Gemini 2.5 Flash direka bentuk untuk memberikan respons pantas tanpa menjejaskan kualiti output. Ia menyokong input multimodal, termasuk teks, imej, audio dan video, menjadikannya sesuai untuk pelbagai aplikasi. Model ini boleh diakses melalui platform seperti Google AI Studio dan Vertex AI, menyediakan pembangun alat yang diperlukan untuk integrasi yang lancar ke dalam pelbagai sistem.
Maklumat Asas (Ciri)
Gemini 2.5 Flash memperkenalkan beberapa ciri menonjol yang membezakannya dalam keluarga Gemini 2.5:
- Penaakulan Hibrid: Pembangun boleh menetapkan parameter thinking_budget untuk mengawal dengan teliti jumlah token yang diperuntukkan model kepada penaakulan dalaman sebelum output .
- Sempadan Pareto: Diletakkan pada titik kos-prestasi yang optimum, Flash menawarkan nisbah harga-ke-kepintaran terbaik dalam kalangan model 2.5 .
- Sokongan Multimodal: Memproses teks, imej, video dan audio secara natif, membolehkan keupayaan perbualan dan analitik yang lebih kaya .
- Konteks 1 Juta Token: Panjang konteks yang tiada tandingan membolehkan analisis mendalam dan pemahaman dokumen panjang dalam satu permintaan .
Pengversian Model
Gemini 2.5 Flash telah melalui versi utama berikut:
- gemini-2.5-flash-lite-preview-09-2025: Kebolehgunaan alat dipertingkat: Prestasi yang lebih baik pada tugas kompleks berbilang langkah, dengan peningkatan 5% dalam skor SWE-Bench Verified (daripada 48.9% kepada 54%). Kecekapan dipertingkat: Apabila mengaktifkan penaakulan, output berkualiti lebih tinggi dicapai dengan lebih sedikit token, mengurangkan kependaman dan kos.
- Pratonton 04-17: Keluaran akses awal dengan keupayaan “thinking”, tersedia melalui gemini-2.5-flash-preview-04-17.
- Ketersediaan Umum Stabil (GA): Mulai 17 Jun 2025, titik akhir stabil gemini-2.5-flash menggantikan pratonton, memastikan kebolehpercayaan gred pengeluaran tanpa perubahan API daripada pratonton 20 Mei .
- Penamatan Pratonton: Titik akhir pratonton dijadualkan ditamatkan pada 15 Julai 2025; pengguna mesti berpindah ke titik akhir GA sebelum tarikh ini .
Mulai Julai 2025, Gemini 2.5 Flash kini tersedia secara umum dan stabil (tiada perubahan daripada gemini-2.5-flash-preview-05-20 ).Jika anda menggunakan gemini-2.5-flash-preview-04-17, harga pratonton sedia ada akan diteruskan sehingga penamatan berjadual titik akhir model pada 15 Julai 2025, apabila ia akan ditutup. Anda boleh berpindah ke model yang tersedia umum "gemini-2.5-flash" .
Lebih pantas, lebih murah, lebih pintar:
- Matlamat reka bentuk: kependaman rendah + kadar pemprosesan tinggi + kos rendah;
- Peningkatan kelajuan keseluruhan dalam penaakulan, pemprosesan multimodal dan tugas teks panjang;
- Penggunaan token dikurangkan sebanyak 20–30%, dengan ketara mengurangkan kos penaakulan.
Spesifikasi Teknikal
Tetingkap Konteks Input: Sehingga 1 juta token, membolehkan pengekalan konteks yang meluas.
Token Output: Mampu menjana sehingga 8,192 token bagi setiap respons.
Modaliti Disokong: Teks, imej, audio dan video.
Platform Integrasi: Tersedia melalui Google AI Studio dan Vertex AI.
Penetapan Harga: Model harga berasaskan token yang kompetitif, memudahkan pelaksanaan yang menjimatkan kos.
Butiran Teknikal
Di bawah hud, Gemini 2.5 Flash ialah model bahasa besar berasaskan transformer yang dilatih pada campuran data web, kod, imej dan video. Spesifikasi teknikal utama termasuk:
Latihan Multimodal: Dilatih untuk menyelaraskan pelbagai modaliti, Flash boleh menggabungkan teks dengan imej, video atau audio secara lancar, berguna untuk tugas seperti pemeringkasan video atau kapsyen audio .
Proses Pemikiran Dinamik: Melaksanakan gelung penaakulan dalaman di mana model merancang dan menghuraikan gesaan kompleks sebelum output akhir .
Bajet Pemikiran Boleh Dikonfigurasi: thinking_budget boleh ditetapkan dari 0 (tiada penaakulan) sehingga 24,576 token, membolehkan pertukaran antara kependaman dan kualiti jawapan .
Integrasi Alat: Menyokong Grounding with Google Search, Pelaksanaan Kod, Konteks URL dan Pemanggilan Fungsi, membolehkan tindakan dunia sebenar terus daripada gesaan bahasa semula jadi .
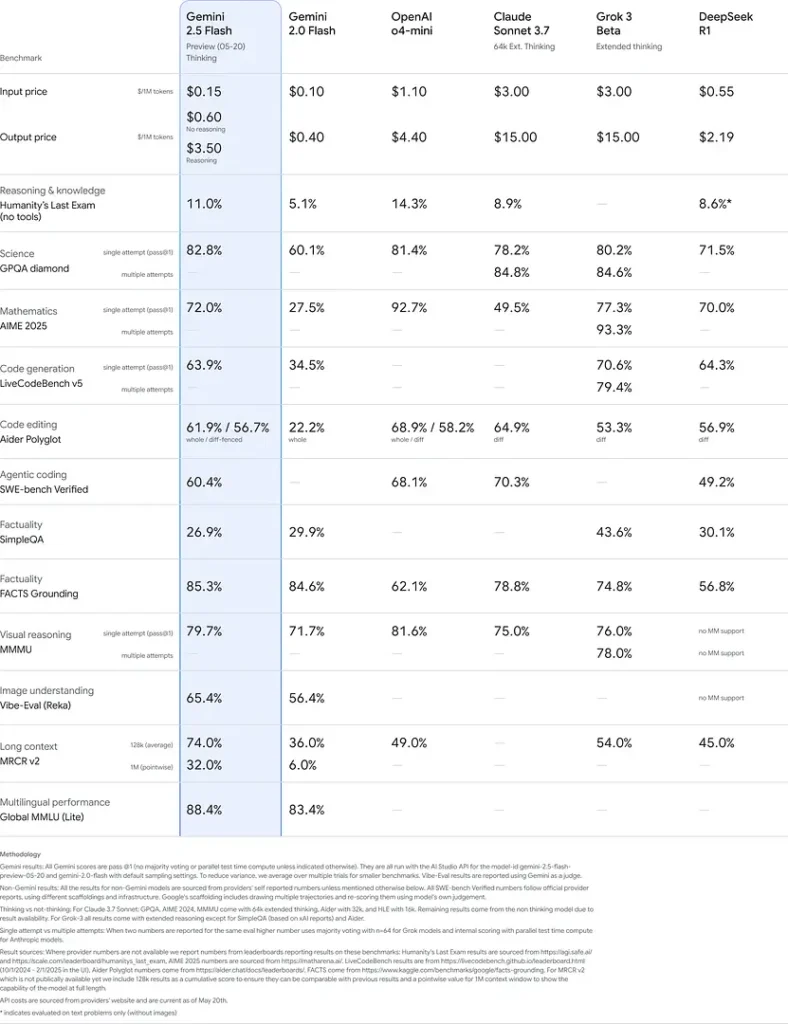
Prestasi Penanda Aras
Dalam penilaian yang ketat, Gemini 2.5 Flash menunjukkan prestasi terkemuka industri:
- LMArena Hard Prompts: Mendapat skor kedua selepas 2.5 Pro pada penanda aras Hard Prompts yang mencabar, memperlihatkan keupayaan penaakulan berbilang langkah yang kukuh .
- Skor MMLU 0.809: Melebihi prestasi purata model dengan ketepatan MMLU 0.809, mencerminkan pengetahuan domain yang luas dan kehebatan penaakulan .
- Kependaman dan Kadar Pemprosesan: Mencapai kelajuan penyahkodan 271.4 token/saat dengan 0.29 s Time-to-First-Token, menjadikannya ideal untuk beban kerja sensitif kependaman.
- Peneraju Harga-ke-Prestasi: Pada \$0.26/1 M token, Flash mengatasi banyak pesaing sambil menyamai atau mengatasi mereka pada penanda aras utama .
Keputusan ini menunjukkan kelebihan kompetitif Gemini 2.5 Flash dalam penaakulan, pemahaman saintifik, penyelesaian masalah matematik, pengkodan, interpretasi visual dan keupayaan berbilang bahasa:
Had
Walaupun berkuasa, Gemini 2.5 Flash mempunyai beberapa had:
- Risiko Keselamatan: Model boleh menunjukkan nada “menggurui” dan mungkin menghasilkan output yang kedengaran meyakinkan tetapi salah atau berat sebelah (halusinasi), terutamanya pada pertanyaan kes tepi. Pengawasan manusia yang ketat kekal penting.
- Had Kadar: Penggunaan API dihadkan oleh had kadar (10 RPM, 250,000 TPM, 250 RPD pada peringkat lalai), yang boleh menjejaskan pemprosesan kelompok atau aplikasi volum tinggi.
- Paras Kecerdasan Asas: Walaupun amat berkeupayaan untuk model flash, ia masih kurang tepat berbanding 2.5 Pro pada tugas berasaskan ejen yang paling mencabar seperti pengkodan lanjutan atau penyelarasan berbilang ejen.
- Pertukaran Kos: Walaupun menawarkan harga-prestasi terbaik, penggunaan meluas mod “thinking” meningkatkan penggunaan token keseluruhan, menaikkan kos untuk gesaan yang memerlukan penaakulan mendalam .