

In juli 2025 onthulde Alibaba Qwen3-codeerder, het meest geavanceerde open-source AI-model, speciaal ontworpen voor complexe codeerworkflows en agentische programmeertaken. Deze professionele gids leidt je stap voor stap door alles wat je moet weten – van het begrijpen van de kernmogelijkheden en belangrijkste innovaties tot het installeren en gebruiken van de bijbehorende Qwen-code CLI-tool voor geautomatiseerde agent-stijl codering. Onderweg leert u best practices, tips voor probleemoplossing en hoe u uw prompts en resourcetoewijzing kunt optimaliseren om Qwen3-Coder optimaal te benutten.
Wat is Qwen3‑Coder en waarom is het belangrijk?
Alibaba's Qwen3-Coder is een Mixture-of-Experts (MoE)-model met 480 miljard parameters en 35 miljard actieve parameters, ontwikkeld ter ondersteuning van grootschalige codeertaken. Het verwerkt native 256 tokens (en tot 1 miljoen met extrapolatiemethoden). Het werd uitgebracht op 23 juli 2025 en vertegenwoordigt een grote sprong voorwaarts in "agentische AI-codering", waarbij het model niet alleen code genereert, maar ook autonoom complexe programmeeruitdagingen kan plannen, debuggen en itereren zonder handmatige tussenkomst.
Hoe verschilt Qwen3‑Coder van zijn voorgangers?
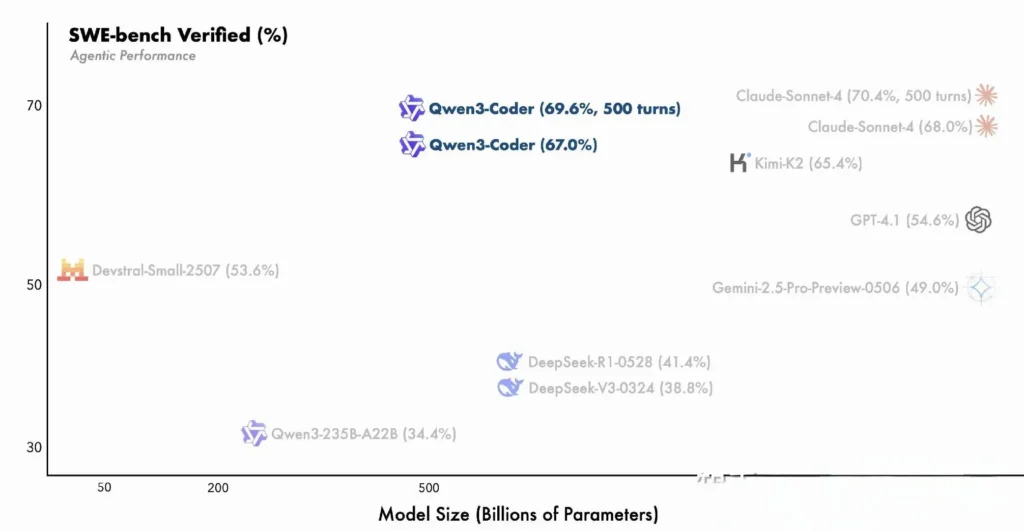
Qwen3-Coder bouwt voort op de innovaties van de Qwen3-familie en integreert zowel de "denkmodus" voor redeneren in meerdere stappen als de "niet-denkmodus" voor snelle reacties in één uniform framework dat dynamisch van modus wisselt op basis van de complexiteit van de taak. In tegenstelling tot Qwen2.5-Coder, dat compact was en beperkt tot kleinere contexten, maakt Qwen3-Coder gebruik van een spaarzame Mixture-of-Experts-architectuur om state-of-the-art prestaties te leveren in benchmarks zoals SWE-Bench Verified en CodeForces ELO-ratings. Hiermee worden modellen zoals Claude van Anthropic en GPT-4 van OpenAI geëvenaard of overtroffen in belangrijke codeerparameters.
Belangrijkste kenmerken van Qwen3‑Coder:
- Enorm contextvenster: 256K tokens standaard, tot 1M via extrapolatie, waardoor volledige codebases of lange documentatie in één keer verwerkt kunnen worden.
- Agentische mogelijkheden: Een speciale 'agentmodus' die autonoom code kan plannen, genereren, testen en debuggen, waardoor de handmatige engineering-overhead wordt verminderd.
- Hoge doorvoer en efficiëntie: Het Mixture-of-Experts-ontwerp activeert slechts 35 miljard parameters per inferentie, waardoor prestaties en rekenkosten in evenwicht worden gebracht.
- Open-source en uitbreidbaar: Uitgebracht onder Apache 2.0, met volledig gedocumenteerde API's en door de community aangestuurde verbeteringen beschikbaar op GitHub.
- Meertalig en domeinoverschrijdend: Getraind op 7.5 biljoen tokens (70% code) in tientallen programmeertalen, van Python en JavaScript tot Go en Rust.
Hoe kunnen ontwikkelaars aan de slag met Qwen3‑Coder?
Waar kan ik Qwen3‑Coder downloaden en installeren?
U kunt de modelgewichten en Docker-images verkrijgen via:
- GitHub: https://github.com/QwenLM/Qwen3-Coder
- Knuffelend gezicht: https://huggingface.co/QwenLM/Qwen3-Coder-480B-A35B-Instruct
- ModelScope: Officiële Alibaba-repository
Kloon de repository en haal de vooraf gebouwde Docker-container op:
git clone https://github.com/QwenLM/Qwen3-Coder.git
cd Qwen3-Coder
docker pull qwenlm/qwen3-coder:latest
Het model laden met transformatoren
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-480B-A35B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Deze code initialiseert het model en de tokenizer en verdeelt de lagen automatisch over de beschikbare GPU's.
Hoe configureer ik mijn omgeving?
- Hardwarevereisten:
- NVIDIA GPU's met ≥ 48 GB VRAM (A100 80 GB aanbevolen)
- 128–256 GB systeem-RAM
-
Bijgebouwen:
pip install -r requirements.txt # PyTorch, CUDA, tokenizers, etc. -
API-sleutels (optioneel):
Voor in de cloud gehoste inferentie stelt u uwALIYUN_ACCESS_KEYenALIYUN_SECRET_KEYals omgevingsvariabelen.
Hoe gebruik je Qwen Code voor agentische codering?
Hier is een stapsgewijze handleiding om aan de slag te gaan met Qwen3‑Coder via de Qwen-code CLI (eenvoudigweg aangeroepen als qwen):
1. voorwaarden
- Node.js 20+ (u kunt installeren via het officiële installatieprogramma of via het onderstaande script)
- NPM, die gebundeld is met Node.js
# (Linux/macOS)
curl -qL https://www.npmjs.com/install.sh | sh
2. Installeer de Qwen Code CLI
npm install -g @qwen-code/qwen-code
Alternatief, om te installeren vanaf de bron:
git clone https://github.com/QwenLM/qwen-code.git
cd qwen-code
npm install
npm install -g
3. Configureer uw omgeving
Qwen Code maakt gebruik van de OpenAI-compatibel API-interface onder de motorkap. Stel de volgende omgevingsvariabelen in:
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
OPENAI_MODEL kan worden ingesteld op een van de volgende:
qwen3-coder-plus(alias naar Qwen3‑Coder-480B-A35B-Instruct)- of een andere Qwen3‑Coder-variant die u hebt geïmplementeerd.
4. Basisgebruik
- Start een interactieve coderings-REPL:
qwen
Hiermee kom je terecht in een agentische coderingssessie, aangestuurd door Qwen3‑Coder.
- Eenmalige prompt van Shell, om een codefragment op te vragen of een functie te voltooien:
qwen code complete \
--model qwen3-coder-plus \
--prompt "Write a Python function that reverses a linked list."
- Bestandsgebaseerde codeaanvulling: automatisch een bestaand bestand invullen of refactoren:
qwen code file-complete \
--model qwen3-coder-plus \
--file ./src/utils.js
- Chat-stijl interactie: gebruik Qwen in de chatmodus, ideaal voor dialogen met meerdere beurten:
qwen chat \
--model qwen3-coder-plus \
--system "You are a helpful coding assistant." \
--user "Generate a REST API endpoint in Express.js for user authentication."
Hoe roep je Qwen3-Coder aan via de CometAPI API?
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Als u een cometAPI-gebruiker bent, kunt u inloggen op cometapi om de sleutel en de basis-url te verkrijgen en inloggen op cometapi om de sleutel en de basis-url te verkrijgen. Raadpleeg Qwen3-Coder APIOm te beginnen, verken de mogelijkheden van modellen in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies.
Om Qwen3-Coder via CometAPI aan te roepen, gebruikt u dezelfde OpenAI-compatibele eindpunten als voor elk ander model: wijs uw client eenvoudigweg naar de basis-URL van CometAPI, presenteer uw CometAPI-sleutel als een Bearer-token en specificeer de qwen3-coder-plus or qwen3-coder-480b-a35b-instruct model.
1. voorwaarden
- Aanmelden at https://cometapi.com en voeg een API-token toe aan uw dashboard of genereer er een.
- Let op uw API sleutel (begint met
sk-…). - Kennis van het OpenAI Chat API-protocol (rollen + berichten).
2. Basis-URL en authenticatie
Basis URL:
arduinohttps://api.cometapi.com/v1
Endpoint:
bashPOST https://api.cometapi.com/v1/chat/completions
3. cURL / REST-voorbeeld
curl https://api.cometapi.com/v1/chat/completions \
-H "Authorization: Bearer sk-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-coder-plus",
"messages": [
{ "role": "system", "content": "You are a helpful coder." },
{ "role": "user", "content": "Generate a SQL query to find duplicate emails." }
],
"temperature": 0.7,
"max_tokens": 512
}'
- antwoord: JSON met
choices.message.contentdie de gegenereerde code bevat.
Hoe benut u de agentcapaciteiten van Qwen3-Coder?
De agentische functies van Qwen3-Coder maken dynamische aanroeping van tools en autonome workflows met meerdere stappen mogelijk, waardoor het model externe functies of API's kan aanroepen tijdens het genereren van code.
Gereedschapsaanroeping en aangepaste gereedschappen
Definieer aangepaste tools – zoals linters, testrunners of formatters – in je codebase en stel ze beschikbaar aan het model via functieschema's. Bijvoorbeeld:
tools = [
{"name":"run_tests","description":"Execute the test suite and return results","parameters":{}},
{"name":"format_code","description":"Apply black formatter to the code","parameters":{}}
]
response = client.chat.completions.create(
messages=,
functions=tools,
function_call="auto"
)
Qwen3-Coder kan vervolgens autonoom code genereren, formatteren en valideren in één sessie, waardoor de overhead van handmatige integratie wordt verminderd ().
Qwen Code CLI gebruiken
Het qwen-code De opdrachtregeltool biedt een interactieve REPL voor agentische codering:
qwen-code --model qwen3-coder-480b-a35b-instruct
> generate: "Create a REST API in Node.js with JWT authentication."
> tool: install_package(express)
> tool: create_file(app.js)
> tool: run_tests
Deze CLI orkestreert complexe workflows met transparante logboeken, waardoor deze ideaal is voor verkennend prototypen of integratie in CI/CD-pijplijnen.
Is Qwen3-Coder geschikt voor grote codebases?
Dankzij het uitgebreide contextvenster kan Qwen3-Coder complete repositories verwerken – tot wel honderdduizenden regels code – voordat er patches of refactorings worden gegenereerd. Deze mogelijkheid maakt globale refactorings, cross-module analyses en architectuursuggesties mogelijk die modellen met kleinere contexten simpelweg niet kunnen evenaren.
Wat zijn de beste werkwijzen om de bruikbaarheid van Qwen3-Coder te maximaliseren?
Voor een effectieve implementatie van Qwen3-Coder is een doordachte configuratie en integratie in uw CI/CD-pijplijn vereist.
Hoe moet u de sampling- en beaminstellingen afstemmen?
- Temperatuur zone(s): 0.6–0.8 voor evenwichtige creativiteit; lager (0.2–0.4) voor deterministische refactoringtaken.
- Top‑p: 0.7–0.9 om de nadruk te leggen op de meest waarschijnlijke voortzettingen en tegelijkertijd af en toe ruimte te laten voor nieuwe suggesties.
- Top-k: 20–50 voor standaardgebruik; terugbrengen tot 5–10 bij het zoeken naar zeer gerichte uitkomsten.
- Herhalingsstraf: 1.05–1.1 om te voorkomen dat het model standaardpatronen herhaalt.
Experimenteren met deze parameters in overeenstemming met de variatietolerantie van uw project kan tot aanzienlijke productiviteitswinsten leiden.
Wat zijn de beste werkwijzen voor effectief gebruik van Qwen3-Coder?
Snelle engineering voor codekwaliteit
- Wees specifiek: Geef aan welke taal, stijlrichtlijnen en gewenste complexiteit u in uw opdracht wilt gebruiken.
- Iteratieve verfijning: Gebruik de agentische mogelijkheden van het model om gegenereerde code iteratief te debuggen en optimaliseren.
- Temperatuurafstemming: Verlaag de generatietemperatuur (bijv.
temperature=0.2) voor meer deterministische uitkomsten in productiecontexten.
Het beheren van resourcegebruik
- ModelvariantenBegin met kleinere Qwen3-Coder-varianten voor prototyping en schaal vervolgens op indien nodig.
- Dynamische kwantiseringExperimenteer met FP8- en GGUF-gekwantiseerde controlepunten om de GPU-geheugenvoetafdruk te verkleinen zonder significante prestatiedaling.
- Asynchrone generatie:Besteed langlopende codegeneraties aan achtergrondwerkers om de responsiviteit te behouden.
Wanneer u zich aan deze richtlijnen houdt, maximaliseert u de ROI van de integratie van Qwen3-Coder in uw softwareontwikkelingscyclus.
Door de bovenstaande richtlijnen te volgen (de architectuur te begrijpen, zowel het model als de Qwen Code CLI te installeren en configureren en best practices te benutten), bent u goed toegerust om het volledige potentieel van Qwen3-Coder te benutten, van eenvoudige codefragmenten tot volledig autonome programmeeragents.