

Dalam landskap yang didominasi oleh falsafah "skala pada apa jua kos"—di mana model seperti Flux.2 dan Hunyuan-Image-3.0 menolak kiraan parameter ke julat besar 30B hingga 80B—pesaing baharu telah muncul untuk mengganggu status quo. Z-Image, dibangunkan oleh Tongyi Lab milik Alibaba, telah dilancarkan secara rasmi, memecahkan jangkaan dengan seni bina 6 bilion parameter yang ringkas namun menyaingi kualiti hasil gergasi industri sambil berjalan pada perkakasan pengguna.
Dilancarkan pada akhir 2025, Z-Image (dan variannya yang sangat pantas Z-Image-Turbo) serta-merta memikat komuniti AI, melepasi 500,000 muat turun dalam masa 24 jam selepas debutnya. Dengan menghasilkan imej fotorealistik hanya dalam 8 langkah inferens, Z-Image bukan sekadar satu lagi model; ia adalah daya pendemokrasian dalam AI generatif, membolehkan penciptaan fideliti tinggi pada komputer riba yang akan "tersedak" dengan pesaingnya.
Apa itu Z-Image?
Z-Image ialah model asas penjanaan imej sumber terbuka baharu yang dibangunkan oleh pasukan penyelidikan Tongyi-MAI / Alibaba Tongyi Lab. Ia adalah model generatif berparameter 6 bilion yang dibina di atas seni bina baharu Scalable Single-Stream Diffusion Transformer (S3-DiT) yang menggabungkan token teks, token semantik visual dan token VAE ke dalam satu aliran pemprosesan. Matlamat reka bentuknya jelas: menyampaikan fotorealisme bertaraf tertinggi serta pematuhan arahan sambil mengurangkan kos inferens secara drastik dan membolehkan penggunaan praktikal pada perkakasan pengguna. Projek Z-Image menerbitkan kod, berat model dan demo dalam talian di bawah lesen Apache-2.0.
Z-Image hadir dalam pelbagai varian. Keluaran yang paling banyak diperkatakan ialah Z-Image-Turbo — versi sulingan beberapa langkah yang dioptimumkan untuk pengeluaran — serta Z-Image-Base yang tidak disuling (titik semak asas, lebih sesuai untuk penalaan halus) dan Z-Image-Edit (ditala arahan untuk penyuntingan imej).
Kelebihan "Turbo": Inferens 8 Langkah
Varian utama, Z-Image-Turbo, menggunakan teknik distilasi progresif yang dikenali sebagai Decoupled-DMD (Distribution Matching Distillation). Ini membolehkan model memampatkan proses penjanaan daripada standard 30-50 langkah kepada hanya 8 langkah.
Hasil: Masa penjanaan sub-saat pada GPU perusahaan (H800) dan prestasi hampir masa nyata pada kad pengguna (RTX 4090), tanpa rupa "plastik" atau "pudar" yang lazim pada model turbo/lightning lain.
4 Ciri Utama Z-Image
Z-Image sarat dengan ciri yang memenuhi keperluan pembangun teknikal dan profesional kreatif.
1. Fotorealisme & Estetika Tiada Tandingan
Walaupun hanya mempunyai 6 bilion parameter, Z-Image menghasilkan imej dengan kejelasan yang menakjubkan. Ia unggul dalam:
- Tekstur Kulit: Mereplikasi liang, ketidaksempurnaan dan pencahayaan semula jadi pada subjek manusia.
- Fizik Bahan: Memaparkan tekstur kaca, logam dan fabrik dengan tepat.
- Pencahayaan: Pengendalian pencahayaan sinematik dan volumetrik yang lebih unggul berbanding SDXL.
2. Pemaparan Teks Dwibahasa Natif
Salah satu titik kesakitan terbesar dalam penjanaan imej AI ialah pemaparan teks. Z-Image menyelesaikannya dengan sokongan natif untuk bahasa Inggeris dan Cina.
- Ia boleh menjana poster, logo dan papan tanda yang kompleks dengan ejaan dan kaligrafi yang betul dalam kedua-dua bahasa, ciri yang sering tiada pada model berfokus Barat.
3. Z-Image-Edit: Penyuntingan Berasaskan Arahan
Seiring dengan model asas, pasukan turut mengeluarkan Z-Image-Edit. Varian ini ditala khusus untuk tugas imej-ke-imej, membolehkan pengguna mengubah suai imej sedia ada menggunakan arahan bahasa semula jadi (cth., "Buat orang itu tersenyum," "Tukar latar belakang kepada gunung bersalji"). Ia mengekalkan konsistensi identiti dan pencahayaan yang tinggi semasa transformasi ini.
4. Kebolehaksesan Perkakasan Pengguna
- Kecekapan VRAM: Berjalan dengan selesa pada 6GB VRAM (dengan pengkuantuman) hingga 16GB VRAM (ketepatan penuh).
- Pelaksanaan Tempatan: Menyokong penyebaran tempatan sepenuhnya melalui ComfyUI dan
diffusers, membebaskan pengguna daripada pergantungan awan.
Bagaimana Z-Image Berfungsi?
Transformer difusi aliran tunggal (S3-DiT)
Z-Image menyimpang daripada reka bentuk aliran berkembar klasik (pengekod/stream teks dan imej berasingan) dan sebaliknya menggabungkan token teks, token VAE imej dan token semantik visual ke dalam satu input transformer. Pendekatan aliran tunggal ini memperbaiki penggunaan parameter dan memudahkan penjajaran rentas modal di dalam tulang belakang transformer, yang menurut pengarang menghasilkan pertukaran kecekapan/kualiti yang menguntungkan untuk model 6B.
Decoupled-DMD dan DMDR (distilasi + RL)
Untuk membolehkan penjanaan beberapa langkah (8 langkah) tanpa penalti kualiti biasa, pasukan membangunkan pendekatan distilasi Decoupled-DMD. Teknik ini memisahkan penguatan CFG (classifier-free guidance) daripada pemadanan taburan, membolehkan setiap satu dioptimumkan secara bebas. Mereka kemudian menggunakan langkah pembelajaran peneguhan selepas latihan (DMDR) untuk memperhalus penjajaran semantik dan estetika. Bersama-sama, ini menghasilkan Z-Image-Turbo dengan NFE yang jauh lebih sedikit daripada model difusi tipikal sambil mengekalkan realisme tinggi.
Throughput latihan dan pengoptimuman kos
Z-Image dilatih dengan pendekatan pengoptimuman kitar hayat: saluran data terkurasi, kurikulum yang diperkemas, dan pilihan pelaksanaan yang peka terhadap kecekapan. Pengarang melaporkan menyiapkan keseluruhan aliran kerja latihan dalam kira-kira 314K jam GPU H800 (≈ USD $630K) — metrik kejuruteraan yang eksplisit dan boleh diulang yang memposisikan model sebagai kos efektif berbanding alternatif yang sangat besar (>20B).
Keputusan Penanda Aras Model Z-Image
Z-Image-Turbo berada di kedudukan tinggi pada beberapa papan pendahulu kontemporari, termasuk kedudukan sumber terbuka teratas pada papan pendahulu Artificial Analysis Text-to-Image dan prestasi kukuh pada penilaian keutamaan manusia Alibaba AI Arena.
Namun kualiti dunia nyata juga bergantung pada pembentukan prompt, resolusi, paip pembesaran, dan pasca-pemprosesan tambahan.
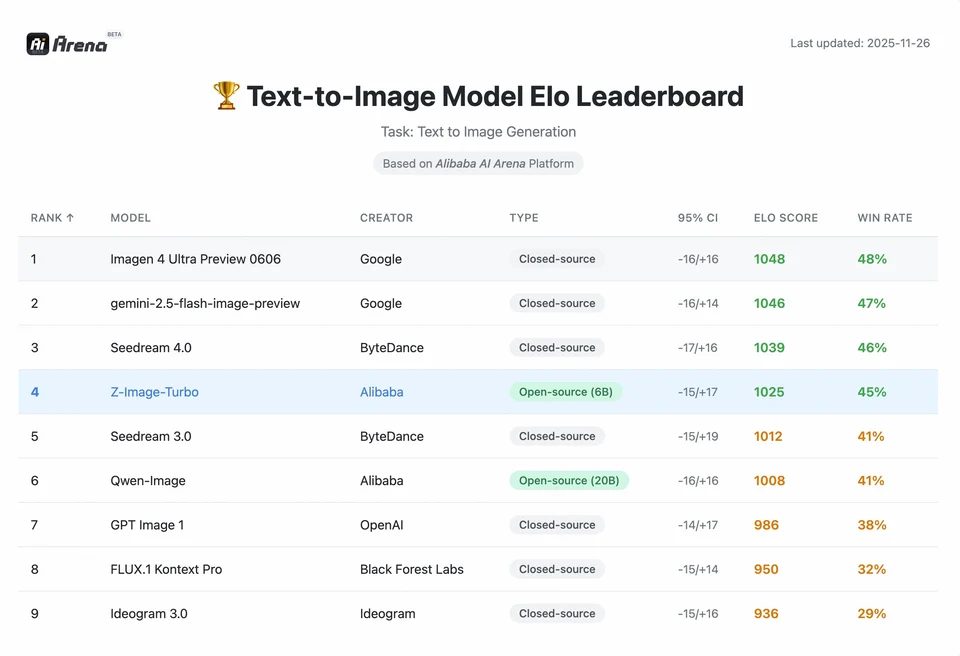
Untuk memahami magnitud pencapaian Z-Image, kita perlu melihat data. Di bawah ialah analisis perbandingan Z-Image berbanding model sumber terbuka dan proprietari terkemuka.
Ringkasan Penanda Aras Perbandingan
| Ciri / Metrik | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Seni bina | S3-DiT (Aliran Tunggal) | MM-DiT (Aliran Berkembar) | U-Net | Transformer Difusi |
| Parameter | 6 Bilion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Langkah Inferens | 8 Langkah | 25 - 50 Langkah | 1 - 4 Langkah | 30 - 50 Langkah |
| VRAM Diperlukan | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Pemaparan Teks | Tinggi (EN + CN) | Tinggi (EN) | Sederhana (EN) | Tinggi (CN + EN) |
| Kelajuan Penjanaan (4090) | ~1.5 - 3.0 Saat | ~15 - 30 Saat | ~0.5 Saat | ~20 Saat |
| Skor Fotorealisme | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| Lesen | Apache 2.0 | Bukan Komersial (Dev) | OpenRAIL | Tersuai |
Analisis Data & Wawasan Prestasi
- Kelajuan vs. Kualiti: Walaupun SDXL Turbo lebih pantas (1 langkah), kualitinya merosot dengan ketara pada prompt kompleks. Z-Image-Turbo mencapai "titik manis" pada 8 langkah, menyamai kualiti Flux.2 sambil 5x hingga 10x lebih pantas.
- Pendemokrasian Perkakasan: Flux.2, walaupun berkuasa, secara efektif dikunci di belakang kad 24GB VRAM (RTX 3090/4090) untuk prestasi yang munasabah. Z-Image membolehkan pengguna dengan kad pertengahan (RTX 3060/4060) menjana imej bertaraf profesional 1024x1024 secara tempatan.
Bagaimanakah pembangun boleh mengakses dan menggunakan Z-Image?
Terdapat tiga pendekatan tipikal:
- Hosted / SaaS (UI web atau API): Gunakan perkhidmatan seperti z-image.ai atau penyedia lain yang menyebarkan model dan mendedahkan antara muka web atau API berbayar untuk penjanaan imej. Ini ialah laluan terpantas untuk eksperimen tanpa persediaan tempatan.
- Hugging Face + paip diffusers: Pustaka Hugging Face
diffusersmenyertakanZImagePipelinedanZImageImg2ImgPipelineserta menyediakan aliran kerja biasafrom_pretrained(...).to("cuda"). Ini ialah laluan yang disyorkan untuk pembangun Python yang mahukan integrasi terus dan contoh boleh diulang. - Inferens natif tempatan daripada repo GitHub: Repo Tongyi-MAI menyertakan skrip inferens natif, pilihan pengoptimuman (FlashAttention, kompilasi, offload CPU), dan arahan untuk memasang
diffusersdaripada sumber untuk integrasi terkini. Laluan ini berguna untuk penyelidik dan pasukan yang mahukan kawalan penuh atau menjalankan latihan/penalaan halus tersuai.
Bagaimanakah rupa contoh Python yang minimal?
Di bawah ialah petikan Python ringkas menggunakan Hugging Face diffusers yang menunjukkan penjanaan teks-ke-imej dengan Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Guna bfloat16 di mana disokong untuk kecekapan pada GPU moden pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Disimpan: {output_path}")if __name__ == "__main__": generate("Potret sinematik seorang pelukis robot, pencahayaan studio, sangat terperinci")
Nota:guidance_scale lalai dan tetapan yang disyorkan berbeza untuk model Turbo; dokumentasi mencadangkan panduan boleh ditetapkan rendah atau sifar untuk Turbo bergantung pada tingkah laku yang disasarkan.
Bagaimana menjalankan imej-ke-imej (edit) dengan Z-Image?
ZImageImg2ImgPipeline menyokong penyuntingan imej. Contoh:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Ubah lakaran ini menjadi lembah sungai fantasi dengan warna yang terang"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Ini mencerminkan corak penggunaan rasmi dan sesuai untuk tugas penyuntingan kreatif dan inpainting.
Bagaimana anda harus mendekati prompt dan panduan?
- Jelas dengan struktur: Untuk adegan kompleks, strukturkan prompt untuk memasukkan komposisi adegan, objek fokus, kamera/lensa, pencahayaan, suasana, dan sebarang elemen teks. Z-Image mendapat manfaat daripada prompt terperinci dan boleh mengendalikan petunjuk kedudukan / naratif dengan baik.
- Laraskan
guidance_scaledengan teliti: Model Turbo mungkin mengesyorkan nilai panduan yang lebih rendah; eksperimen adalah perlu. Untuk banyak aliran kerja Turbo,guidance_scale=0.0–1.0dengan seed dan langkah tetap menghasilkan keputusan yang konsisten. - Gunakan imej-ke-imej untuk edit terkawal: Apabila anda perlu mengekalkan komposisi tetapi menukar gaya/pewarnaan/objek, mulakan daripada imej awal dan gunakan strength untuk mengawal magnitud perubahan.
Kes Penggunaan Terbaik dan Amalan Terbaik
1. Prototip Pantas & Papan Cerita
Kes Penggunaan: Pengarah filem dan pereka permainan perlu memvisualisasikan adegan serta-merta.
Mengapa Z-Image? Dengan penjanaan di bawah 3 saat, pencipta boleh mengulangi ratusan konsep dalam satu sesi, memperhaluskan pencahayaan dan komposisi secara masa nyata tanpa menunggu minit untuk render.
2. E-Dagang & Pengiklanan
Kes Penggunaan: Menjana latar belakang produk atau foto gaya hidup untuk barangan.
Amalan Terbaik: Gunakan Z-Image-Edit.
Muat naik foto produk mentah dan gunakan prompt arahan seperti "Letakkan botol minyak wangi ini di atas meja kayu dalam taman yang disinari matahari." Model mengekalkan integriti produk sambil "berhalusinasi" latar belakang fotorealistik.
3. Penciptaan Kandungan Dwibahasa
Kes Penggunaan: Kempen pemasaran global yang memerlukan aset untuk pasaran Barat dan Asia.
Amalan Terbaik: Manfaatkan keupayaan pemaparan teks.
- Prompt: "Tanda neon yang bertulis 'OPEN' dan '营业中' bersinar dalam lorong gelap."
- Z-Image akan memaparkan kedua-dua aksara Inggeris dan Cina dengan betul, pencapaian yang kebanyakan model lain gagal lakukan.
4. Persekitaran Sumber Rendah
Kes Penggunaan: Menjalankan penjanaan AI pada peranti edge atau komputer riba pejabat biasa.
Petua Pengoptimuman: Gunakan versi INT8 yang dikuantumkan bagi Z-Image. Ini mengurangkan penggunaan VRAM kepada bawah 6GB dengan kehilangan kualiti yang boleh diabaikan, menjadikannya boleh dilaksanakan untuk aplikasi tempatan pada komputer riba bukan gaming.
Kesimpulan: siapa yang patut menggunakan Z-Image?
Z-Image direka untuk organisasi dan pembangun yang mahukan fotorealisme berkualiti tinggi dengan latensi dan kos praktikal, dan yang lebih menggemari lesen terbuka serta hos di premis atau hos tersuai. Ia amat menarik bagi pasukan yang memerlukan iterasi pantas (alat kreatif, lakaran produk, perkhidmatan masa nyata) dan kepada penyelidik/komuniti yang berminat menala halus model imej yang kompak tetapi berkuasa.
CometAPI menawarkan model Grok Image yang serupa kurang terhad, serta model seperti Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) dan lain-lain—dengan syarat anda mempunyai tip dan helah NSFW yang tepat untuk memintas sekatan dan mula mencipta dengan bebas. Sebelum mengakses, pastikan anda telah log masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda mengintegrasi.
Sedia untuk bermula?→ Percubaan percuma untuk Mencipta !