

Kling O1 — dikeluarkan sebagai sebahagian daripada minggu pelancaran “Omni” Kling AI — meletakkan dirinya sebagai model asas video multimodal tunggal yang menerima teks, imej dan video dalam permintaan yang sama serta boleh menjana dan mengedit video dalam aliran kerja berulang peringkat pengarah. Pasukan Kling menamakan O1 sebagai "model berskala besar video multimodal bersatu pertama di dunia." Ujian dalaman Kling mendakwa kemenangan yang besar berbanding Google Veo 3.1 dan Runway Aleph.
Apakah Kling O1?
Kling O1 (sering dipasarkan sebagai Video O1 or Omni One) ialah model asas video yang baru dikeluarkan daripada Kling AI yang menyatukan penjanaan dan penyuntingan merentas teks, imej dan video dalam satu rangka kerja terdorong segera. Daripada menganggap teks-ke-video, imej-ke-video dan pengeditan video sebagai saluran paip yang berasingan, Kling O1 menerima input bercampur (teks + berbilang imej + video rujukan pilihan) dalam satu gesaan, alasan atasnya dan menghasilkan klip pendek yang koheren atau mengedit rakaman sedia ada dengan kawalan terperinci. Syarikat itu meletakkan pelancaran sebagai sebahagian daripada "Pelancaran Omni" dan menerangkan O1 sebagai "enjin video pelbagai mod" yang dibina berdasarkan paradigma Multimodal Visual Language (MVL) dan laluan penaakulan Chain-of-Thought (CoT) untuk mentafsir arahan kreatif yang kompleks dan berbilang bahagian.
Pemesejan Kling menekankan tiga aliran kerja praktikal: (1) teks → penjanaan video, (2) imej/elemen → video (penggubahan dan pertukaran subjek/prop menggunakan rujukan eksplisit), dan (3) penyuntingan video/penerusan tangkapan (penggayaan semula, tambah/buang objek, kawalan bingkai mula/bingkai akhir). Model ini menyokong gesaan berbilang elemen (termasuk sintaks "@" untuk menyasarkan imej rujukan tertentu) dan menampilkan kawalan gaya pengarah seperti penambat bingkai mula/akhir dan penerusan video untuk membina jujukan berbilang tangkapan.
5 sorotan teras Kling O1
1) Input multimodal bersatu benar (MVL)
Keupayaan utama Kling O1 menganggap teks, imej pegun (berbilang rujukan) dan video sebagai input serentak kelas pertama. Pengguna boleh membekalkan beberapa imej rujukan (atau klip rujukan pendek) and arahan bahasa semula jadi; model akan menghuraikan semua input bersama-sama untuk menghasilkan atau mengedit output yang koheren. Ini mengurangkan geseran rantai alat dan membolehkan aliran kerja seperti "menggunakan subjek daripada @image1, letakkan mereka dalam persekitaran dari @image2, padankan usul ke ref_video.mp4, dan gunakan warna sinematik gred X.” Pembingkaian “Multimodal Visual Language” (MVL) ini adalah teras kepada nada Kling.
Mengapa ia perkara: aliran kerja kreatif sebenar selalunya memerlukan rujukan gabungan: watak daripada satu aset, pergerakan kamera daripada yang lain dan arahan naratif dalam teks. Penyatuan input ini membolehkan penjanaan satu laluan dan langkah pengkomputeran manual yang lebih sedikit.
2) Mengedit + penjanaan dalam satu model (mod berbilang elemen)
Kebanyakan sistem terdahulu mengasingkan penjanaan (teks→video) daripada penyuntingan tepat bingkai. O1 dengan sengaja menggabungkannya: model yang sama yang mencipta klip dari awal juga boleh mengedit rakaman sedia ada — menukar objek, menggayakan semula pakaian, menanggalkan prop atau memanjangkan syot — semuanya melalui arahan bahasa semula jadi. Penumpuan itu ialah penyederhana aliran kerja utama untuk pasukan pengeluaran.
Model O1 mencapai penyepaduan mendalam bagi pelbagai tugasan video pada terasnya:
- Penjanaan teks-ke-Video
- Penjanaan rujukan imej/Subjek
- Suntingan & lukisan video
- Gaya semula video
- Generasi Shot Seterusnya/Sebelumnya
- Penjanaan Video Terkekang Kerangka Kunci
Kepentingan terbesar reka bentuk ini terletak pada: Proses kompleks yang sebelum ini memerlukan berbilang model atau alatan bebas kini boleh disiapkan dalam satu enjin. Ini bukan sahaja mengurangkan kos penciptaan dan pengiraan dengan ketara tetapi juga meletakkan asas untuk pembangunan "model pemahaman dan penjanaan video bersatu."
3) Kesepaduan penjanaan video
Ketekalan identiti: Model O1 meningkatkan keupayaan pemodelan ketekalan rentas mod, mengekalkan kestabilan struktur, bahan, pencahayaan dan gaya subjek rujukan semasa proses penjanaan:
- Ia menyokong imej rujukan berbilang paparan untuk pemodelan subjek;
- ia menyokong ketekalan subjek syot silang (ciri watak, objek dan pemandangan kekal berterusan merentasi syot berbeza);
- ia menyokong rujukan hibrid berbilang subjek, membolehkan penjanaan potret kumpulan dan pembinaan pemandangan interaktif.
Mekanisme ini meningkatkan dengan ketara keselarasan dan "ketekalan identiti" penjanaan video, menjadikannya sesuai untuk senario dengan keperluan ketekalan yang sangat tinggi, seperti pengiklanan dan penjanaan syot peringkat filem.
Peningkatan ingatan: Model O1 juga mempunyai "memori", menghalang gaya keluarannya daripada menjadi tidak stabil disebabkan oleh konteks yang panjang atau arahan yang berubah. Ia juga boleh:
- ingat berbilang aksara serentak;
- membenarkan watak yang berbeza untuk berinteraksi dalam video;
- mengekalkan konsistensi dalam gaya, pakaian, dan postur.
4) Penggubahan tepat dengan sintaks "@" dan kawalan bingkai mula/akhir
Kling memperkenalkan trengkas penggubahan (dilaporkan sebagai sistem sebutan "@") supaya anda boleh merujuk imej tertentu dalam gesaan (cth, @image1, @image2) untuk memberikan peranan kepada aset dengan pasti. Digabungkan dengan spesifikasi bingkai Mula + Tamat yang eksplisit, ini membolehkan kawalan peringkat pengarah ke atas cara elemen beralih, bergerak atau berubah merentasi klip yang dijana — set ciri tertumpu pengeluaran yang membezakan O1 daripada banyak penjana berorientasikan pengguna.
5) Kesetiaan tinggi, keluaran panjang dan susun berbilang tugas
Kling O1 dilaporkan menghasilkan output sinematik 1080p (30fps) dan — dengan versi Kling terdahulu menetapkan pentas — syarikat menggembar-gemburkan penjanaan klip yang lebih panjang (melaporkan sehingga 2 minit dalam penulisan produk baru-baru ini). Ia juga menyokong menyusun berbilang tugas kreatif dalam satu permintaan (jana, tambah subjek, tukar pencahayaan dan edit gubahan). Sifat tersebut menjadikannya berdaya saing dengan teks → enjin video peringkat lebih tinggi.
Mengapa ia perkara: klip yang lebih panjang, ketepatan tinggi dan keupayaan untuk menggabungkan suntingan mengurangkan keperluan untuk mencantum banyak klip pendek bersama-sama dan memudahkan pengeluaran hujung ke hujung.
Bagaimanakah arkitek Kling O1 dan apakah mekanisme asasnya?
O1 sekitar a Bahasa Visual Multimodal (MVL) teras: model yang mempelajari benam bersama untuk bahasa + imej + isyarat gerakan (bingkai video dan ciri gaya aliran optik), dan kemudian menggunakan resapan atau penyahkod berasaskan pengubah untuk mensintesis bingkai koheren sementara. Model itu digambarkan sebagai berprestasi Penyamanan pada berbilang rujukan (teks; imej satu-ke-banyak; klip video pendek) untuk menghasilkan perwakilan video terpendam yang kemudiannya dinyahkodkan kepada imej setiap bingkai sambil mengekalkan ketekalan temporal melalui perhatian bingkai silang atau modul temporal khusus.
1. Multimodal Transformer + Long Context Architecture
Model O1 menggunakan seni bina Transformer berbilangmodal yang dibangunkan sendiri oleh Keling, menyepadukan isyarat teks, imej dan video serta menyokong memori konteks temporal yang panjang (Konteks Panjang Pelbagai Modal).
Ini membolehkan model memahami kesinambungan temporal dan ketekalan spatial semasa penjanaan video.
2. MVL: Bahasa Visual Multimodal
MVL ialah inovasi teras seni bina ini.
Ia menjajarkan secara mendalam bahasa dan isyarat visual dalam Transformer melalui lapisan perantaraan semantik bersatu, dengan itu:
- Membenarkan satu kotak input untuk mencampurkan arahan multimodal;
- Meningkatkan pemahaman model yang tepat tentang huraian bahasa semula jadi;
- Menyokong penjanaan video interaktif yang sangat fleksibel.
Pengenalan MVL menandakan peralihan dalam penjanaan video daripada "didorong teks" kepada "didorong bersama semantik-visual."
3. Mekanisme Inferens Rantaian Pemikiran
Model O1 memperkenalkan laluan inferens "Chain-of-Thought" semasa peringkat penjanaan video.
Mekanisme ini membolehkan model melakukan logik peristiwa dan potongan masa sebelum penjanaan, dengan itu mengekalkan hubungan semula jadi antara tindakan dan peristiwa dalam video.
Inferens dan edit saluran paip
- Penjanaan: suapan: (teks + rujukan imej pilihan + rujukan video pilihan + tetapan penjanaan) → model menghasilkan bingkai video terpendam → menyahkod kepada bingkai → warna pilihan/pemprosesan pasca temporal.
- Suntingan berasaskan arahan: suapan: (video asal + arahan teks + rujukan imej pilihan) → model secara dalaman memetakan suntingan yang diminta kepada satu set transformasi ruang piksel dan kemudian mensintesis bingkai yang diedit sambil mengekalkan kandungan yang tidak berubah. Oleh kerana semuanya berada dalam satu model, modul pelaziman dan temporal yang sama digunakan untuk penciptaan dan pengeditan.
Kling Viedo o1 lwn Veo 3.1 lwn Landasan Aleph
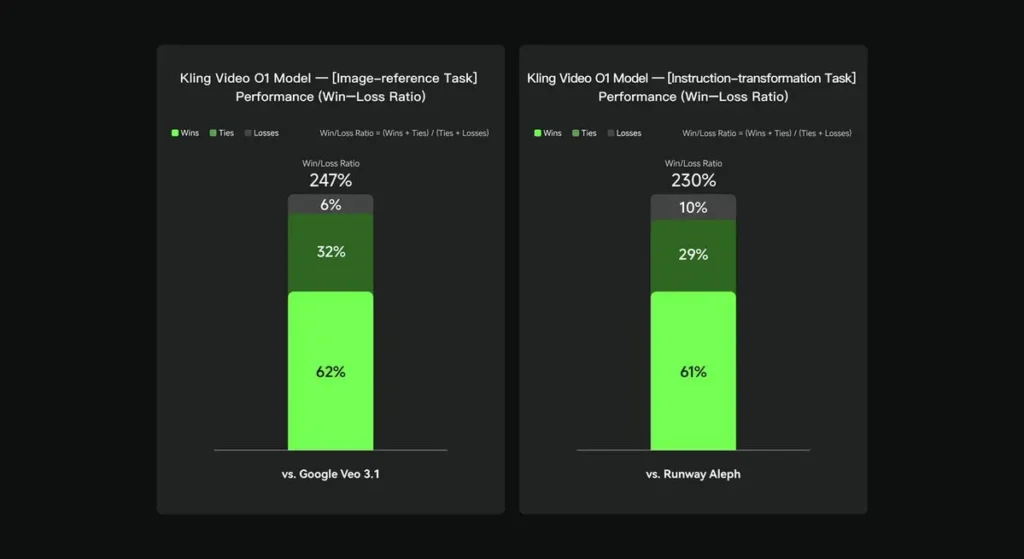
Dalam penilaian dalaman, Keling Video O1 mengatasi prestasi antarabangsa yang sedia ada dalam beberapa dimensi utama. Keputusan Prestasi (berdasarkan set penilaian yang dibina sendiri oleh Keling AI):
- Tugasan "Rujukan Imej": O1 mengatasi Google Veo 3.1 secara keseluruhan, dengan kadar kemenangan 247%;
- Tugasan "Transformasi Arahan": O1 mengatasi Runway Aleph, dengan kadar kemenangan 230%.
Gambar pesaing (perbandingan peringkat ciri)
| Keupayaan / Model | Kling O1 | Google Veo 3.1 | Landasan (Aleph / Gen-4.5) |
|---|---|---|---|
| Gesaan multimodal bersatu (teks+imej+video) | Ya (titik jualan teras). aliran multimodal permintaan tunggal. | Separa — teks→video + rujukan wujud; kurang penekanan pada MVL bersatu tunggal. | Landasan memberi tumpuan kepada penjanaan + penyuntingan tetapi selalunya sebagai mod berasingan; Gen-4.5 terkini mengecilkan jurang. |
| Pengeditan piksel berasaskan perbualan / teks | Ya — “edit seperti perbualan” (tiada topeng). | Separa — pengeditan wujud tetapi aliran kerja topeng/bingkai kunci masih biasa. | Landasan mempunyai alatan edit yang kuat; Landasan mendakwa perubahan arahan yang kuat (berbeza mengikut pelepasan). |
| Kawalan bingkai mula / tamat & rujukan kamera | Ya — bingkai mula/akhir eksplisit dan pergerakan kamera rujukan diterangkan. | Terhad / berkembang | Landasan: menambah baik kawalan; bukan UX yang sama. |
| Penjanaan klip panjang (kesetiaan tinggi) | sehingga ~2 minit (1080p, 30fps) dalam bahan produk dan siaran komuniti; | Veo 3.1: koheren kuat tetapi versi terdahulu mempunyai lalai yang lebih pendek; berbeza mengikut model/tetapan. | Landasan Gen-4.5: menyasarkan kualiti yang tinggi; panjang/kesetiaan berbeza-beza. |
Kesimpulan:
Tuntutan awam Kling O1 untuk kemasyhuran adalah penyatuan aliran kerja: memberikan satu model mandat untuk memahami teks, imej dan video serta melaksanakan kedua-dua generasi dan penyuntingan berasaskan arahan yang kaya dalam sistem semantik yang sama. Bagi pencipta dan pasukan yang kerap berpindah antara langkah "buat", "edit" dan "lanjutkan", penyatuan itu secara mendadak boleh memudahkan kelajuan lelaran dan kerumitan alatan. Kekonsistenan temporal yang dipertingkatkan, kawalan bingkai mula/akhir dan integrasi platform pragmatik yang menjadikannya boleh diakses oleh pencipta.
Kling Video o1 API akan tersedia di CometAPI tidak lama lagi.
Pembangun boleh mengakses Kling 2.5 Turb and API Veo 3.1 melalui CometAPI, model terkini yang disenaraikan adalah pada tarikh penerbitan artikel. Untuk memulakan, terokai keupayaan model dalam Taman Permainan dan berunding dengan Panduan API untuk arahan terperinci. Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda menyepadukan.
Bersedia untuk Pergi?→ Daftar untuk CometAPI hari ini !
Jika anda ingin mengetahui lebih banyak petua, panduan dan berita tentang AI, ikuti kami VK, X and Perpecahan!