

Bermula dengan Gemini 2.5 Flash-Lite melalui CometAPI ialah peluang menarik untuk memanfaatkan salah satu model AI generatif kependaman rendah yang paling cekap kos yang tersedia hari ini. Panduan ini menggabungkan pengumuman terkini daripada Google DeepMind, spesifikasi terperinci daripada dokumentasi Vertex AI, dan langkah penyepaduan praktikal menggunakan CometAPI untuk membantu anda bangun dan berjalan dengan cepat dan berkesan.
Apakah Gemini 2.5 Flash-Lite dan mengapa anda perlu mempertimbangkannya?
Gambaran keseluruhan keluarga Gemini 2.5
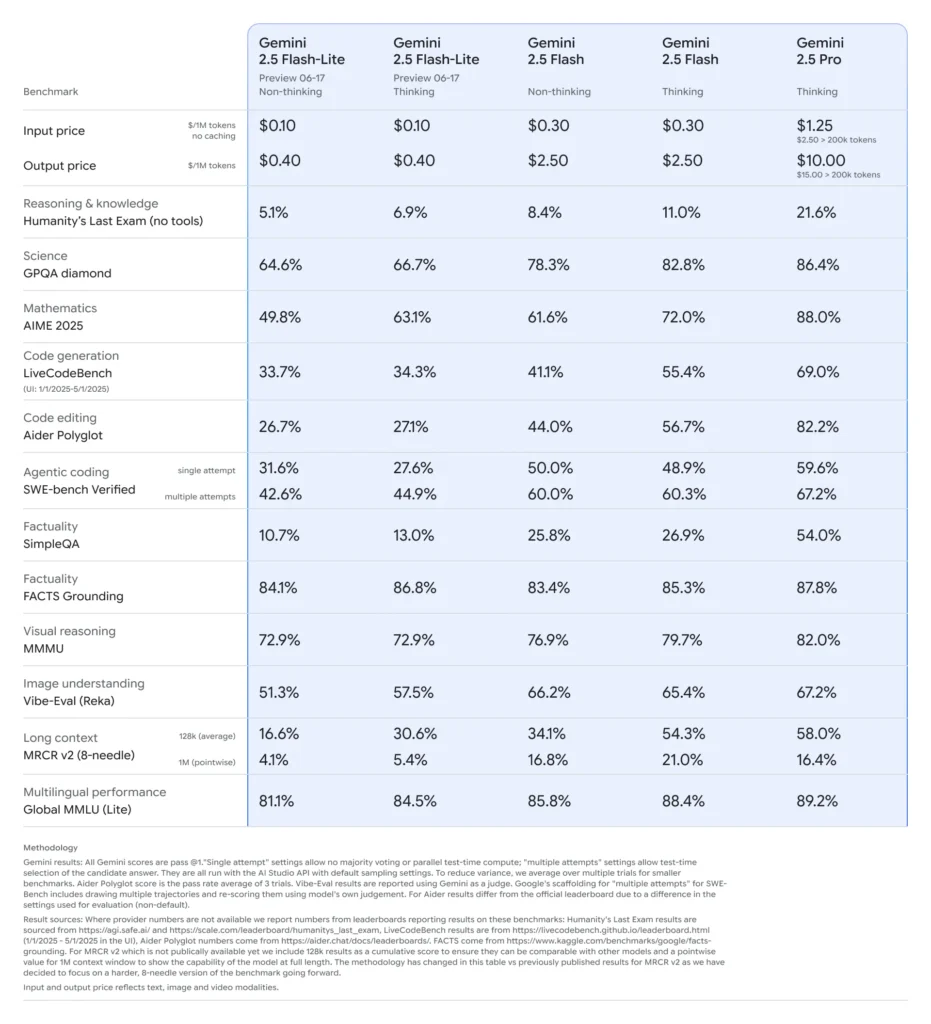
Pada pertengahan Jun 2025, Google DeepMind secara rasmi mengeluarkan siri Gemini 2.5, termasuk versi GA stabil Gemini 2.5 Pro dan Gemini 2.5 Flash, di samping pratonton model serba baharu dan ringan: Gemini 2.5 Flash-Lite. Direka bentuk untuk mengimbangi kelajuan, kos dan prestasi, siri 2.5 mewakili dorongan Google untuk memenuhi spektrum kes penggunaan yang luas—daripada beban kerja penyelidikan tugas berat kepada penggunaan skala besar yang sensitif kos .
Ciri utama Flash-Lite
Flash-Lite membezakan dirinya dengan menawarkan keupayaan berbilang modal (teks, imej, audio, video) pada kependaman yang sangat rendah, dengan tetingkap konteks menyokong sehingga satu juta token dan penyepaduan alat termasuk Carian Google, pelaksanaan kod dan panggilan fungsi . Secara kritis, Flash-Lite memperkenalkan kawalan "belanjawan pemikiran", membenarkan pembangun menukar kedalaman penaakulan terhadap masa dan kos respons dengan melaraskan parameter belanjawan token dalaman .
Kedudukan dalam barisan model
Jika dibandingkan dengan adik-beradiknya, Flash-Lite berada di sempadan Pareto dalam kecekapan kos: berharga kira-kira $0.10 setiap juta token input dan $0.40 setiap juta token keluaran semasa pratonton, ia mengurangkan kedua-dua Flash (pada $0.30/$2.50) dan Pro (pada $1.25/$10) sambil mengekalkan kebanyakan fungsi sokongan dan mod-modal mereka. Ini menjadikan Flash-Lite sesuai untuk tugasan volum tinggi, kerumitan rendah seperti ringkasan, klasifikasi dan ejen perbualan ringan.
Mengapakah pembangun harus mempertimbangkan Gemini 2.5 Flash-Lite?
Penanda aras prestasi dan ujian dunia sebenar
Dalam perbandingan head-to-head, Flash-Lite menunjukkan:
- 2× daya pemprosesan lebih pantas daripada Gemini 2.5 Flash pada tugas pengelasan.
- 3× penjimatan kos untuk saluran paip ringkasan pada skala perusahaan.
- Ketepatan kompetitif pada logik, matematik dan penanda aras kod, memadankan atau melebihi pratonton Flash-Lite yang lebih awal.
Kes penggunaan yang ideal
- Chatbots volum tinggi: Menyampaikan pengalaman perbualan yang konsisten dan kependaman rendah merentas berjuta-juta pengguna.
- Penjanaan kandungan automatik: Skala ringkasan dokumen, terjemahan dan penciptaan salinan mikro.
- Saluran paip carian-dan-pengesyoran: Manfaatkan inferens pantas untuk pemperibadian masa nyata.
- Pemprosesan data kelompok: Anotasi set data yang besar dengan kos pengiraan yang minimum.
Bagaimanakah anda mendapatkan dan mengurus akses API untuk Gemini 2.5 Flash-Lite melalui CometAPI?
Mengapa menggunakan CometAPI sebagai pintu masuk anda?
CometAPI mengagregatkan lebih 500 model AI—termasuk siri Gemini Google—di bawah titik akhir REST bersatu, memudahkan pengesahan, pengehadan kadar dan pengebilan merentas penyedia . Daripada menyulap berbilang URL asas dan kunci API, anda menunjukkan semua permintaan https://api.cometapi.com/v1, nyatakan model sasaran dalam muatan dan uruskan penggunaan melalui satu papan pemuka.
Prasyarat dan pendaftaran
- Log masuk ke cometapi.com. Jika anda belum menjadi pengguna kami, sila daftar dahulu
- Dapatkan kunci API kelayakan akses antara muka. Klik "Tambah Token" pada token API di pusat peribadi, dapatkan kunci token: sk-xxxxx dan serahkan.
- Dapatkan url tapak ini: https://api.cometapi.com/
Menguruskan token dan kuota anda
Papan pemuka CometAPI menyediakan kuota token bersatu yang boleh dikongsi merentas Google, OpenAI, Anthropic dan model lain. Gunakan alat pemantauan terbina dalam untuk menetapkan makluman penggunaan dan had kadar supaya anda tidak melebihi peruntukan belanjawan atau dikenakan caj yang tidak dijangka.
Bagaimanakah anda mengkonfigurasi persekitaran pembangunan anda untuk penyepaduan CometAPI?
Memasang kebergantungan yang diperlukan
Untuk integrasi Python, pasang pakej berikut:
pip install openai requests pillow
- openai: SDK yang serasi untuk berkomunikasi dengan CometAPI.
- permintaan: Untuk operasi HTTP seperti memuat turun imej.
- bantal: Untuk pengendalian imej semasa menghantar input berbilang modal.
Memulakan klien CometAPI
Gunakan pembolehubah persekitaran untuk memastikan kunci API anda daripada kod sumber:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Contoh klien ini kini boleh menyasarkan mana-mana model yang disokong dengan menyatakan IDnya (cth, gemini-2.5-flash-lite-preview-06-17) dalam permintaan anda .
Mengkonfigurasi belanjawan pemikiran dan parameter lain
Apabila anda menghantar permintaan, anda boleh memasukkan parameter pilihan:
- suhu/top_p: Kawal rawak dalam penjanaan.
- candidateCount: Bilangan keluaran alternatif.
- max_token: Had token output.
- bajet_fikiran: Parameter tersuai untuk Flash-Lite untuk menukar kedalaman dengan kelajuan dan kos.
Apakah rupa permintaan asas kepada Gemini 2.5 Flash-Lite melalui CometAPI?
Contoh teks sahaja
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Panggilan ini mengembalikan ringkasan ringkas dalam masa kurang daripada 200 ms, sesuai untuk chatbots atau saluran paip analitik masa nyata .
Contoh input berbilang modal
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite memproses sehingga 7 MB imej dan mengembalikan perihalan kontekstual, menjadikannya sesuai untuk pemahaman dokumen, analisis UI dan pelaporan automatik .
Bagaimanakah anda boleh memanfaatkan ciri lanjutan seperti penstriman dan panggilan fungsi?
Menstrim respons untuk aplikasi masa nyata
Untuk antara muka chatbot atau kapsyen langsung, gunakan API penstriman:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Ini memberikan output separa apabila ia tersedia, mengurangkan kependaman yang dirasakan dalam UI interaktif.
Fungsi memanggil output data berstruktur
Tentukan skema JSON untuk menguatkuasakan respons berstruktur:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Pendekatan ini menjamin output yang mematuhi JSON, memudahkan saluran paip dan penyepaduan data hiliran .
Bagaimanakah anda mengoptimumkan prestasi, kos dan kebolehpercayaan apabila menggunakan Gemini 2.5 Flash-Lite?
Penalaan bajet terfikir
Parameter belanjawan pemikiran Flash-Lite membolehkan anda mendail jumlah "usaha kognitif" yang dibelanjakan oleh model. Belanjawan yang rendah (cth, 0) mengutamakan kelajuan dan kos, manakala nilai yang lebih tinggi menghasilkan penaakulan yang lebih mendalam dengan mengorbankan kependaman dan token .
Menguruskan had token dan troughput
- Token input: Sehingga 1,048,576 token setiap permintaan.
- Token keluaran: Had lalai sebanyak 65,536 token.
- Input multimodal: Sehingga 500 MB merentas imej, audio dan aset video .
Laksanakan batching sebelah pelanggan untuk beban kerja volum tinggi dan manfaatkan penskalaan automatik CometAPI untuk mengendalikan trafik pecah tanpa campur tangan manual .
Strategi kecekapan kos
- Kumpulkan tugas kerumitan rendah pada Flash-Lite sambil menempah Pro atau Flash standard untuk kerja tugas berat.
- Gunakan had kadar dan makluman belanjawan dalam papan pemuka CometAPI untuk mengelakkan perbelanjaan lari.
- Pantau penggunaan mengikut ID model untuk membandingkan kos setiap permintaan dan melaraskan logik penghalaan anda dengan sewajarnya.
Apakah amalan terbaik dan langkah seterusnya selepas penyepaduan awal?
Pemantauan, pembalakan dan keselamatan
- Pembalakan: Tangkap metadata permintaan/tindak balas (cap masa, latensi, penggunaan token) untuk audit prestasi.
- Alerts: Sediakan pemberitahuan ambang untuk kadar ralat atau lebihan kos dalam CometAPI.
- Keselamatan: Putar kunci API dengan kerap dan simpannya dalam peti besi selamat atau pembolehubah persekitaran.
Corak penggunaan biasa
- Chatbots: Gunakan Flash-Lite untuk pertanyaan pengguna pantas dan kembali kepada Pro untuk tindakan susulan yang kompleks.
- Pemprosesan dokumen: Analisis PDF atau imej kumpulan semalaman pada tetapan belanjawan yang lebih rendah.
- Analisis masa nyata: Strim data kewangan atau operasi untuk cerapan segera melalui API penstriman.
Meneroka lebih jauh
- Eksperimen dengan dorongan hibrid: gabungkan input teks dan imej untuk konteks yang lebih kaya.
- Prototaip RAG (Retrieval-Augmented Generation) dengan menyepadukan alat carian vektor dengan Gemini 2.5 Flash-Lite.
- Penanda aras terhadap tawaran pesaing (cth, GPT-4.1, Claude Sonnet 4) untuk mengesahkan pertukaran kos dan prestasi .
Penskalaan dalam pengeluaran
- Manfaatkan peringkat perusahaan CometAPI untuk kumpulan kuota khusus dan jaminan SLA.
- Laksanakan strategi penggunaan biru-hijau untuk menguji gesaan atau belanjawan baharu tanpa mengganggu pengguna langsung.
- Semak metrik penggunaan model secara kerap untuk mengenal pasti peluang untuk penjimatan kos atau peningkatan kualiti selanjutnya.
Bermula
CometAPI menyediakan antara muka REST bersatu yang mengagregatkan ratusan model AI—di bawah titik akhir yang konsisten, dengan pengurusan kunci API terbina dalam, kuota penggunaan dan papan pemuka pengebilan. Daripada menyesuaikan berbilang URL vendor dan bukti kelayakan.
Pembangun boleh mengakses API Gemini 2.5 Flash-Lite (pratonton).(Model: gemini-2.5-flash-lite-preview-06-17) Melalui CometAPI, model terkini yang disenaraikan adalah pada tarikh penerbitan artikel. Untuk memulakan, terokai keupayaan model dalam Taman Permainan dan berunding dengan Panduan API untuk arahan terperinci. Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda menyepadukan.
Hanya dalam beberapa langkah, anda boleh menyepadukan Gemini 2.5 Flash-Lite melalui CometAPI ke dalam aplikasi anda, membuka kunci gabungan kepantasan, keterjangkauan dan kecerdasan pelbagai mod yang berkuasa. Dengan mengikut garis panduan di atas—merangkumi persediaan, permintaan asas, ciri lanjutan dan pengoptimuman—anda akan berada pada kedudukan yang baik untuk menyampaikan pengalaman AI generasi seterusnya kepada pengguna anda. Masa depan AI yang cekap kos dan berkeupayaan tinggi ada di sini: mulakan dengan Gemini 2.5 Flash-Lite hari ini.