

xAI mengumumkan Grok 4 Cepat, varian kos yang dioptimumkan bagi keluarga Groknya yang menurut syarikat itu memberikan prestasi penanda aras yang hampir perdana sambil mengurangkan harga untuk mencapai prestasi itu dengan 98% berbanding dengan Grok 4. Model baharu ini direka bentuk untuk carian berkemampuan tinggi dan penggunaan alat agenik, serta termasuk tetingkap konteks 2 juta token dan varian "penaakulan" dan "tidak penaakulan" yang berasingan untuk membolehkan pembangun menyesuaikan pengiraan dengan keperluan mereka.
Ciri teras dan faedah
Model inferens kos efektif: Grok 4 Fast dibina daripada keluarga Grok 4 dengan tumpuan pada kecekapan token dan penggunaan alat masa nyata. xAI melaporkan bahawa model itu memerlukan secara kasar 40% lebih sedikit token "berfikir". secara purata. Analisis Buatan — yang menjejaki kependaman, kelajuan keluaran dan harga/prestasi merentas banyak model awam — meletakkan Grok 4 Fast tinggi pada kepintaran berbanding sempadan kos dan mengesahkan kelajuan keluaran pantas model dan nisbah kos yang menggalakkan dalam ujian awal.
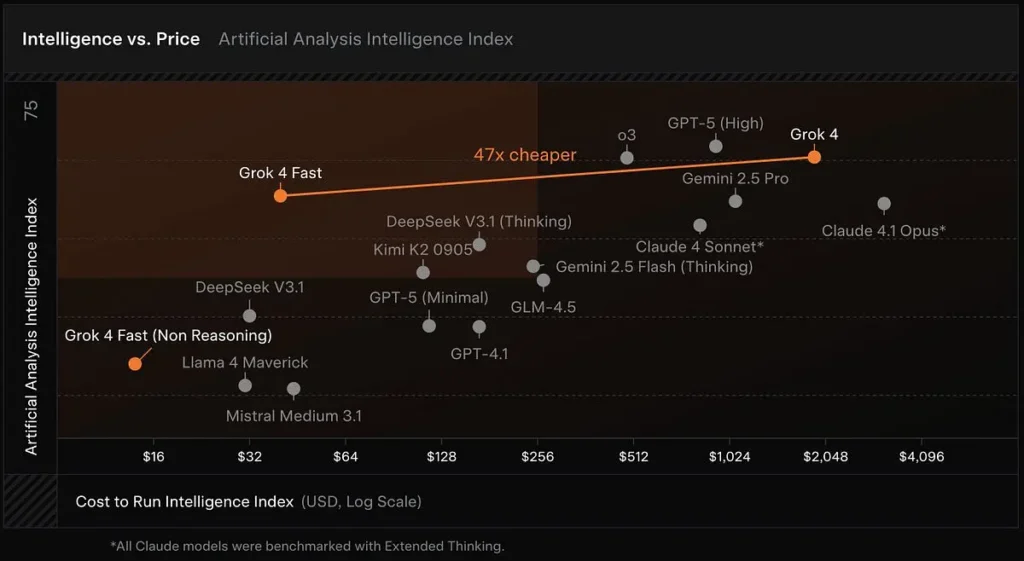
Tetingkap konteks besar: Grok 4 Fast direka bentuk untuk carian berkemampuan tinggi dan penggunaan alat agenik, dan termasuk tetingkap konteks 2 juta token dan varian "penaakulan" dan "bukan penaakulan" yang berasingan untuk membolehkan pembangun menyesuaikan pengiraan dengan keperluan mereka.
Keupayaan penggunaan alat asli: Grok 4 Fast menyediakan "keupayaan carian web dan X yang canggih" yang meningkatkan perolehan semula, navigasi dan sintesis kandungan web semasa aliran kerja agen — meletakkan Grok 4 Fast sebagai alat carian praktikal untuk aplikasi yang memerlukan pengumpulan maklumat dan penaakulan maklumat masa nyata merentas dokumen yang panjang, Prestasi terkemuka pada berbilang tanda aras carian, termasuk:
- BrowseComp (zh): 51.2% (vs. Grok 4's 45.0%)
- X Bench Deepsearch (zh): 74.0% (lwn. Grok 4's 66.0%)
Seni Bina Bersatu: Model yang sama menyokong kedua-dua mod inferens dan bukan inferens, menghapuskan keperluan untuk penukaran model yang berasingan. Kependaman dan kos yang dikurangkan menjadikannya sesuai untuk aplikasi masa nyata (seperti carian, menjawab soalan dan bantuan penyelidikan).
Perbandingan prestasi (penanda aras utama)
Dalam ujian LMArena persendirian yang dikongsi xAI, yang grok-4-fast-search (nama kod menlo) varian mendahului Arena Carian dengan penarafan Elo sebanyak 1,163, manakala varian teks (tahoe) berada dalam sepuluh teratas Arena Teks — keputusan yang digunakan xAI untuk menyokong tuntutannya mengenai prestasi carian.
Grok 4 Memadankan pantas atau mengekori rapat Grok 4 pada beberapa penanda aras sempadan (contohnya: GPQA Diamond, AIME 2025 dan HMMT 2025), sambil mengatasi prestasi model yang lebih kecil sebelumnya dalam tugas penaakulan — bukti yang digunakan xAI untuk mewajarkan tuntutan "prestasi setanding".
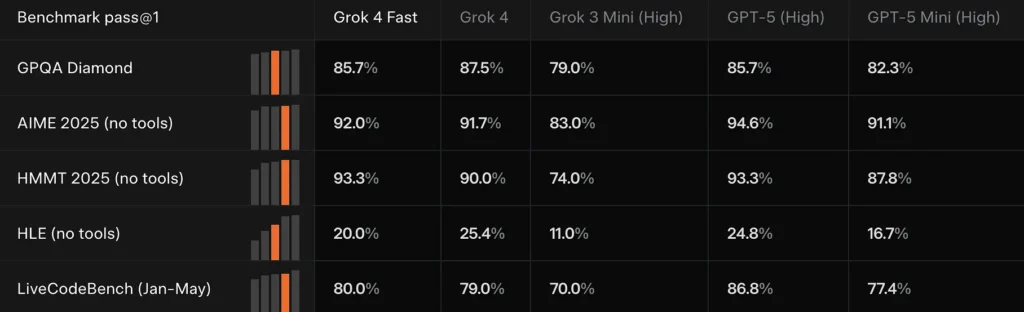
Bandingkan hasil
Berbanding dengan Grok 4: Lebih murah dan kurang intensif pengiraan, tetapi dengan prestasi yang serupa.
Berbanding dengan Grok 3 Mini: Lebih berkuasa, mampu membuat penaakulan yang kompleks dan carian masa nyata.
Berbanding dengan GPT-5/Gemini/Claude: Terima kasih kepada kecekapan token yang sangat tinggi dan keupayaan perkakasan, ia mendahului dalam keberkesanan kos dan beberapa tugas carian.
Harga & ketersediaan
Konteks & token: Dua perisa model: grok-4-fast-reasoning and grok-4-fast-non-reasoning, setiap satu dengan konteks 2M.
Menerbitkan (senarai) harga dalam siaran pelancaran (contoh peringkat):
- Token input: $0.20 / 1J (<128k) — $0.40 / 1J (≥128k)
- Token keluaran: $0.50 / 1J (<128k) — $1.00 / 1J (≥128k)
- Token input dicache: $0.05 / 1J.
(Lihat pengumuman xAI untuk peraturan pengebilan yang tepat dan sebarang promosi terhad masa.)
Ketersediaan pembekal: xAI menyenaraikan ketersediaan percuma jangka pendek melalui OpenRouter dan Vercel AI Gateway dan ketersediaan umum melalui API xAI.
Maksudnya untuk pengguna & pasukan
- Penjimatan kos yang besar untuk kegunaan pengeluaran — gabungan harga per-token yang lebih rendah dan token "berfikir" yang lebih sedikit bermakna pasukan boleh menjalankan lebih banyak pertanyaan atau aliran kerja konteks yang lebih besar pada sebahagian kecil daripada kos Grok 4, yang merendahkan secara material halangan untuk percubaan dan penggunaan berskala. (Tuntutan disokong oleh pendedahan kos/prestasi xAI dan analisis kos pihak ketiga.)
- Berfungsi dengan dokumen yang sangat panjang dan penaakulan pelbagai langkah — Token 2M menjadikannya praktikal untuk menelan keseluruhan buku, pangkalan kod yang besar, atau dokumen undang-undang/teknikal yang panjang dalam satu sesi, meningkatkan ketepatan dan keselarasan untuk tugasan yang memerlukan konteks jarak jauh (carian dokumen, ringkasan, penjanaan kod bentuk panjang, pembantu penyelidik).
- Output kependaman yang lebih cepat dan lebih rendah untuk aplikasi interaktif — sebagai varian “Pantas”, ia direka bentuk untuk pemprosesan token yang lebih pantas dan kependaman yang lebih rendah, yang memberi manfaat kepada UI sembang, pembantu pengekodan dan gelung ejen masa nyata di mana responsif penting. (Analisis Buatan dan tanda aras pembekal menekankan kelajuan output sebagai pembeza.)
- Harga/prestasi yang baik untuk tugas penaakulan yang ditanda aras — untuk pasukan yang menilai model mengikut penanda aras akademik sempadan, Grok 4 Fast menawarkan kompromi yang kuat: ketepatan berhampiran sempadan pada kos yang jauh lebih rendah, menjadikannya menarik untuk makmal penyelidikan dan syarikat yang kerap menjalankan suite penanda aras mahal.
Kesimpulan:
Grok 4 Fast meletakkan xAI untuk bersaing dalam harga-ke-prestasi dan untuk aplikasi ejen tertumpu carian. Jika kecekapan dan tuntutan pengesahan syarikat bertahan dalam ujian bebas khusus domain, Grok 4 Fast boleh membentuk semula jangkaan kos untuk penggunaan LLM berkeupayaan tinggi, alat yang didayakan — terutamanya untuk aplikasi yang bergantung pada pengambilan semula web secara langsung dan penggunaan alat berbilang langkah.
Bermula
CometAPI ialah platform API bersatu yang mengagregatkan lebih 500 model AI daripada pembekal terkemuka—seperti siri GPT OpenAI, Google Gemini, Anthropic's Claude, Midjourney, Suno dan banyak lagi—menjadi satu antara muka mesra pembangun. Dengan menawarkan pengesahan yang konsisten, pemformatan permintaan dan pengendalian respons, CometAPI secara dramatik memudahkan penyepaduan keupayaan AI ke dalam aplikasi anda. Sama ada anda sedang membina chatbots, penjana imej, komposer muzik atau saluran paip analitik terdorong data, CometAPI membolehkan anda mengulangi dengan lebih pantas, mengawal kos dan kekal sebagai vendor-agnostik—semuanya sambil memanfaatkan penemuan terkini merentas ekosistem AI.
Pembangun boleh mengakses Grok-4-cepat ( model: grok-4-fast-reasoning” / “grok-4-fast-reasoning) melalui CometAPI, versi model terkini sentiasa dikemas kini dengan laman web rasmi. Untuk memulakan, terokai keupayaan model dalam Taman Permainan dan berunding dengan Panduan API untuk arahan terperinci. Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda menyepadukan.
Bersedia untuk Pergi?→ Daftar untuk CometAPI hari ini !