

Pada 17 Jun, Shanghai AI unicorn MiniMax secara rasmi bersumberkan sumber terbuka MiniMax‑M1, model inferens perhatian hibrid berskala besar berat terbuka pertama di dunia. Dengan menggabungkan seni bina Campuran Pakar (MoE) dengan mekanisme Perhatian Kilat baharu, MiniMax‑M1 memberikan keuntungan besar dalam kelajuan inferens, pengendalian konteks ultra-panjang dan prestasi tugas yang kompleks.
Latar Belakang dan Evolusi
Membina di atas asas MiniMax-Teks-01, yang memperkenalkan perhatian kilat pada rangka kerja Campuran Pakar (MoE) untuk mencapai konteks 1 juta token semasa latihan dan sehingga 4 juta token pada inferens, MiniMax-M1 mewakili generasi seterusnya siri MiniMax-01. Model pendahulu, MiniMax-Text-01, mengandungi 456 bilion jumlah parameter dengan 45.9 bilion diaktifkan setiap token, menunjukkan prestasi setanding dengan LLM peringkat teratas sambil meluaskan keupayaan konteks .
Ciri Utama MiniMax‑M1
- MoE Hibrid + Perhatian Kilat: MiniMax‑M1 menggabungkan reka bentuk Mixture-of-Experts yang jarang—456 bilion jumlah parameter, tetapi hanya 45.9 bilion diaktifkan setiap token—dengan Lightning Attention, perhatian kerumitan linear yang dioptimumkan untuk jujukan yang sangat panjang.
- Konteks Ultra-Panjang: Menyokong sehingga 1 juta token input—kira-kira lapan kali had 128 K DeepSeek‑R1—membolehkan pemahaman mendalam tentang dokumen besar-besaran .
- Kecekapan Unggul: Apabila menjana 100 K token, Perhatian Kilat MiniMax‑M1 hanya memerlukan ~25–30% daripada pengiraan yang digunakan oleh DeepSeek‑R1.
Varian Model
- MiniMax‑M1‑40K: Konteks token 1 M, belanjawan inferens token 40 K
- MiniMax‑M1‑80K: Konteks token 1 M, belanjawan inferens token 80 K
Dalam senario penggunaan alat TAU‑bench, varian 40K mengatasi semua model berat terbuka—termasuk Gemini 2.5 Pro—menunjukkan keupayaan ejennya.
Kos Latihan & Persediaan
MiniMax-M1 telah dilatih hujung ke hujung menggunakan pembelajaran pengukuhan berskala besar (RL) merentasi pelbagai set tugasan—daripada penaakulan matematik lanjutan kepada persekitaran kejuruteraan perisian berasaskan kotak pasir. Algoritma baru, CISPO (Pensampelan Kepentingan Terpotong untuk Pengoptimuman Dasar), meningkatkan lagi kecekapan latihan dengan memotong wajaran pensampelan kepentingan dan bukannya kemas kini peringkat token. Pendekatan ini, digabungkan dengan perhatian kilat model, membenarkan latihan RL penuh pada 512 H800 GPU selesai dalam masa tiga minggu sahaja dengan jumlah kos sewa sebanyak $534,700.
Ketersediaan dan Harga
MiniMax-M1 dikeluarkan di bawah Apache 2.0 lesen sumber terbuka dan boleh diakses serta-merta melalui:
- repositori GitHub, termasuk pemberat model, skrip latihan dan penanda aras penilaian .
- SiliconCloud pengehosan, menawarkan dua varian—40 K‑token (“M1‑40K”) dan 80 K‑token (“M1‑80K”)—dengan rancangan untuk mendayakan corong token 1 M penuh.
- Harga ditetapkan pada masa ini pada ¥4 setiap juta token untuk input dan ¥16 setiap juta token untuk output, dengan diskaun volum tersedia untuk pelanggan perusahaan .
Pembangun dan organisasi boleh menyepadukan MiniMax-M1 melalui API standard, memperhalusi data khusus domain atau menggunakan di premis untuk beban kerja yang sensitif.
Prestasi Tahap Tugas
| Kategori Tugasan | Serlahkan | Prestasi Relatif |
|---|---|---|
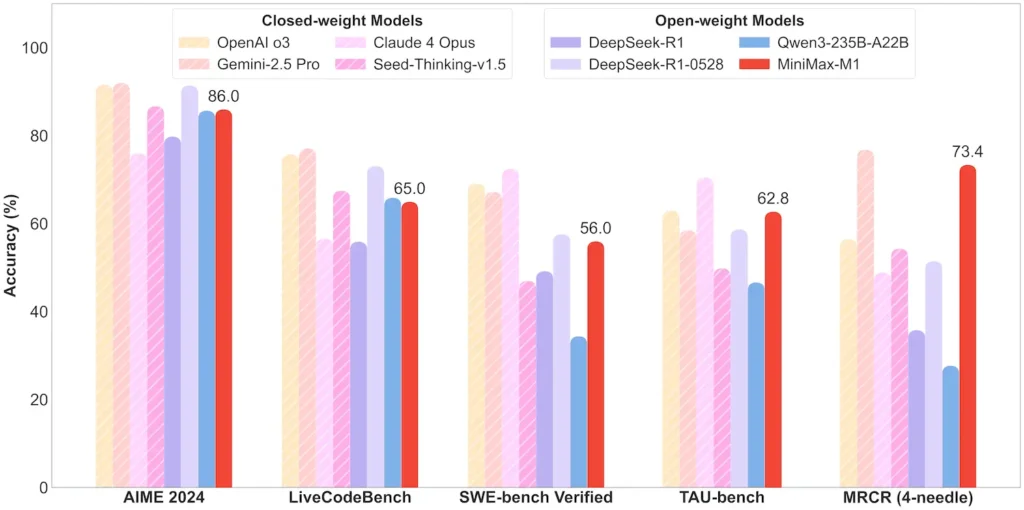
| Matematik & Logik | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; berhampiran sumber tertutup |
| Pemahaman Konteks Panjang | Pembaris (4 K–1 M token): Peringkat atas yang stabil | Mengungguli GPT‑4 melebihi panjang token 128 K |
| Kejuruteraan Perisian | SWE-bench (pepijat GitHub sebenar): 56% | Terbaik dalam kalangan model terbuka; ke-2 hingga mendahului ditutup |
| Penggunaan Ejen & Alat | TAU‑bench (simulasi API) | 62–63.5% lwn Gemini 2.5, Claude 4 |
| Dialog & Penolong | Pelbagai Cabaran: 44.7% | Padan dengan Claude 4, DeepSeek‑R1 |
| QA fakta | SimpleQA: 18.5% | Kawasan untuk penambahbaikan masa hadapan |
Nota: peratusan dan tanda aras daripada pendedahan rasmi MiniMax dan laporan berita bebas
Inovasi Teknikal
- Timbunan Perhatian Hibrid: Perhatian Kilat lapisan (kos linear) dijalin dengan Perhatian Softmax berkala (kuadrat tetapi lebih ekspresif) untuk mengimbangi kecekapan dan kuasa pemodelan.
- Penghalaan KPM Jarang: 32 modul pakar; setiap token hanya mengaktifkan ~10% daripada jumlah parameter, mengurangkan kos inferens sambil mengekalkan kapasiti.
- Pembelajaran Pengukuhan CISPO: Algoritma baru "Pengoptimuman Dasar Berat IS Terpotong" yang mengekalkan token yang jarang tetapi penting dalam isyarat pembelajaran, mempercepatkan kestabilan dan kelajuan RL.
Keluaran berat terbuka MiniMax‑M1 membuka kunci konteks ultra-panjang, inferens kecekapan tinggi untuk semua orang—merapatkan jurang antara penyelidikan dan AI skala besar yang boleh digunakan.
Bermula
CometAPI menyediakan antara muka REST bersatu yang mengagregatkan ratusan model AI—termasuk keluarga ChatGPT—di bawah titik akhir yang konsisten, dengan pengurusan kunci API terbina dalam, kuota penggunaan dan papan pemuka pengebilan. Daripada menyulap berbilang URL vendor dan bukti kelayakan.
Untuk bermula, terokai keupayaan model dalam Taman Permainan dan berunding dengan Panduan API untuk arahan terperinci. Sebelum mengakses, sila pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API.
Penyepaduan MiniMax‑M1 API terbaharu akan muncul di CometAPI tidak lama lagi, jadi nantikan!Sementara kami memuktamadkan muat naik Model MiniMax‑M1, teroka model kami yang lain di Halaman model atau cuba mereka dalam Taman Permainan AI. Model terbaru MiniMax dalam CometAPI ialah API Pratonton ABAB7 Minimax and API Video-01 MiniMax , rujuk:
