

xAI dikeluarkan secara senyap-senyap Grok 4.1 (17–18 Nov 2025) — peningkatan tertumpu kepada Grok 4 yang mengutamakan kecerdasan emosi, ekspresi kreatif, dan mengurangkan halusinasi sambil mengekalkan alasan yang tajam dari keluaran Grok sebelum ini. Ia tiba dalam dua mod (Berfikir / Tidak Berfikir), telah dilancarkan secara senyap pada awal November, menunjukkan keputusan papan pendahulu teratas pada LMArena dan tersedia melalui grok.com, apl Grok dan API.
Apakah Grok 4.1?
Grok 4.1 ialah pengganti bertumpu pengeluaran tambahan kepada Grok 4: ahli keluarga yang dibina di atas asas pembelajaran pengukuhan berskala besar yang sama tetapi diperhalusi dan dilatih semula dengan pengoptimuman berat selepas latihan yang bertujuan untuk gaya, personaliti, penjajaran dan kebolehpercayaan dunia sebenar. Ia diletakkan sebagai langkah ke hadapan yang pragmatik dan "boleh digunakan": lebih bijak dalam ujian keutamaan manusia buta, lebih pintar dari segi emosi, lebih baik dalam penulisan kreatif dan agak kurang terdedah kepada jenis "halusinasi" yakin tetapi salah yang telah menjejaskan LLM berprestasi tinggi sebelum ini.
Grok 4.1 mencapai perubahan kualitatif dalam empat dimensi berikut:
- Kreativiti: Menunjukkan gaya bahasa dan imaginasi yang lebih kuat dalam penulisan, penceritaan dan konteks sosial;
- Kecerdasan Emosi: Mengenali perubahan nada dan emosi, bertindak balas dengan lebih logik emosi seperti manusia dan menjana tindak balas yang selesa dan memahami;
- Kesepaduan Personaliti: Mengekalkan nada dan personaliti yang konsisten dalam perbualan yang panjang, tidak lagi mempamerkan tingkah laku tidak konsisten model terdahulu;
- Kolaboratif: Mengekalkan kesepaduan dan kesedaran matlamat dalam dialog berbilang giliran atau kerjasama tugas.
xAI meringkaskan ciri-cirinya dalam satu ayat: "Ia lebih perseptif, lebih empati dan lebih seperti orang yang koheren."
Bagaimanakah Grok 4.1 berfungsi di bawah hud?
Grok 4.1 paling baik difahami sebagai tulang belakang pra-latihan yang sama digunakan di seluruh keluarga Grok 4 serta saluran paip pasca latihan berlapis yang memfokuskan pemodelan ganjaran, penjajaran gaya dan penilai agen.
Apakah peringkat latihan dan penjajaran?
Grok 4.1 berfungsi pada saluran paip berbilang peringkat tipikal LLM sempadan moden, disesuaikan dengan dua anjakan penting untuk 4.1:
- Pra-latihan + pertengahan latihan: Pra-latihan korpus besar pada data web + latihan pertengahan yang disasarkan untuk meningkatkan pengetahuan domain dan keupayaan berbilang modal.
- Penalaan halus diselia (SFT): Demonstrasi manusia untuk tingkah laku yang diingini (balas, strategi penolakan).
- Pemodelan ganjaran (aplikasi novel): Model ganjaran terlatih xAI bukan sahaja pada label keutamaan manusia tetapi juga digunakan model penaakulan agen sempadan sebagai penggred ganjaran — dengan berkesan membenarkan penilai berasaskan model berkeupayaan tinggi menjaringkan output calon pada skala. Ini membolehkan pengoptimuman atribut tidak boleh disahkan seperti gaya, kesepaduan personaliti, empati dan tolong menolong tanpa memerlukan belanjawan pelabelan manusia yang sangat besar.
- Pengoptimuman dasar (RLHF / RL daripada ganjaran model): Pengoptimuman dasar standard menggunakan isyarat ganjaran yang dipelajari untuk menghasilkan dasar yang digunakan (model yang berinteraksi dengan pengguna).
Apakah yang baharu dalam pendekatan pemodelan ganjaran?
Dalam RLHF tradisional anda mengumpulkan label keutamaan manusia (A/B), melatih model ganjaran untuk meramalkan label tersebut, dan kemudian mengoptimumkan model asas dengan RL (atau pensampelan penolakan) terhadap ganjaran yang dipelajari itu. Tetapi Dua inovasi praktikal xAI menyerlahkan:
- Model ganjaran agen: bukannya hakim manusia semata-mata, xAI menggunakan model penaakulan "agentik" yang berkebolehan sebagai penjaring untuk menilai sifat yang lebih halus (nada, nuansa emosi, kreativiti). Penggred boleh menjalankan beribu-ribu perbandingan berpasangan dengan cepat, membolehkan jurutera bergerak lebih cepat. Ini adalah mekanisme untuk penambahbaikan besar dalam gaya dan kecerdasan emosi.
- Penjajaran selepas latihan untuk isyarat yang tidak boleh disahkan: untuk atribut yang anda tidak boleh ukur dengan metrik deterministik (cth, "kehangatan" atau "personaliti koheren") mereka memperkenalkan objektif ganjaran khusus dan penskalaan kurikulum supaya model mempelajari gaya output tanpa mengorbankan ketepatan fakta teras.
Bagaimanakah "berfikir" vs "tidak berfikir" beroperasi secara teknikal?
- Grok 4.1 Berfikir (nama kod
quasarflux) — mendedahkan langkah penaakulan eksplisit (token pemikiran) sebelum menghasilkan jawapan akhir; dioptimumkan untuk tugas yang kompleks dan Elo yang lebih tinggi dalam LMArena. Token tambahan memerlukan masa inferens tetapi membantu dengan tugas penaakulan berbilang langkah, penyahpepijatan dan kebolehjelasan. - Grok 4.1 Tidak Berfikir (nama kod
tensor) memintas token perantaraan yang jelas untuk satu respons akhir serta-merta. Ini mengurangkan kependaman dan kos token sementara masih mendapat manfaat daripada wajaran dasar yang diperhalusi yang sama. Mod tidak berfikir telah dioptimumkan untuk menjadi sangat kependaman rendah dan masih berkeupayaan tinggi.
Pengoptimuman penjajaran sentimen dan gaya
Di luar isyarat "kebenaran" yang mudah, Grok 4.1 termasuk pengoptimuman penjajaran disasarkan untuk sentimen, nada dan gaya interpersonal. Ini bermakna saluran paip latihan termasuk komponen ganjaran atau kerugian yang secara eksplisit menghukum nada yang tidak sepadan (cth, bertegas tanpa perlu apabila empati sesuai) dan respons ganjaran yang sepadan dengan gaya atau profil sentimen yang diingini. Dalam Grok 4.1, AI mula-mula memperkenalkan objektif pengoptimuman "Penjajaran Peribadi."
Ia bertujuan untuk membantu model mengekalkan rasa identiti yang konsisten dan stabil. Berbanding dengan Grok 4, 4.1 menambah perkara berikut kepada objektif latihan:
- Ganjaran positif untuk dimensi ekspresi emosi (ganjaran penjajaran emosi);
- Metrik kesepaduan personaliti.
Bagaimanakah Grok 4.1 dinilai — dan bagaimana prestasinya?
Apakah yang ditunjukkan oleh ujian keutamaan manusia buta?
Semasa pelancaran senyap, Grok 4.1 lebih disukai 64.78% berbanding model pengeluaran sebelumnya dalam trafik langsung — isyarat keutamaan manusia yang kuat yang menunjukkan hasil perbualan yang lebih baik di alam liar.
Adakah Grok 4.1 papan pendahulu teratas?
xAI melaporkan bahawa Grok 4.1's Berfikir mod duduk di #1 di Arena Teks LMArena, dengan Elo yang dilaporkan daripada 1483, dan mod tidak beralasan (pantas) berada di kedudukan #2 dengan 1465 Elo — peletakan papan pendahulu awam yang kukuh untuk ketepatan dan persembahan (kawalan gaya memainkan peranan).
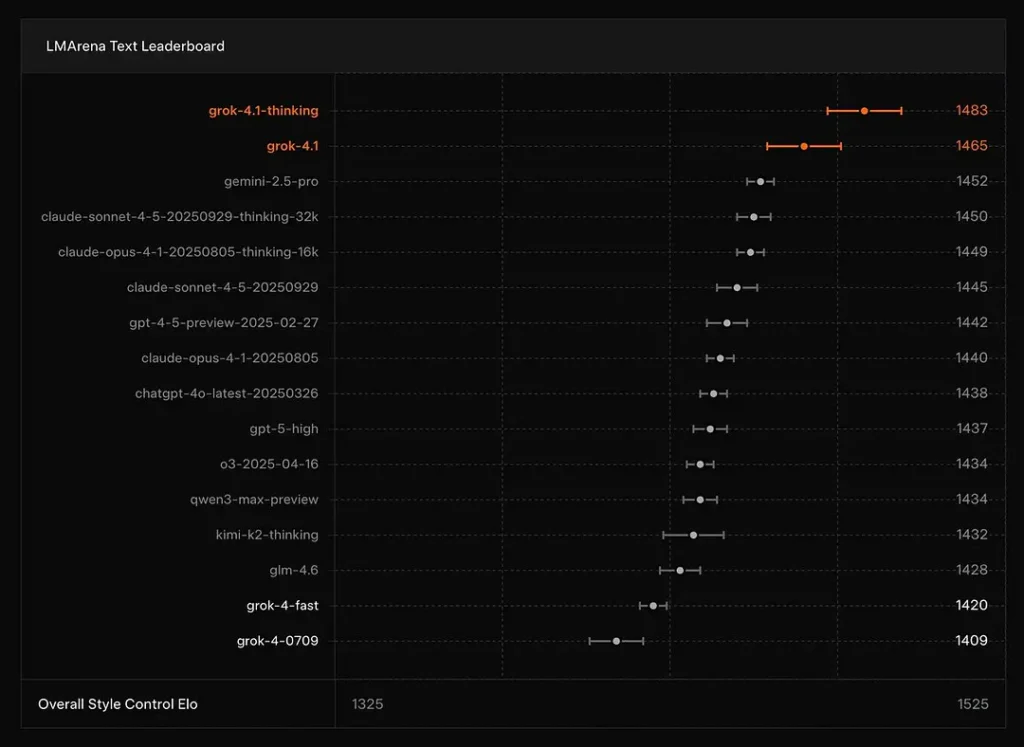
Kesimpulan: Grok 4.1 mengatasi model siri GPT-4.5 dan Claude arus perdana dalam pemahaman teks, penjanaan dan kualiti keseluruhan, kedua selepas versi Pratonton Lanjutan GPT-5.
Kecerdasan Emosi
xAI menjalankan EQ-Bench3, ujian khusus untuk kecerdasan emosi yang meliputi 45 senario lakonan yang mencabar, dan melaporkan bahawa Grok 4.1 menunjukkan peningkatan yang kukuh dalam empati, rentak dan cerapan interpersonal.Grok 4.1 mendapat markah tertinggi dalam memahami konteks kesedihan, empati dan keselesaan.

Penulisan kreatif — adakah ia sebenarnya lebih imaginatif?
Grok 4.1 telah dinilai pada Penulisan Kreatif v3 (32 gesaan merentas 3 lelaran dengan rubrik + pemarkahan Elo). xAI mengatakan gaya penulisan 4.1, konsistensi suara dan kreativiti naratif meningkat dengan ketara, meletakkannya berhampiran bahagian atas papan pendahulu baru-baru ini untuk tugas kreatif (contoh gesaan disertakan dalam keluaran). Pelaporan bebas mencerminkan penemuan ini: pengulas melihat lebih banyak "suara tersendiri" dan koheren bentuk panjang yang lebih baik. Dari segi kualiti penulisan, Grok 4.1 berada di tempat kedua selepas model siri GPT-5 dan mengatasi keseluruhan barisan produk Claude, Gemini dan Kimi.

Mengurangkan halusinasi / kejujuran
xAI mendakwa pengurangan ketara dalam kadar halusinasi: mereka melaporkan (dalam pengumuman dan siaran sosial) Grok 4.1 ialah ~3× kurang berkemungkinan untuk berhalusinasi berbanding dengan model Grok terdahulu, memetik analisis trafik pengeluaran dan penilaian gaya FActScore (cth, set soalan bio/biografi, lebih rendah adalah lebih baik). Terutamanya dalam "mod bukan alasan" di mana alat carian luaran tersedia, ketekalan fakta adalah lebih stabil.

Mengapa Grok 4.1 "menghancurkan" model lain — adakah itu hiperbola?
"Crushes" adalah seperti pemasaran, tetapi terdapat tuntutan objektif di sebalik tuntutan itu:
- Papan pendahulu: Grok 4.1 memegang kedudukan teratas pada papan pendahulu LMArena awam untuk penjanaan teks (1483 Elo untuk mod Berfikir) dan persembahan bangku kreatif dan EQ yang kukuh setiap keluaran xAI. Itu adalah metrik persaingan epal-ke-epal yang digunakan merentas komuniti.
- Keutamaan trafik sebenar menang: xAI melaporkan kemenangan keutamaan manusia dalam perbandingan buta (~65% keutamaan berbanding model pengeluaran terdahulu) daripada pelancaran senyap pada trafik langsung. Itu mencerminkan peningkatan pengguna sebenar, bukan hanya penanda aras kertas.
- Keupayaan baharu yang praktikal: Gabungan penggred model, RL pada isyarat yang tidak boleh disahkan dan penapis input yang lebih ketat ialah langkah kejuruteraan pragmatik yang secara langsung meningkatkan pengalaman pengguna dalam tugas perbualan, empati dan kreatif di mana pesaing secara sejarah kurang berprestasi.
Jadi, walaupun "menghancurkan" ialah cara yang berwarna-warni untuk mengatakan "memimpin dalam pelbagai penilaian awam dan dalaman," metrik awam asas xAI menerbitkan kembali kesimpulan itu
Bagaimana untuk mengakses Grok 4.1
Akses pengguna / aplikasi
xAI secara berkala menjadikan Grok 4.1 boleh diakses dalam mod "Auto" secara percuma atau sebagai tetingkap promosi, tetapi peringkat premium (SuperGrok, SuperGrok Heavy) dan akses API dengan kuota yang lebih tinggi wujud dan kekal sebagai tawaran berbayar.
Grok 4.1 tersedia untuk semua pengguna on grok.com, X (dahulunya Twitter), dan apl iOS dan Android Grok, dilancarkan serta-merta dalam mod Auto sambil juga boleh dipilih secara eksplisit sebagai "Grok 4.1" dalam pemilih model.
Akses API & rancangan pembangun
Titik akhir Grok 4.1 tersedia melalui API xAI. Sehingga tarikh penerbitan artikel ini, API GPT 4.1 rasmi belum dikeluarkan.
CometAPI berjanji untuk menjejaki dinamik model terkini termasuk API Grok 4.1, yang akan dikeluarkan serentak dengan keluaran rasmi. Sila nantikannya dan teruskan memberi perhatian kepada CometAPI. Semasa menunggu, anda boleh memberi perhatian kepada model Grok yang lain seperti Grok-code-fast-1 and Grok 4, terokai keupayaan mereka di Taman Permainan dan rujuk panduan API untuk mendapatkan arahan terperinci untuk menghubungi . Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API.
Petua praktikal untuk menggunakan Grok 4.1 dalam pengeluaran
Bagaimana untuk mengurangkan risiko halusinasi
- Dayakan carian langsung atau rangkaian alat yang disahkan untuk pertanyaan mencari maklumat.
- Berikan langkah pengesahan: minta model mengembalikan sumber dan bukti untuk tuntutan fakta; menggunakan
responsemetadata untuk memeriksa petikan (jika ada). - Jalankan pemeriksaan deterministik (LLM semakan fakta, pengesah data berstruktur) sebagai langkah pasca pemprosesan untuk output berkepentingan tinggi.
Bagaimana untuk mengawal nada dan gaya
- Gunakan gesaan sistem yang jelas untuk membetulkan suara ("Anda formal dan empati.").
- Gunakan gesaan diselia dan templat tempatan kecil untuk suara yang konsisten merentas aplikasi.
- Jika ada, manfaatkan pilihan kawalan gaya xAI dan tombol stereng dipacu ganjaran .
Keputusan akhir: adakah Grok 4.1 perubahan laut?
Grok 4.1 ialah tidak seni bina serba baharu; sebaliknya, ia adalah sofistikated dan bertimbang rasa selepas latihan / penjajaran keluaran yang memfokuskan pada perkara yang sebenarnya diminati manusia dalam sembang: personaliti, kecerdasan emosi, kreativiti, dan lebih sedikit kesilapan fakta. Keuntungan yang boleh diukur pada papan pendahulu, keutamaan trafik sebenar berskala besar dan alatan keselamatan yang dipertingkatkan. Untuk aplikasi yang bergantung pada perbualan berkualiti tinggi, kerjasama kreatif atau bantuan sensitif nada, Grok 4.1 ialah langkah besar ke hadapan dan, dalam beberapa penanda aras komuniti, prestasi terbaik pada masa dikeluarkan.
CometAPI ialah platform pengagregatan API komersial yang memberikan pembangun bersatu, akses REST gaya OpenAI kepada ratusan model AI daripada berbilang vendor — LLM teks, penjana imej/video, benam dan banyak lagi — melalui antara muka tunggal yang konsisten. Daripada pendawaian SDK berasingan atau titik akhir yang dipesan lebih dahulu untuk OpenAI, Anthropic, Google, Meta atau pembekal model khusus yang lebih kecil, CometAPI membolehkan anda memanggil model yang berbeza dengan menukar rentetan model dan beberapa parameter.
Bersedia untuk mencuba?→ Daftar untuk CometAPI hari ini !
Jika anda ingin mengetahui lebih banyak petua, panduan dan berita tentang AI, ikuti kami VK, X and Perpecahan!