

GLM-5 ialah model asas berwajaran terbuka baharu daripada Zhipu AI yang berpusatkan agen, dibina untuk pengekodan jangka panjang dan agen berbilang langkah. Ia tersedia melalui beberapa API dihoskan (termasuk CometAPI dan titik akhir penyedia) serta sebagai keluaran penyelidikan dengan kod dan wajaran; anda boleh mengintegrasikannya menggunakan panggilan REST serasi OpenAI standard, penstriman, dan SDK.
Apakah GLM-5 daripada Z.ai?
GLM-5 ialah model asas perdana generasi kelima Z.ai yang direka untuk kejuruteraan beragen: perancangan jangka panjang, penggunaan alat berbilang langkah, dan reka bentuk kod/sistem berskala besar. Dikeluarkan secara umum pada Februari 2026, GLM-5 ialah model Mixture-of-Experts (MoE) dengan ~744 bilion jumlah parameter dan set parameter aktif dalam julat 40B bagi setiap laluan ke hadapan; seni bina dan pilihan latihan mengutamakan koheren konteks panjang, panggilan alat, dan inferens menjimatkan kos untuk beban kerja produksi. Pilihan reka bentuk ini membolehkan GLM-5 menjalankan aliran kerja agen yang diperluas (contohnya: semak imbas → rancang → tulis/ujian kod → ulang) sambil mengekalkan konteks merentas input yang sangat panjang.
Sorotan teknikal utama :
- Seni bina MoE pada ~744B jumlah / ~40B parameter aktif; pra-latihan berskala (~28.5T token dilaporkan) untuk merapatkan jurang dengan model tertutup terdepan.
- Sokongan konteks panjang dan pengoptimuman (deep sparse attention, DSA) untuk mengurangkan kos pelaksanaan berbanding penskalaan padat naif.
- Ciri beragen terbina: panggilan alat/fungsi, sokongan sesi berkeadaan, dan output bersepadu (mampu menghasilkan artifak
.docx,.xlsx,.pdfsebagai sebahagian daripada aliran kerja agen dalam UI vendor). - Ketersediaan berwajaran terbuka (wajaran diterbitkan ke hub model) dan pilihan akses dihoskan (API vendor, mikroservis inferens).
Apakah kelebihan utama GLM-5?
Perancangan beragen dan memori jangka panjang
Seni bina dan penalaan GLM-5 mengutamakan penaakulan berbilang langkah yang konsisten dan memori merentas aliran kerja — bermanfaat untuk:
- agen autonomi (saluran CI, orkestrator tugas),
- penjanaan kod berbilang fail berskala besar atau pengubahsuai semula (refactor), dan
- kecerdasan dokumen yang perlu menyimpan sejarah yang besar.
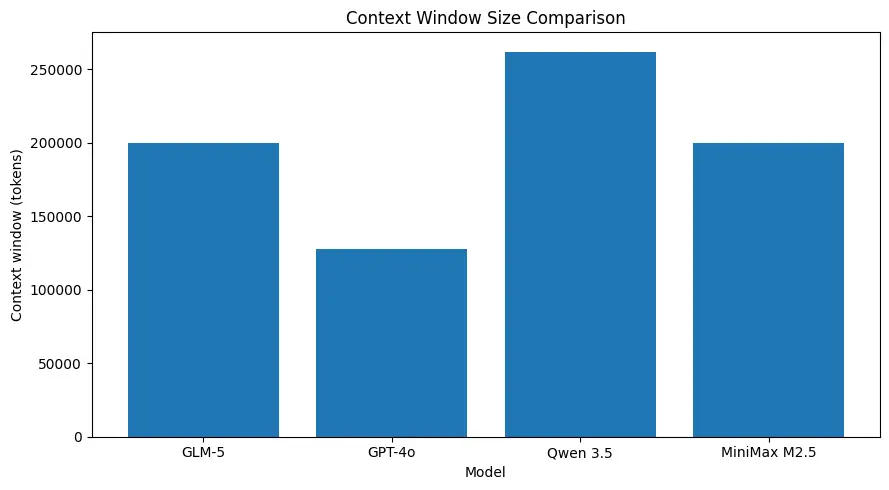
Tetingkap konteks yang besar
GLM-5 menyokong saiz konteks yang sangat besar (sekitar ~200k token dalam spesifikasi model yang diterbitkan), membolehkan anda mengekalkan lebih banyak sesi dalam satu permintaan dan mengurangkan keperluan pemecahan agresif atau memori luaran untuk banyak kegunaan. (Lihat carta perbandingan di bawah.)
Prestasi pengekodan yang kukuh untuk tugas peringkat sistem
GLM-5 melaporkan prestasi sumber terbuka teratas pada penanda aras kejuruteraan perisian (SWE-bench dan suite kod + agen terapan). Pada SWE-bench-Verified ia melaporkan ~77.8%; pada ujian agen gaya pengekodan/terminal (Terminal-Bench 2.0) skor berkumpul di pertengahan 50-an — bukti keupayaan pengekodan praktikal yang menghampiri model proprietari terdepan. Metrik ini bermakna GLM-5 sesuai untuk tugas seperti penjanaan kod, pembaikan semula automatik, penaakulan berbilang fail, dan senario pembantu CI/CD.
Pertukaran kos/kecekapan
Kerana GLM-5 menggunakan MoE dan inovasi perhatian “sparse”, ia bertujuan mengurangkan kos inferens bagi setiap unit keupayaan berbanding penskalaan padat secara brute-force. CometAPI menyediakan titik harga kompetitif yang menjadikan GLM-5 menarik untuk beban kerja beragen berkapasiti tinggi.
Bagaimana cara menggunakan API GLM-5 melalui CometAPI?
Jawapan ringkas: layan CometAPI seperti gerbang serasi OpenAI — tetapkan URL asas dan kunci API anda, pilih glm-5 sebagai model, kemudian panggil titik akhir chat/completions. CometAPI menyediakan permukaan REST gaya OpenAI (titik akhir seperti /v1/chat/completions) serta SDK dan projek sampel yang menjadikan migrasi sangat mudah.
Di bawah ialah panduan praktikal berorientasikan produksi: pengesahan, panggilan chat asas, penstriman, panggilan fungsi/alat, dan pengendalian kos/respons.
Langkah asas untuk mengakses GLM-5 melalui CometAPI ialah:
- Daftar di CometAPI, dapatkan kunci API.
- Cari id model tepat untuk GLM-5 dalam katalog CometAPI (
"glm-5"bergantung pada senarai). - Hantar permintaan POST diautentikasi ke titik akhir chat/completions CometAPI (gaya OpenAI).
Butiran asas (pola CometAPI): platform menyokong laluan gaya OpenAI seperti https://api.cometapi.com/v1/chat/completions, autentikasi Bearer, parameter model, mesej sistem/pengguna, penstriman, dan contoh curl/python dalam dokumentasi.
Contoh: penyempurnaan chat Python (requests) pantas dengan GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Contoh: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Respons penstriman (pola praktikal)
CometAPI menyokong penstriman gaya OpenAI (SSE / berketul). Pendekatan paling ringkas dalam Python ialah meminta "stream": true dan mengiterasi data respons semasa ia tiba. Ini penting apabila anda memerlukan output separa berlatensi rendah (bina pembantu dev masa nyata, UI penstriman).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Rujukan: penstriman gaya OpenAI dan dokumentasi keserasian CometAPI.
Panggilan fungsi / alat (cara memanggil alat luaran)
GLM-5 menyokong pola panggilan fungsi atau alat yang serasi dengan konvensyen OpenAI / pengagregat (gerbang menghantar panggilan fungsi berstruktur dalam respons model). Contoh kegunaan: minta GLM-5 memanggil alat tempatan “run_tests”; model mengembalikan arahan berstruktur yang boleh anda huraikan dan laksanakan.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Apabila model mengembalikan payload function_call, jalankan alat di sisi pelayan, kemudian suapkan hasil alat kembali sebagai mesej dengan peranan "tool" dan sambung semula perbualan. Pola ini membolehkan panggilan alat yang selamat dan aliran agen berkeadaan. Lihat dokumentasi dan contoh CometAPI untuk pembantu SDK yang konkrit.
Parameter praktikal & talaan
function_call: gunakan untuk mendayakan panggilan alat berstruktur dan aliran pelaksanaan yang lebih selamat.
temperature: 0–0.3 untuk keluaran deterministik peringkat sistem (kod, infra), lebih tinggi untuk ideasi.
max_tokens: tetapkan mengikut panjang output yang dijangka; GLM-5 menyokong output yang sangat panjang apabila dihoskan (had vendor berbeza).
top_p / nucleus sampling: berguna untuk mengehadkan ekor yang tidak mungkin.
stream: true untuk UI interaktif.
Perbandingan GLM-5 dengan Claude Opus oleh Anthropic dan model terdepan lain
Jawapan ringkas: GLM-5 menutup jurang dengan model tertutup terdepan dalam penanda aras beragen dan pengekodan sambil menawarkan pelaksanaan berwajaran terbuka dan sering kos per token lebih baik apabila dihoskan oleh pengagregat. Nuansanya: pada sesetengah penanda aras pengekodan mutlak (SWE-bench, variasi Terminal-Bench) Claude Opus (4.5/4.6) oleh Anthropic masih mendahului beberapa mata dalam banyak papan kedudukan yang diterbitkan — tetapi GLM-5 sangat berdaya saing dan mengatasi banyak model terbuka lain.
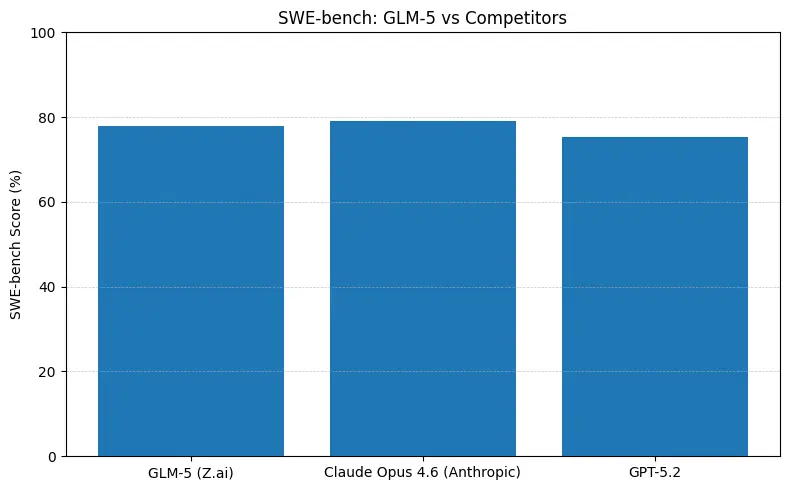
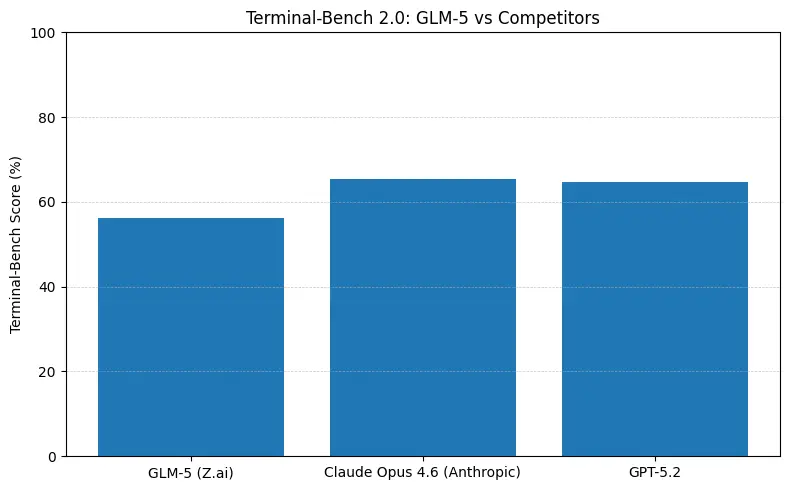
Makna nombor dalam praktik
- SWE-bench (~ketepatan kod / kejuruteraan): Claude Opus menunjukkan kelebihan kecil (≈79% vs GLM-5 ≈77.8%) pada papan kedudukan yang diterbitkan; untuk banyak tugas sebenar jurang itu akan diterjemah kepada lebih sedikit suntingan manual, tetapi tidak semestinya kepada pilihan seni bina yang berbeza untuk prototaip atau aliran kerja beragen berskala.
- Terminal-Bench (tugas beragen baris perintah): Opus 4.6 mendahului (≈65.4% vs GLM-5 ≈56.2%) — jika anda memerlukan automasi terminal yang teguh dan kebolehpercayaan tertinggi pada operasi shell di luar taburan, Opus selalunya lebih baik pada margin.
- Beragen dan jangka panjang: GLM-5 menunjukkan prestasi sangat baik pada simulasi perniagaan jangka panjang (Vending-Bench 2 baki $4,432 dilaporkan) dan mempamerkan koheren perancangan untuk aliran kerja berbilang langkah. Jika produk anda ialah agen jangka panjang (kewangan, operasi), GLM-5 adalah kuat.
Bagaimana mereka bentuk prompt dan sistem untuk mendapatkan keluaran GLM-5 yang boleh dipercayai?
Mesej sistem & kekangan jelas
Berikan GLM-5 peranan dan kekangan yang ketat, khususnya untuk tugas kod atau panggilan alat. Contoh:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Minta ujian dan penaakulan ringkas untuk setiap perubahan yang tidak remeh.
Uraikan tugas kompleks
Daripada “tulis keseluruhan produk,” minta:
- rangka reka bentuk,
- tandatangan antara muka,
- pelaksanaan dan ujian,
- skrip integrasi akhir.
Penguraian berperingkat ini mengurangkan halusinasi dan memberikan titik semak deterministik yang boleh anda sahkan.
Gunakan suhu rendah untuk kod deterministik
Apabila meminta kod, tetapkan temperature = 0–0.2 dan max_tokens kepada had selamat. Untuk penulisan kreatif atau sumbang saran reka bentuk, naikkan suhu.
Amalan terbaik ketika mengintegrasikan GLM-5 (melalui CometAPI atau hos langsung)
Kejuruteraan prompt & prompt sistem
- Gunakan arahan sistem yang jelas yang mentakrifkan peranan agen, dasar akses alat, dan kekangan keselamatan. Contoh: “Anda ialah arkitek sistem: hanya cadangkan perubahan apabila ujian unit lulus secara lokal; senaraikan arahan CLI tepat untuk dijalankan.”
- Untuk tugas pengekodan, sediakan konteks repositori (senarai fail, petikan kod utama) dan lampirkan output ujian unit jika ada. Pengendalian konteks panjang GLM-5 membantu — tetapi sentiasa letakkan konteks penting dahulu (peranan, tugas) diikuti artifak sokongan.
Pengurusan sesi & keadaan
- Gunakan id sesi untuk perbualan agen panjang dan kekalkan “memori” langkah terdahulu yang diringkas (ringkasan) bagi mengelak pembengkakan konteks. CometAPI dan gerbang serupa menyediakan pembantu sesi/keadaan — tetapi pemadatan keadaan pada aras aplikasi adalah penting untuk agen jangka panjang.
- Sentiasa log panggilan alat dan respons model untuk keterkesanan dan penyahpepijat pasca insiden.
Peralatan & panggilan fungsi (keselamatan + kebolehpercayaan)
- Dedahkan set alat yang sempit dan boleh diaudit. Jangan benarkan pelaksanaan shell sewenang-wenangnya tanpa pengawasan manusia. Gunakan definisi fungsi berstruktur dan sahkan argumen di sisi pelayan.
- Sentiasa pantau panggilan alat dan respons model untuk kebolehjejak dan penyahpepijat.
Kawalan kos & pembundelan
- Untuk agen jumlah tinggi, lalukan pemprosesan latar kepada varian model yang lebih murah apabila kompromi kualiti boleh diterima (CometAPI membolehkan anda menukar model mengikut nama). Bundel permintaan serupa dan kurangkan
max_tokensjika boleh. Pantau nisbah token input vs output — token output selalunya lebih mahal.
Kejuruteraan kependaman & kadar laluan
- Gunakan penstriman untuk sesi interaktif. Untuk kerja agen latar, utamakan persekitaran async, baris gilir pekerja, dan penghad laju. Jika anda menghos sendiri (berwajaran terbuka), tala topologi pemecut anda kepada seni bina MoE — pilihan FPGA / Ascend / silikon khusus boleh memberikan kelebihan kos.
Nota penutup
GLM-5 mewakili langkah praktikal berwajaran terbuka ke arah kejuruteraan beragen: tetingkap konteks besar, keupayaan perancangan, dan prestasi kod yang kukuh menjadikannya menarik untuk alat pembangun, orkestrasi agen, dan automasi peringkat sistem. Gunakan CometAPI untuk integrasi pantas atau taman model awan untuk hos terurus; sentiasa sahkan pada beban kerja anda dan instrumentasikan dengan teliti untuk kawalan kos dan halusinasi.
Pembangun boleh mengakses GLM-5 melalui CometAPI sekarang. Untuk bermula, terokai keupayaan model dalam Playground dan rujuk panduan API untuk arahan terperinci. Sebelum mengakses, pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga jauh lebih rendah daripada harga rasmi untuk membantu anda berintegrasi.
Sedia untuk bermula?→ Daftar M2.5 hari ini !
Jika anda ingin mengetahui lebih banyak tip, panduan dan berita mengenai AI ikuti kami di VK, X dan Discord!