

Gemini Embedding 2 ialah model embedding pertama Google yang multimodal natif yang memetakan teks, imej, audio, video dan PDF ke dalam satu ruang vektor semantik 3,072 dimensi (dengan saiz output boleh dikonfigurasi). Ia memperkenalkan Matryoshka Representation Learning untuk menyediakan embedding bersarang/terpotong, prestasi berbilang bahasa yang dipertingkat (100+ bahasa), serta kawalan yang dioptimumkan untuk embedding khusus tugasan (cth., task:search, task:code).
Apakah Gemini Embedding 2?
Gemini Embedding 2 ialah model embedding bersatu daripada Google yang memetakan pelbagai modaliti input — teks, imej, audio, video dan dokumen — ke dalam satu ruang vektor semantik. Setiap embedding ialah (secara lalai) vektor titik apung 3,072 dimensi yang mewakili makna semantik input supaya item yang serupa secara semantik (tanpa mengira modaliti) berada berdekatan dalam ruang vektor. Keupayaan utama adalah:
- Liputan bahasa dan format yang luas: satu model yang menerima teks, imej, audio, video dan dokumen serta meletakkannya dalam satu ruang vektor semantik. Gemini Embedding 2 didokumenkan dapat menangkap niat semantik merentas 100+ bahasa dan menerima format fail lazim (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), dengan had konkrit per permintaan (cth., sehingga beberapa imej atau puluhan saat audio/video bagi setiap permintaan — rujuk “Cara menggunakan” di bawah).
- Multimodal sebenar: satu model yang menerima teks, imej, audio, video dan dokumen serta meletakkannya dalam satu ruang vektor semantik supaya anda boleh membanding atau mendapatkan semula merentas modaliti (cth., teks → imej, audio → teks).
- Dimensi lalai besar dengan pemotongan fleksibel: model mengeluarkan vektor 3072 dimensi secara lalai, tetapi menggunakan Matryoshka Representation Learning (MRL) untuk menumpukan kandungan semantik paling penting pada dimensi awal supaya anda boleh memotong kepada 1536, 768 (atau lebih rendah) dengan hanya penurunan kecil pada kualiti pengambilan. Ini mengurangkan pertukaran kos storan dan pengiraan.
Mengapa ini penting. Secara sejarah, embedding kebanyakannya hanya teks atau memerlukan pengenkod berasingan bagi setiap modaliti dengan lapisan penjajaran antara modaliti yang kompleks. Gemini Embedding 2 menyingkirkan halangan itu dengan menyokong pelbagai format secara natif — jadi pertanyaan teks boleh mendapatkan semula imej atau klip pendek berdasarkan keserupaan semantik tanpa transkripsi perantaraan atau pemetaan manual. Itu memudahkan RAG (retrieval-augmented generation), carian semantik dan saluran paip pengambilan multimodal.
Ciri & keupayaan utama (apa yang baharu)
1. Multimodal natif sebenar (satu ruang embedding)
Satu model yang menerima teks, imej, audio, video dan dokumen serta meletakkannya dalam satu ruang vektor semantik. Gemini Embedding 2 memetakan teks, imej, audio, video dan dokumen ke dalam ruang embedding yang sama supaya pengambilan merentas modaliti (teks→imej, audio→teks) berfungsi secara langsung tanpa penjajaran silang model. Ini mengurangkan kerumitan saluran paip dan memudahkan susunan RAG (Retrieval-Augmented Generation).
2. Vektor lalai 3,072 dimensi dengan output boleh laras
Gemini Embedding 2 mengeluarkan vektor 3072 dimensi secara lalai, tetapi menggunakan Matryoshka Representation Learning (MRL) untuk menumpukan kandungan semantik paling penting pada dimensi awal supaya anda boleh memotong kepada 1536, 768 (atau lebih rendah) dengan hanya penurunan kecil pada kualiti pengambilan. Ini mengurangkan pertukaran kos storan dan pengiraan.
3. Matryoshka Representation Learning (MRL)
MRL menghasilkan embedding “bersarang” — seperti anak patung Rusia bersarang — supaya potongan berdimensi lebih rendah mengekalkan semantik aras lebih tinggi. Ini membolehkan sistem memilih titik operasi (pertukaran storan/ketepatan) tanpa mengekalkan beberapa model embedding berasingan. Analisis awal blog dan dokumentasi menerangkan teknik ini sebagai inovasi teras untuk fleksibiliti.
4. Petunjuk tugasan / objektif embedding tersuai
API menerima petunjuk task (cth., task:search, task:code retrieval, task:semantic-similarity) supaya model boleh mengoptimumkan geometri embedding untuk hubungan hiliran khusus — serupa dengan pengkondisian tugasan yang digunakan dalam sistem embedding terdahulu tetapi diperluas kepada input multimodal.
5. Keluasan bahasa dan modaliti
Gemini Embedding 2 didokumenkan dapat menangkap niat semantik merentas 100+ bahasa dan menerima format fail lazim (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), dengan had konkrit per permintaan (cth., sehingga beberapa imej atau puluhan saat audio/video bagi setiap permintaan — rujuk “Cara menggunakan” di bawah).
Penanda aras prestasi
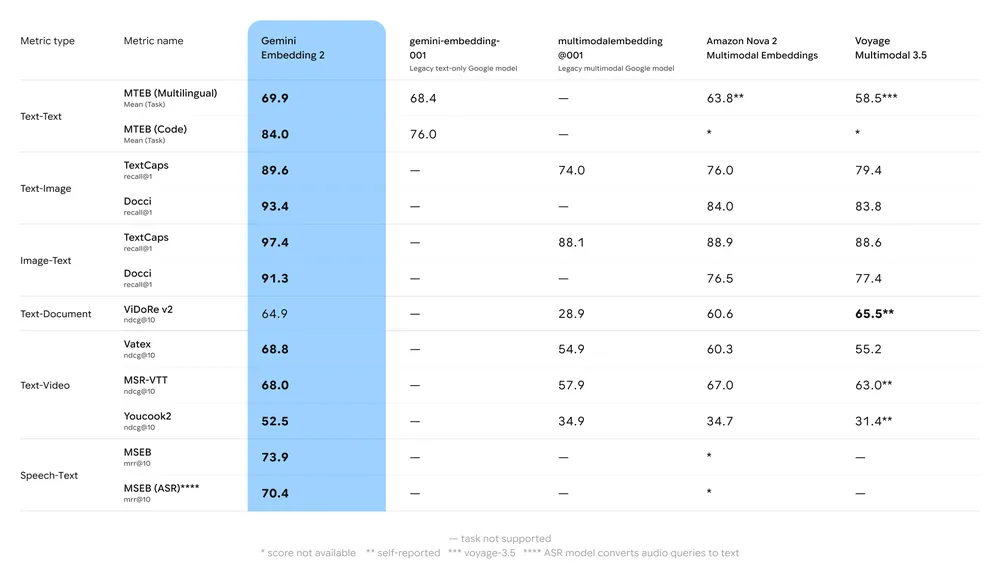
Ringkasan penanda aras utama:
- MTEB (Massive Text Embedding Benchmark): Kedudukan kukuh dilaporkan pada papan pendahulu MTEB berbilang bahasa untuk tugasan bahasa Inggeris dan berbilang bahasa; analisis menunjukkan peningkatan bermakna berbanding model embedding Gemini terdahulu dan banyak alternatif proprietari.
- Pengambilan multimodal: Mengatasi atau menyamai embedding satu modaliti terkemuka apabila digunakan untuk keserupaan merentas modaliti (cth., pengambilan teks→imej), hasil daripada latihan multimodal natif.
- Latensi & throughput: Penjanaan embedding dihoskan awan, tetapi kes penggunaan sensitif latensi mungkin memilih vektor terpotong atau model embedding ringan alternatif untuk keperluan di peranti.
Gemini Embedding 2 vs gemini-embedding-001 dan text-embedding-3-large
| Atribut | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Keluaran / ketersediaan | 10 Mac 2026 — pratonton awam (Gemini API / Vertex AI). | Embedding Gemini terdahulu (varian teks sahaja) — GA lebih awal. | Diumumkan Jan 2024 (teks sahaja GA). |
| Modaliti disokong | Teks, imej, audio, video, dokumen (PDF) — ruang vektor bersatu. | Teks (terutamanya). | Teks sahaja (berbilang bahasa berkualiti tinggi). |
| Dimensi embedding lalai | 3072 (MRL / pemotongan disyorkan: 1536, 768). | 3072 (untuk besar) — teks sahaja. | 3072 (text-embedding-3-large). |
| MTEB dilaporkan (contoh) | 60-an tinggi pada MTEB; menunjukkan 68.17 pada 1536 dalam jadual vendor (lihat docs). | gemini-embedding-001 dilaporkan ~68.32 purata dalam beberapa papan pendahulu. | ~64.6 (purata MTEB dilaporkan oleh OpenAI untuk text-embedding-3-large). |
| Sokongan audio/video natif | Ya (embedding audio/video secara langsung). | Tidak (teks sahaja). | Tidak (teks sahaja). |
| Kes penggunaan tipikal | Pengambilan multimodal, RAG, carian semantik merentas jenis fail, pengambilan pertuturan, carian video. | Pengambilan teks, RAG berbilang bahasa. | Pengambilan teks, carian semantik, RAG — prestasi teks berbilang bahasa yang kukuh. |
Spesifikasi teknikal & had
Saiz embedding lalai & boleh laras
- Lalai: 3,072 dimensi.
- Boleh laras: parameter
output_dimensionalitymembenarkan permintaan output berdimensi lebih rendah untuk menjimatkan storan/CPU. Kes penggunaan dengan stor vektor besar sering mengurangkan dimensi kepada 512–1,024 atas sebab kos tetapi menerima sedikit pertukaran ketepatan.
Modaliti disokong dan had setiap permintaan
- Imej: PNG, JPEG — sehingga 6 imej setiap permintaan (had yang dilaporkan vendor).
- Video: MP4, MOV — vendor melaporkan sehingga ~128 saat setiap video untuk embedding satu permintaan.
- Audio: MP3, WAV — vendor melaporkan sehingga ~80 saat bagi setiap input audio.
- Dokumen: PDF — sehingga 6 halaman setiap permintaan (laporan vendor).
- Had token untuk kandungan teks: model menyokong input token yang besar; had token praktikal per permintaan wujud (semak dokumentasi API dan kuota Vertex AI).
Ketersediaan & akses
- Pratonton awam: Gemini Embedding 2 dikeluarkan sebagai pratonton awam dan tersedia melalui Gemini API dan Google Cloud Vertex AI untuk kegunaan eksperimen serta-merta
Soalan lazim (FAQ)
S1: Apakah modaliti yang disokong oleh Gemini Embedding 2?
J: Teks, imej (PNG/JPEG), video (MP4/MOV), audio (MP3/WAV) dan dokumen PDF — semuanya dipetakan ke dalam ruang vektor semantik yang sama.
S2: Apakah saiz vektor lalai untuk Gemini Embedding 2?
J: Lalai ialah 3,072 dimensi. Anda boleh meminta dimensi output yang lebih kecil melalui API.
S3: Adakah Gemini Embedding 2 tersedia sekarang?
J: Ya — ia diumumkan sebagai pratonton awam dan tersedia melalui Gemini API dan Vertex AI (semak id model gemini-embedding-2-preview dan log perubahan semasa).
S4: Bagaimanakah ia dibandingkan dengan embedding daripada penyedia lain?
J: Ujian vendor bebas melaporkan Gemini Embedding 2 berada dalam kalangan model proprietari teratas untuk teks berbilang bahasa dan menunjukkan prestasi termaju untuk beberapa tugasan multimodal. Kedudukan tepat berbeza mengikut tugasan dan set data; uji pada data anda sendiri.
S5: Adakah saya perlu transkripsikan audio untuk menggunakan Gemini Embedding 2?
J: Tidak — Gemini Embedding 2 boleh menerima audio secara langsung dan menghasilkan embedding tanpa menyalin kepada teks terlebih dahulu, membolehkan pengambilan semantik audio hujung ke hujung.
S6: Bagaimanakah cara menurunkan kos storan untuk vektor 3,072 dim?
J: Pilihan termasuk meminta output_dimensionality lebih rendah, menggunakan float16/quantization/PQ, dan menyimpan perwakilan termampat dalam pangkalan data vektor anda. Catatan vendor menyediakan aliran kerja dan amalan terbaik.
Apa seterusnya — patutkah saya menggunakannya sekarang?
Gemini Embedding 2 ialah langkah besar dalam penyatuan pengambilan multimodal dan memudahkan seni bina yang sebelum ini memerlukan pengambil berasingan untuk teks, visi dan pertuturan. Titik keputusan utama untuk penerimaan:
- Guna lebih awal jika produk anda memerlukan pengambilan merentas modaliti yang teguh (teks↔imej/video/audio), atau jika mengekalkan beberapa pengambil satu modaliti adalah mahal dan kompleks.
- Rintis sekarang jika anda mahu menilai pemotongan MRL dan mengukur kos vs kualiti (kekalkan pelaksanaan hibrid: 1536 sebagai utama, 3072 untuk penyusunan semula).
- Tunggu jika beban kerja anda sangat sensitif kos dan hanya memerlukan pengambilan teks — model khusus teks teratas (cth., OpenAI text-embedding-3-large) kekal berdaya saing dan kadangkala lebih murah bergantung pada saluran paip dan kontrak anda.
Pembangun boleh mengakses Gemini Embedding 2 dan [OpenAI text-embedding-3 ]API melalui CometAPI sekarang. Untuk bermula, terokai keupayaan model dalam Playground dan rujuk API guide untuk arahan terperinci. Sebelum mengakses, pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda mengintegrasi.
Ready to Go?→ Daftar untuk cometapi hari ini !
Jika anda mahu mengetahui lebih banyak tip, panduan dan berita tentang AI, ikuti kami di VK, X dan Discord!