Perincian Teknikal
- Penaakulan Adaptif:
Gemini 2.5 Flash-Litemenyokong pemikiran atas permintaan, membolehkan pembangun memperuntukkan sumber pengkomputeran hanya apabila penaakulan mendalam diperlukan. - Integrasi Alat: Keserasian penuh dengan alat asli Gemini 2.5, termasuk Grounding with Google Search, Code Execution, URL Context dan Function Calling untuk aliran kerja multimodal yang lancar.
- Model Context Protocol (MCP): Memanfaatkan MCP Google untuk mendapatkan data web masa nyata, memastikan respons terkini dan relevan secara kontekstual.
- Pilihan Penerapan: Tersedia melalui CometAPI, Gemini API, Vertex AI dan Google AI Studio, dengan laluan pratonton untuk pengguna awal mencuba dan memberikan maklum balas.
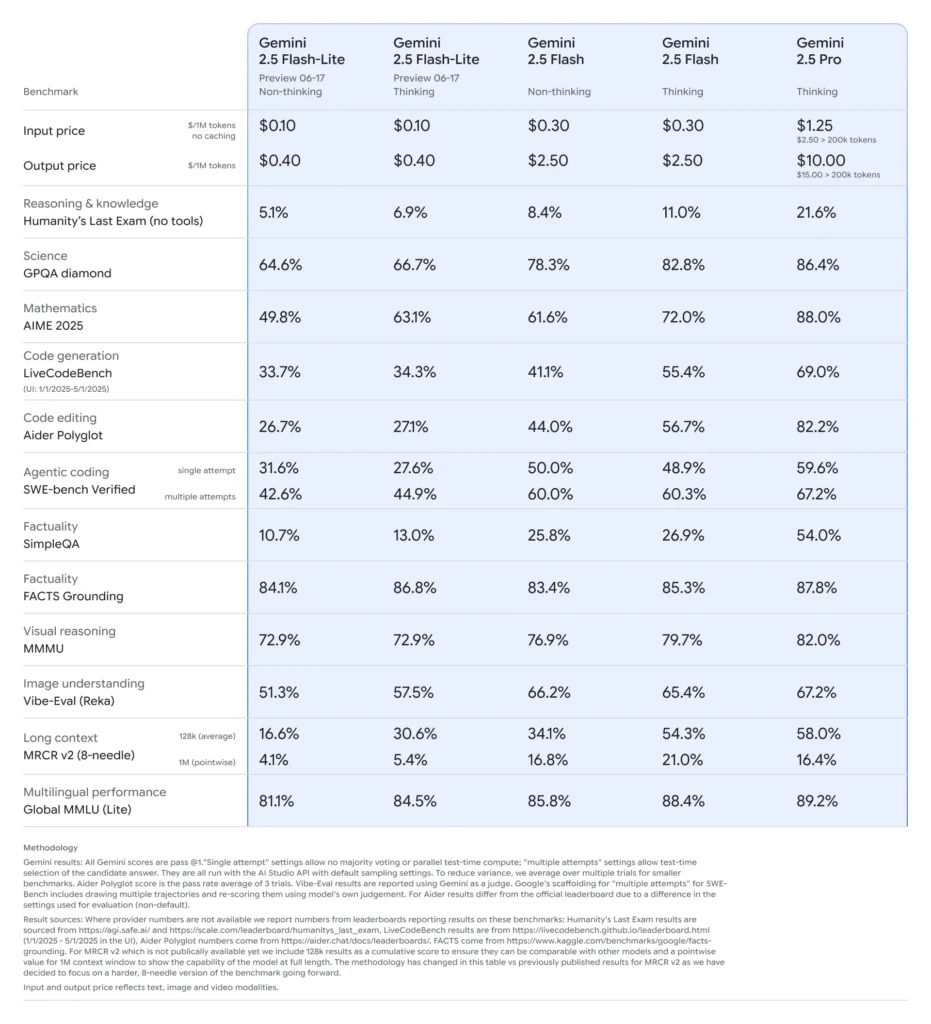
Prestasi Penanda Aras Gemini 2.5 Flash-Lite
- Latensi: Mencapai sehingga 50% lebih rendah pada masa tindak balas median berbanding Gemini 2.5 Flash, dengan latensi bawah 100 ms pada penanda aras standard pengelasan dan peringkasan.
- Kadar Aliran: Dioptimumkan untuk beban kerja bervolum tinggi, mengekalkan puluhan ribu permintaan seminit tanpa kemerosotan prestasi.
- Harga-Prestasi: Menunjukkan pengurangan 25% dalam kos per 1,000 token berbanding versi Flash, menjadikannya pilihan Pareto-optimal untuk penerapan peka kos.
- Penerimaan Industri: Pengguna awal melaporkan integrasi yang lancar ke dalam saluran pengeluaran, dengan metrik prestasi yang sejajar dengan atau melebihi unjuran awal.
Kes Penggunaan Ideal
- Tugas Frekuensi Tinggi, Kerumitan Rendah: Pelabelan automatik, analisis sentimen dan terjemahan pukal
- Aliran Kerja Peka Kos: Pengekstrakan data daripada korpus dokumen besar, peringkasan kelompok berkala
- Senario Edge dan Mudah Alih: Apabila latensi kritikal tetapi bajet sumber terhad
Keterbatasan Gemini 2.5 Flash-Lite
- Status Pratonton: Mungkin mengalami perubahan API sebelum GA; integrasi perlu mengambil kira kemungkinan lonjakan versi.
- Tiada Penalaan Halus On-the-Fly: Tidak boleh memuat naik berat model tersuai; bergantung pada kejuruteraan prompt dan mesej sistem.
- Kreativiti Berkurang: Ditala untuk tugas deterministik dan kadar aliran tinggi; kurang sesuai untuk penjanaan terbuka atau penulisan “kreatif”.
- Had Sumber: Skala secara linear hanya sehingga ~16 vCPU; selebihnya, peningkatan kadar aliran berkurangan.
- Kekangan Multimodal: Menyokong input imej/audio tetapi dengan fideliti terhad; tidak sesuai untuk tugasan visi berat atau transkripsi audio.
- Pertukaran Tetingkap Konteks: Walaupun menerima sehingga 1 M token, inferens praktikal pada skala tersebut mungkin mengalami penurunan kadar aliran.