
Qwen3-Max-Preview ialah model pratonton perdana terbaharu Alibaba dalam keluarga Qwen3 — satu trilion+-parameter, model gaya Campuran Pakar (MoE) dengan tetingkap konteks token 262k ultra panjang, dikeluarkan dalam pratonton untuk kegunaan perusahaan/awan. Ia menyasarkan *penaakulan mendalam, pemahaman dokumen panjang, pengekodan dan aliran kerja agen.
Maklumat asas & ciri tajuk
- Nama / Label:
qwen3-max-preview(Arahan). - Skala: Lebih 1 trilion parameter (trilion-parameter perdana). Ini adalah pencapaian penting pemasaran/statistik untuk keluaran.
- Tetingkap konteks: Token 262,144 (menyokong input yang sangat panjang dan transkrip berbilang fail).
- Mod: Varian "Arahan" yang ditala arahan dengan sokongan untuk berfikir (rantai pemikiran yang disengajakan) dan tidak berfikir mod pantas dalam keluarga Qwen3.
- Availability: Pratonton akses melalui Sembang Qwen, Studio Model Awan Alibaba (titik akhir serasi OpenAI atau DashScope) dan penyedia penghalaan seperti CometAPI.
Butiran teknikal (seni bina & mod)
- Senibina: Qwen3-Max mengikuti garis keturunan reka bentuk Qwen3 yang menggunakan campuran padat + Campuran Pakar (KPM) komponen dalam varian yang lebih besar, ditambah dengan pilihan kejuruteraan untuk mengoptimumkan kecekapan inferens untuk kiraan parameter yang sangat besar.
- Mod berfikir vs mod tidak berfikir: Siri Qwen3 memperkenalkan a mod berfikir (untuk output gaya rantaian pemikiran berbilang langkah) dan mod tidak berfikir untuk balasan yang lebih cepat dan ringkas; platform mendedahkan parameter untuk menogol gelagat ini.
- Ciri caching / prestasi konteks: Senarai Model Studio cache konteks sokongan untuk permintaan besar untuk mengurangkan kos input berulang dan meningkatkan daya pengeluaran pada konteks berulang.
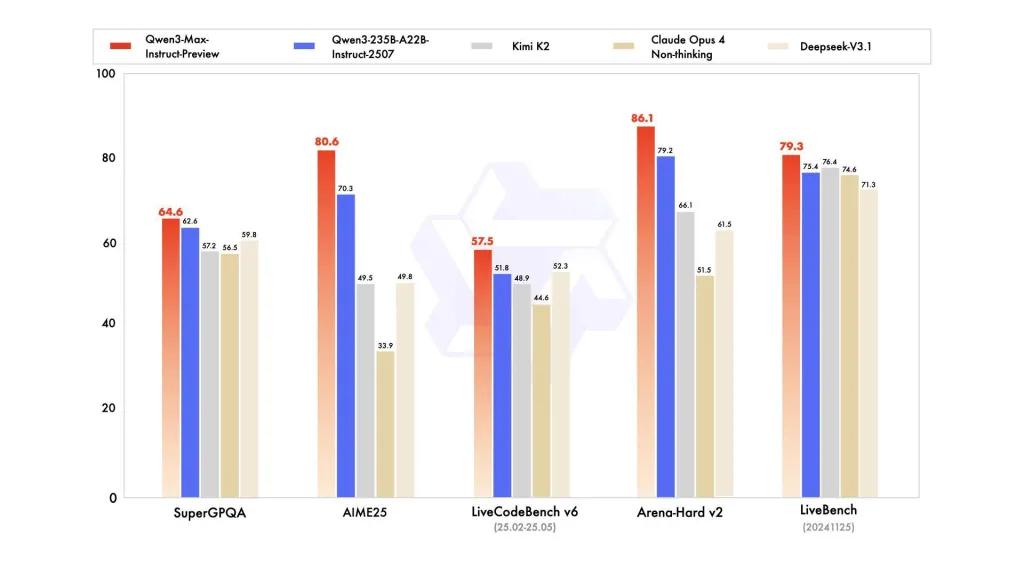
Prestasi penanda aras
laporan merujuk kepada SuperGPQA, varian LiveCodeBench, AIME25 dan suite peraduan/penanda aras lain di mana Qwen3-Max kelihatan berdaya saing atau terkemuka.
Had & risiko (nota praktikal dan keselamatan)
- Kelegapan untuk resipi / pemberat latihan penuh: Sebagai pratonton, bahan latihan/data/pelepasan berat dan kebolehulangan penuh mungkin terhad berbanding keluaran Qwen3 berat terbuka yang terdahulu. Beberapa model keluarga Qwen3 dikeluarkan dengan berat terbuka, tetapi Qwen3-Max sedang dihantar sebagai pratonton terkawal untuk akses awan. ini mengurangkan kebolehulangan untuk penyelidik bebas.
- Halusinasi & fakta: Laporan vendor mendakwa pengurangan dalam halusinasi, tetapi penggunaan dunia sebenar masih akan menemui ralat fakta dan pernyataan terlalu yakin — kaveat LLM standard dikenakan. Penilaian bebas adalah perlu sebelum penggunaan berkepentingan tinggi.
- Kos mengikut skala: Dengan tetingkap konteks yang besar dan keupayaan tinggi, kos token boleh menjadi besar untuk gesaan atau pengeluaran pengeluaran yang sangat panjang. Gunakan caching, chunking dan kawalan belanjawan.
- Pertimbangan kawal selia dan kedaulatan data: Pengguna perusahaan harus menyemak wilayah Awan Alibaba, residensi data dan implikasi pematuhan sebelum memproses maklumat sensitif. (Dokumentasi Model Studio termasuk titik akhir dan nota khusus wilayah.)
Kes-kes penggunaan
- Dokumen pemahaman / ringkasan pada skala: taklimat undang-undang, spesifikasi teknikal dan pangkalan pengetahuan berbilang fail (faedah: Token 262K tingkap).
- Bantuan penaakulan kod konteks panjang & kod skala repositori: pemahaman kod berbilang fail, ulasan PR yang besar, cadangan pemfaktoran semula peringkat repositori.
- Tugas penaakulan dan rantaian pemikiran yang kompleks: pertandingan matematik, perancangan berbilang langkah, aliran kerja ejentik di mana jejak "berfikir" membantu kebolehkesanan.
- Berbilang bahasa, Soal Jawab perusahaan dan pengekstrakan data berstruktur: sokongan korporat berbilang bahasa yang besar dan keupayaan output berstruktur (JSON / jadual).
Bagaimana untuk memanggil Qqwen3-max-preview API daripada CometAPI
qwen3-max-preview Harga API dalam CometAPI,diskaun 20% daripada harga rasmi:
| Token Input | $0.24 |
| Token Keluaran | $2.42 |
Langkah yang Diperlukan
- Log masuk ke cometapi.com. Jika anda belum menjadi pengguna kami, sila daftar dahulu
- Dapatkan kunci API kelayakan akses antara muka. Klik "Tambah Token" pada token API di pusat peribadi, dapatkan kunci token: sk-xxxxx dan serahkan.
- Dapatkan url tapak ini: https://api.cometapi.com/
Gunakan Kaedah
- Pilih titik akhir "qwen3-max-preview" untuk menghantar permintaan API dan menetapkan badan permintaan. Kaedah permintaan dan badan permintaan diperoleh daripada dokumen API tapak web kami. Laman web kami juga menyediakan ujian Apifox untuk kemudahan anda.
- Gantikan dengan kunci CometAPI sebenar anda daripada akaun anda.
- Masukkan soalan atau permintaan anda ke dalam medan kandungan—inilah yang akan dijawab oleh model.
- . Proses respons API untuk mendapatkan jawapan yang dijana.
Panggilan API
CometAPI menyediakan REST API yang serasi sepenuhnya—untuk penghijrahan yang lancar. Butiran penting kepada Dokumen API:
- Parameter Teras:
prompt,max_tokens_to_sample,temperature,stop_sequences - Titik Akhir:
https://api.cometapi.com/v1/chat/completions - Parameter Model: qwen3-max-preview
- Pengesahan:
Bearer YOUR_CometAPI_API_KEY - Jenis kandungan:
application/json.
Ganti
CometAPI_API_KEYdengan kunci anda; perhatikan URL asas.
Python (permintaan) — serasi OpenAI
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Petua: penggunaan max_input_tokens, max_output_tokens, dan Model Studio cache konteks ciri apabila menghantar konteks yang sangat besar untuk mengawal kos dan pemprosesan.
See Also Qwen3-Pengekod