maßstab senken die Geschwindigkeitsvorteile von Gemini 3.1 Flash-Lite Latenz und Kosten für Developer-Experience-Tools, bei denen keine absolut maximale Reasoning-Tiefe erforderlich ist.
Vergleich von Gemini 3.1 Flash-Lite mit anderen Gemini-Modellen und Wettbewerbern
Innerhalb der Gemini-Familie
- Gemini 3.1 Pro: höchste Leistungsfähigkeit bei komplexem Reasoning und mehrstufiger Planung; pro Token deutlich teurer und langsamer, aber besser für tiefgehende, nuancierte Aufgaben.
- Gemini 3.1 Flash (non-Lite): zielt auf einen Mittelweg zwischen rohem Durchsatz und Leistungsfähigkeit — Flash-Lite optimiert weiter unten im Compute-Stack auf Durchsatz.
Gegenüber konkurrierenden „schnellen“ Modellen
Gemini 3.1 Flash-Lite übertrifft oder erreicht mehrere schnelle/„Mini“-Modelle bei vielen Durchsatz- und Qualitätsmetriken — unabhängige Analysten warnen jedoch, dass direkte Head-to-Head-Vergleiche empfindlich auf Evaluierungsmethodik und Datensatzwahl reagieren. Erwarten Sie, dass Gemini 3.1 Flash-Lite beim Durchsatz und bei den Kosten hoch wettbewerbsfähig ist, während es bei den höchsten Reasoning-Metriken im Mittelfeld bleibt.
Fazit — wo Flash-Lite im KI-Stack passt
Gemini 3.1 Flash-Lite ist ein bewusst entwickeltes Angebot: ein effizientes, durchsatzorientiertes Mitglied der Gemini-3-Familie, das es Teams ermöglicht, etwas Pro-Beispiel-Compute gegen drastische Verbesserungen bei Latenz und Kosten einzutauschen. Für Unternehmen und Entwickler, die hochvolumige Pipelines aufbauen — Übersetzungen, Batch-Verarbeitung, Streaming-UIs und Aufgaben mit moderater Komplexität — stellt Flash-Lite eine sinnvolle Baseline-Engine dar. Für Organisationen, die die absolut höchste Reasoning-Fidelity benötigen, bleiben die Pro-Modelle die richtige Wahl.
Wenn Ihr Workload von vielen kurzen, wiederholbaren Inferenzläufen dominiert wird oder Sie schnelle Streaming-Ausgabe im großen Maßstab benötigen, lohnt es sich, Flash-Lite zu pilotieren. Wenn Ihr Workload auf tiefem Multi-Hop-Reasoning beruht, planen Sie einen hybriden Ansatz: Leiten Sie Durchsatzverkehr an Flash-Lite und eskalieren Sie hochwertige, komplexe Anfragen an Pro-Modelle.
Entwickler können Gemini 3.1 Flash Lite jetzt über CometAPI nutzen. Um zu beginnen, erkunden Sie die Fähigkeiten des Modells im Playground und konsultieren Sie den API-Guide für detaillierte Anweisungen. Bevor Sie zugreifen, stellen Sie bitte sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bietet einen Preis, der weit unter dem offiziellen Preis liegt, um Ihnen die Integration zu erleichtern.
Ready to Go?→ Sign up fo Gemini 3.1 Flash lite today !
Wenn Sie mehr Tipps, Anleitungen und News zu KI erfahren möchten, folgen Sie uns auf VK, X und Discord!