

Seedance 2.0 ialah model penjanaan video AI generasi seterusnya milik ByteDance, yang dilancarkan secara rasmi pada Mac 2026. Ia menyokong input teks, imej, audio dan video, boleh menggunakan sehingga 9 imej, 3 klip video dan 3 klip audio sebagai rujukan, dan direka untuk kawalan bertaraf pengarah, kestabilan gerakan, serta penjanaan audio-video bersama. Dalam papan pendahulu undian buta semasa oleh Artificial Analysis, Seedance 2.0 mendahului kedua-dua kategori teks-ke-video dan imej-ke-video tanpa audio, masing-masing dengan skor Elo 1269 dan 1351.
Apakah Seedance 2.0?
Seedance 2.0 ialah model penciptaan video generasi baharu daripada ByteDance Seed. Secara rasmi, ia dibina berasaskan seni bina penjanaan bersama audio-video multimodal bersatu yang menerima input teks, imej, audio dan video, dan diposisikan sebagai alat pencipta dengan keupayaan rujukan dan penyuntingan yang luar biasa luas. Seedance 2.0 direka untuk aliran kerja kandungan bertaraf industri, dengan ketepatan fizikal, realisme, kebolehkawalan dan kestabilan yang lebih kukuh dalam adegan gerakan kompleks berbanding keluaran 1.5 sebelumnya. Tidak seperti model terdahulu yang tertumpu terutamanya pada teks-ke-video, Seedance 2.0 memperkenalkan saluran penjanaan multimodal bersatu sepenuhnya, yang membolehkan:
- Penjanaan teks-ke-video
- Animasi imej-ke-video
- Penyuntingan video-ke-video
- Output yang diselaraskan dengan audio
Ini menjadikannya salah satu platform penciptaan video AI paling komprehensif yang tersedia pada tahun 2026.
Mengapa ini penting?
Kebanyakan penjana video masih dioptimumkan untuk aliran kerja yang agak sempit: masukkan prompt, keluarkan klip. Seedance 2.0 melangkah lebih jauh dengan memperlakukan penjanaan video lebih seperti ruang kerja seorang pengarah. Menurut ByteDance, ia boleh menggunakan pelbagai jenis rujukan serentak, mengekalkan konsistensi subjek, mengikuti arahan terperinci dengan lebih setia, dan malah merancang bahasa kamera dengan cara yang lebih “berarahkan pengarah”. Gabungan itu penting kerana masalah paling sukar dalam penjanaan video bukan sekadar estetika, tetapi kesinambungan, koheren gerakan, dan kawalan terhadap apa yang berlaku sepanjang masa.
Apakah yang baharu dan Ciri Utama dalam Seedance 2.0?
Penjanaan multimodal bersatu
Ciri yang paling penting ialah keupayaan model untuk membuat penaakulan bersama merentas beberapa modaliti. Seedance 2.0 menyokong sehingga 9 imej, 3 video dan 3 klip audio sebagai rujukan, bersama arahan bahasa semula jadi, dan boleh menjana video sehingga 15 saat panjang. Secara praktikal, ini bermakna anda boleh membimbing bukan sahaja subjek dan adegan, tetapi juga gaya gerakan, pergerakan kamera, kesan khas dan petunjuk audio dalam satu laluan penjanaan.
Kawalan bertaraf pengarah
Seedance 2.0 juga dibina berasaskan apa yang ByteDance gambarkan sebagai kawalan bertaraf pengarah. Pencipta boleh membentuk persembahan, pencahayaan, bayang-bayang dan pergerakan kamera menggunakan imej rujukan, audio dan video. Model ini boleh mengekalkan identiti subjek yang stabil, menghasilkan semula skrip kompleks dengan tepat, dan memilih bahasa kamera dengan cara yang mencerminkan sejenis “logik penyuntingan” terbina dalam. Bagi pencipta, ini merupakan satu langkah besar melangkaui teks-ke-video asas.
Penyuntingan dan lanjutan, bukan sekadar penjanaan
Satu lagi peningkatan ketara ialah Seedance 2.0 tidak terhenti pada penjanaan. Seedance 2.0 menambah keupayaan penyuntingan video dan lanjutan video, membolehkan perubahan yang disasarkan pada adegan, watak, tindakan atau titik plot tertentu, serta membolehkan syot susulan berterusan. Artikel pembangun juga menjelaskan bahawa model ini boleh digunakan untuk “meneruskan penggambaran” dengan melanjutkan klip dan bukannya bermula semula. Ini penting untuk kecekapan aliran kerja, kerana ia mengurangkan keperluan untuk menjana semula keseluruhan adegan hanya untuk membetulkan satu segmen.
Pengendalian gerakan kompleks yang lebih baik
Seedance 2.0 jauh lebih kukuh dalam adegan dengan pelbagai subjek, interaksi dan gerakan yang rumit. Kualiti penjanaan telah meningkat dengan ketara berbanding versi 1.5, dengan ketepatan fizikal, realisme dan kebolehkawalan yang lebih baik. Kadar kebolehgunaan Seedance 2.0 dalam adegan gerakan sukar mencapai tahap SOTA industri dalam rangka penilaian dalamannya, sambil turut mengakui bahawa penambahbaikan lanjut masih diperlukan dalam kestabilan perincian halus, realisme dan kejelasan visual.
Penanda Aras Prestasi
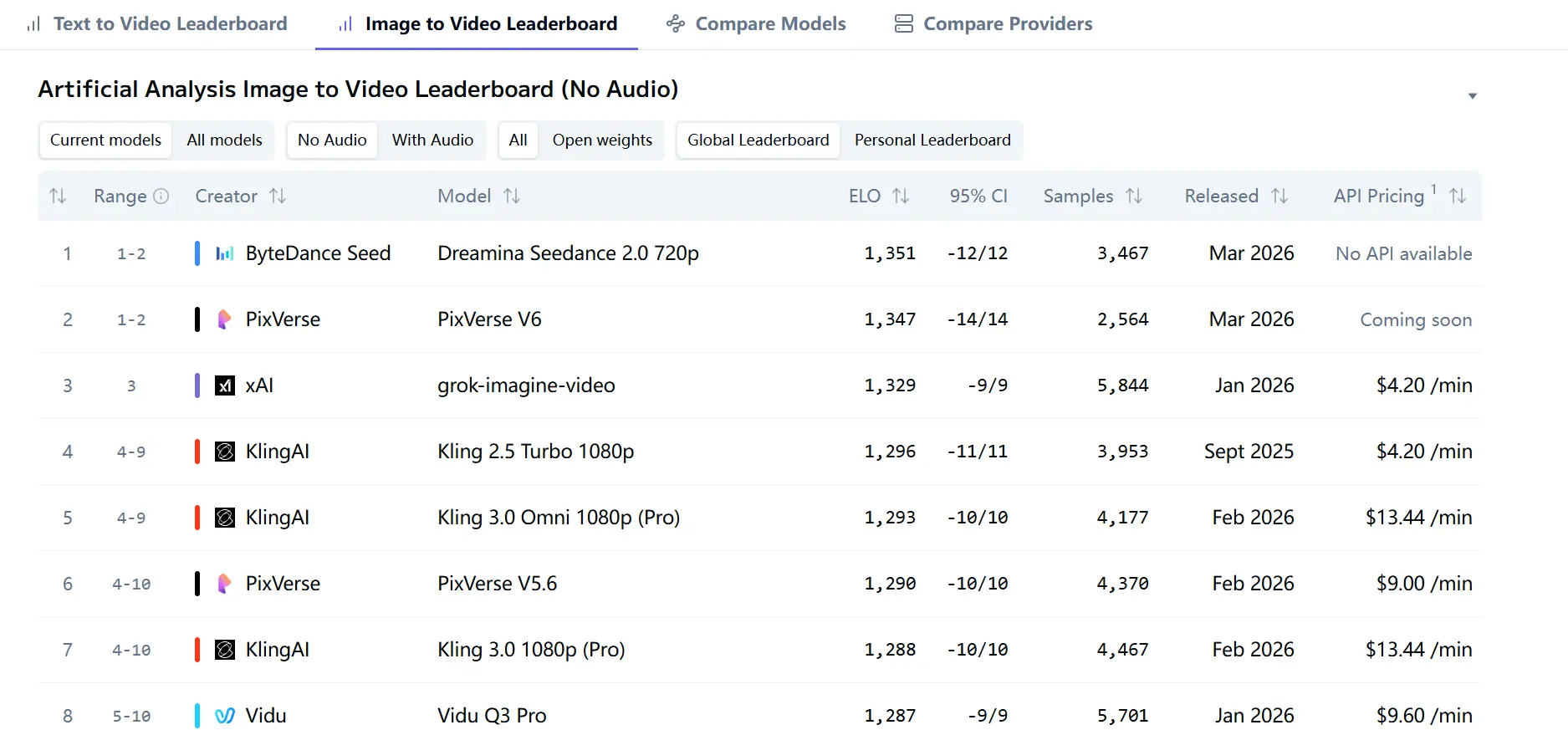
Isyarat pihak ketiga yang paling kukuh dalam sumber yang diteliti ialah Artificial Analysis Video Arena. Pada halaman papan pendahulu semasa, Dreamina Seedance 2.0 720p mendahului Image-to-Video Arena without audio dengan Elo 1351, dan Text-to-Video Arena without audio dengan Elo 1269. Halaman papan pendahulu itu juga menyatakan bahawa kedudukan datang daripada undian pengguna secara buta, yang penting kerana ia mengukur keutamaan manusia pada skala besar dan bukannya hanya metrik dalaman model.
Ini penting kerana ia bermaksud Seedance 2.0 bukan sahaja dipasarkan sebagai berkeupayaan; ia kini benar-benar lebih digemari oleh pengguna dalam ujian perbandingan satu lawan satu di dua arena utama. Dalam teks-ke-video tanpa audio, ia mendahului Kling 3.0 1080p (Pro), SkyReels V4, PixVerse V6, dan Kling 3.0 Omni 1080p (Pro). Dalam imej-ke-video tanpa audio, ia mendahului PixVerse V6 dan grok-imagine-video dengan kelebihan tipis.

Gambaran Prestasi Seedance 2.0
| Metric | Seedance 2.0 |
|---|---|
| Image-to-Video Rank | Top 15 globally |
| ELO Score | ~1258 |
| Text-to-Video Rank | Top 25 |
| Cost | ~$1.56/min |
| Strength | Cost-performance balance |
👉 Tafsiran:
- Bukan sentiasa #1 dari segi kualiti mentah
- Tetapi nisbah nilai kepada prestasi yang luar biasa
Sejauh mana bagusnya Seedance 2.0, sebenarnya?
Kekuatan terbesarnya
Kekuatan terbesar Seedance 2.0 jelas: ia mengendalikan gerakan kompleks dengan lebih baik daripada banyak model video lain, ia menyokong pelbagai modaliti rujukan, ia menawarkan penyuntingan dan lanjutan, dan ia kini mendahului ranking arena awam paling ketara dalam teks-ke-video dan imej-ke-video tanpa audio. Penambahbaikan dalam ketepatan fizikal, realisme dan kebolehkawalan ialah atribut yang tepat-benar penting apabila sesuatu model beralih daripada demo mainan kepada aliran kerja profesional.
Keterbatasan semasanya
Seedance tidak dipersembahkan oleh ByteDance sebagai sempurna. Masih ada ruang untuk menambah baik kestabilan perincian, realisme dan kejelasan gerakan, dan ia juga menyatakan cabaran yang masih berbaki dalam konsistensi berbilang subjek, ketepatan pemaparan teks, dan kesan penyuntingan yang kompleks.
Penilaian saya
Berdasarkan sumber yang diteliti, Seedance 2.0 kelihatan kurang seperti kemas kini kecil dan lebih seperti langkah serius ke arah sistem video yang sedia untuk pengeluaran. Kelebihan terbesarnya bukan satu demo mencolok tunggal, tetapi gabungan himpunan input multimodal yang lebih luas, kawalan penyuntingan langsung, lanjutan klip, dan kepimpinan papan pendahulu awam yang boleh dipercayai. Ini menjadikannya salah satu model video paling penting di pasaran pada masa ini, terutamanya bagi pasukan yang mengambil berat tentang kebolehkawalan sama seperti kualiti sinematik mentah.
Seedance 2.0 vs Sora 2 vs Veo 3.1
Jadual Perbandingan (Peneraju Video AI 2026)
| Feature | Seedance 2.0 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Developer | ByteDance | OpenAI | |
| Input Types | Text, image, audio, video | Text | Text + image |
| Audio Generation | ✅ Native | ❌ Limited | ✅ |
| Max Video Length | 15–20 sec | ~25 sec | ~8 sec (extendable) |
| Editing Capability | ⭐ Advanced (reference-based) | Moderate | Moderate |
| ELO Ranking | Top 15–25 | High | High |
| Cost Efficiency | ⭐ High | Medium | Medium |
| Commercial Use | Yes | Limited (watermark) | Yes |
| Unique Strength | Multimodal editing | Long storytelling | Visual fidelity |
Rumusan Utama
- Seedance 2.0 = terbaik untuk penyuntingan + fleksibiliti multimodal
- Sora 2 = terbaik untuk panjang naratif
- Veo 3.1 = terbaik untuk kesetiaan imej-ke-video
Pada ranking teks-ke-video semasa oleh Artificial Analysis, Seedance 2.0 720p berada di hadapan kedua-dua Veo 3.1 dan Sora 2 Pro dalam kategori tanpa audio. Ini tidak menamatkan setiap perdebatan tentang kualiti, kerana model-model ini berbeza dari segi aliran kerja, kekangan keselamatan dan pembungkusan produk, tetapi ia menunjukkan bahawa Seedance 2.0 telah bergerak ke dalam kelompok tertinggi yang sama dengan tawaran Barat yang paling menonjol.
Kelebihan paling jelas Seedance 2.0 ialah keluasan input. ByteDance menyatakan ia boleh memproses teks, imej, audio dan video secara bersama, dan boleh menggunakan sebanyak 9 imej, 3 video dan 3 klip audio serentak. Dokumentasi Sora 2 milik OpenAI, sebaliknya, menyenaraikan teks dan imej sebagai input serta video dan audio sebagai output, dengan akses melalui aplikasi Sora dan sora.com; Sora 2 Pro juga tersedia kepada pengguna ChatGPT Pro di web. Veo 3.1 milik Google berada di antara kedua-duanya: ia dibina berasaskan penciptaan berpandukan imej dan penjanaan video kaya audio, dengan sehingga 3 imej rujukan, lanjutan adegan, dan kawalan bingkai pertama dan terakhir.
Cara mengakses dan tempat membuat perbandingan
Jika anda ingin mengakses Sora 2, Veo 3.1, dan xx secara serentak pada satu platform, saya mengesyorkan CometAPI. Playgoud CometAPI menyediakan penjanaan video secara langsung hanya dengan arahan mudah atau beberapa imej rujukan. Jika anda mahu mengkonfigurasi API penjanaan video anda sendiri secara berprogram, maka CometAPI lebih wajar dipertimbangkan. Ia menyediakan API untuk Sora 2, Veo 3.1, dan sebagainya, dan kini ditawarkan pada harga diskaun 20%.
Cara Menggunakan Seedance 2.0 dengan CometAPI
Penjanaan Teks-ke-Video
Taipkan penerangan tentang adegan anda. Lebih spesifik, lebih baik — sertakan pergerakan kamera, pencahayaan, suasana dan gaya. Pematuhan prompt yang kuat oleh Seedance 2.0 bermaksud output sangat hampir dengan niat anda, menjadikannya boleh dipercayai untuk pengeluaran kandungan dan bukannya cuba-jaya.
Dalam CometAPI Playground, anda boleh terus memasukkan prompt dan menjana video menggunakan model Seedance 2.0. Ini amat berguna untuk kandungan media sosial (Reels, TikTok, YouTube Shorts), video jenama, dan klip naratif pendek.
Cara ia berfungsi:
- Buka CometAPI
- Pilih model Seedance 2.0
- Masukkan prompt anda
- Laraskan parameter (tempoh, resolusi, nisbah aspek)
- Jalankan tugas penjanaan dan tunggu output
Imej-ke-Video dengan CometAPI
Muat naik imej statik — seperti foto produk, ilustrasi konsep atau mockup reka bentuk — dan gunakan keupayaan imej-ke-video Seedance 2.0 melalui CometAPI untuk menghidupkannya.
Hasilnya ialah gerakan lancar yang peka konteks dan dijana daripada input visual anda. Ini sesuai untuk pasukan yang sudah mempunyai aset reka bentuk dan ingin menukarkannya kepada video tanpa aliran kerja pengeluaran penuh.
Cara ia berfungsi:
- Gunakan
input_reference(atau medan muat naik fail yang setara dalam Playground) - Tambahkan prompt berfokuskan gerakan yang menerangkan bagaimana adegan sepatutnya bergerak
Contoh prompt:
“Kamera perlahan-lahan mendekati produk, pencahayaan studio lembut, pantulan halus, rasa komersial premium”
Penjanaan Audio-Visual dalam Satu Laluan
Daripada menjana video terlebih dahulu dan kemudian menambah audio secara berasingan, CometAPI menyokong saluran penjanaan audio-visual natif Seedance 2.0.
Dengan menerangkan visual dan bunyi dalam satu prompt, anda boleh menjana video dan audio yang disegerakkan dalam satu langkah. Ini menghasilkan keputusan yang lebih padu dan disengajakan, sambil turut mengurangkan masa penyuntingan.
Contoh prompt:
“Pantai yang damai ketika matahari terbit, ombak lembut menghempas, cahaya keemasan hangat, muzik ambien lembut dengan bunyi lautan”
Output termasuk:
- Video yang dijana
- Audio latar yang disegerakkan
- Masa dan suasana yang sejajar secara semula jadi
Mengapa Menggunakan CometAPI untuk Seedance 2.0
- Akses terus melalui API atau Playground
- Kawalan parameter yang mudah (tempoh, resolusi, format)
- Menyokong kedua-dua aliran kerja teks-ke-video dan imej-ke-video
- Pengendalian tugas terbina dalam untuk penjanaan video tak segerak
Kesimpulan
Seedance 2.0 kelihatan seperti lonjakan sebenar dalam penjanaan video AI: sistem multimodal yang menggabungkan input teks, imej, audio dan video; peneraju papan pendahulu dalam kedua-dua teks-ke-video dan imej-ke-video; serta model yang dibina untuk kawalan gaya pengarah dan bukannya penggunaan kasual seperti mainan. Jika anda hanya mementingkan kualiti persepsi mentah, bukti semasa menunjukkan bahawa ia benar-benar luar biasa.
Mulakan mencipta dengan Seedance 2.0 di CometAPI hari ini.