

Het Qwen-team van Alibaba heeft vrijgegeven Qwen3-Max-Preview (Instrueren) — het grootste model van het bedrijf tot nu toe, met meer dan 1 biljoen parameters — en maakte het direct beschikbaar via Qwen Chat, Alibaba Cloud Model Studio (API) en externe marktplaatsen zoals CometAPI. De preview richt zich op redeneren, coderen en workflows met lange documenten door extreme schaal te combineren met een zeer groot contextvenster en contextcaching om de latentie laag te houden tijdens lange sessies.
Belangrijkste technische hoogtepunten
- Enorm aantal parameters (meer dan biljoen): De overstap naar een model met meer dan een biljoen parameters is bedoeld om de capaciteit voor het leren van complexe patronen (redeneren in meerdere stappen, codesynthese en diepgaand documentbegrip) te vergroten. Vroege benchmarks van Qwen wijzen op verbeterde resultaten op het gebied van redeneren, coderen en benchmarksuites ten opzichte van eerdere topmodellen van Qwen.
- Ultralange context en caching: Het 262k-tokens Met window kunnen teams in één keer complete, lange rapporten, codebases met meerdere bestanden of lange chatgeschiedenissen invoeren. Ondersteuning voor contextcaching vermindert de herhaalde rekenkracht voor terugkerende context en kan de latentie en kosten voor langere sessies verlagen.
- Meertaligheid + programmeervaardigheden: De Qwen3-familie legt de nadruk op tweetalige (Chinees/Engels) en brede meertalige ondersteuning, plus krachtigere codering en gestructureerde uitvoerverwerking. Dit is handig voor code-assistenten, geautomatiseerde rapportgeneratie en grootschalige tekstuele analyses.
- Ontworpen voor snelheid en kwaliteit. Previewgebruikers beschrijven de "razendsnelle" reactiesnelheid en de verbeterde instructievolging en redenering in vergelijking met eerdere Qwen3-varianten. Alibaba positioneert het model als een high-throughput vlaggenschip voor productie-, agent- en ontwikkelaarsscenario's.
Beschikbaarheid en toegang
Alibaba Cloud-kosten gelaagd, token-gebaseerd Prijzen voor Qwen3-Max-Preview (aparte input- en outputtarieven). Facturering vindt plaats per miljoen tokens en wordt toegepast op het daadwerkelijk verbruikte aantal tokens na een eventueel vrij quotum.
De gepubliceerde previewprijzen (USD) van Alibaba zijn op aanvraag gestaffeld invoer tokenvolume (dezelfde niveaus bepalen welke eenheidstarieven van toepassing zijn):
- 0–32K invoertokens: $0.861 / 1M invoertokens en $3.441 / 1M outputtokens.
- 32K–128K invoertokens: $1.434 / 1M invoertokens en $5.735 / 1M outputtokens.
- 128K–252K invoertokens: $2.151 / 1M invoertokens en $8.602 / 1M outputtokens.
CometAPI biedt een officiële korting van 20% om gebruikers te helpen bij het aanroepen van de API. Details vindt u op Qwen3-Max-Preview:
| Invoertokens | $0.24 |
| Uitvoertokens | $2.42 |
Qwen3-Max breidt de Qwen3-familie uit (die in eerdere builds gebruikmaakte van hybride ontwerpen zoals Mixture-of-Experts-varianten en meerdere actieve-parameterlagen). Alibaba's eerdere Qwen3-releases richtten zich op zowel "denken" (stapsgewijze redenering) als "instructie"-modi; Qwen3-Max wordt gepositioneerd als de nieuwe, hoogwaardige instructievariant in die lijn, wat aantoont dat het het vorige best presterende product van het bedrijf, de Qwen3-235B-A22B-2507, overtreft en aantoont dat het 1T-parametermodel in een reeks tests presteert.
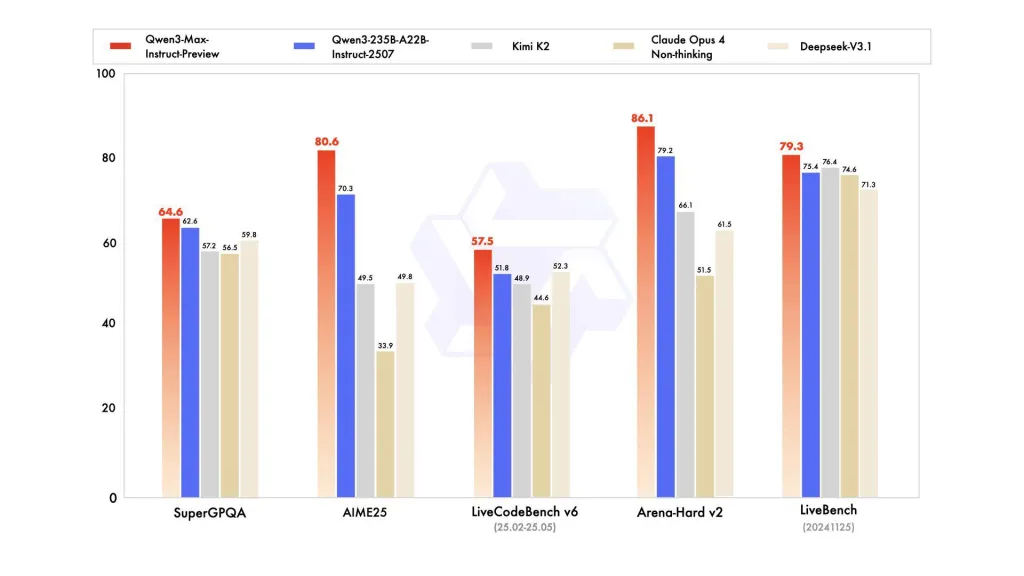
Op SuperGPQA, AIME25, LiveCodeBench v6, Arena-Hard v2 en LiveBench (20241125) scoort Qwen3-Max-Preview consequent beter dan Claude Opus 4, Kimi K2 en Deepseek-V3.1.
Hoe u Qwen3-Max kunt openen en gebruiken (praktische gids)
1) Probeer het in de browser (Qwen Chat)
Bezoek Qwen-chat (officiële Qwen web/chatinterface) en selecteer de Qwen3-Max-Preview (Instrueren) model indien weergegeven in de modelkiezer. Dit is de snelste manier om conversatie- en instructietaken visueel te evalueren.
2) Toegang via Alibaba Cloud (Model Studio / Cloud API)
- Meld u aan bij Alibaba Cloud → Model Studio / Model ServingMaak een inferentie-instantie of selecteer het gehoste model-eindpunt voor qwen3-max-preview (of de gelabelde previewversie).
- Voer verificatie uit met behulp van uw Alibaba Cloud Access Key/RAM-rollen en roep het inferentie-eindpunt aan met een POST-aanvraag met uw prompt en eventuele generatieparameters (temperatuur, maximale tokens, enz.).
3) Gebruik door externe hosts / aggregators
Volgens de berichtgeving is de preview bereikbaar via CometAPI en andere API-aggregators waarmee ontwikkelaars meerdere gehoste modellen kunnen aanroepen met één API-sleutel. Dit kan het testen van meerdere providers vereenvoudigen, maar ook de latentie, regionale beschikbaarheid en het gegevensverwerkingsbeleid voor elke host verifiëren.
Beginnen
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Conclusie
Qwen3-Max-Preview plaatst Alibaba in een prominente positie onder organisaties die modellen op biljoenen schaal aan klanten leveren. De combinatie van extreme contextlengte en een OpenAI-compatibele API verlaagt de integratiedrempel voor bedrijven die behoefte hebben aan redenering in lange documenten, code-automatisering of agent-orkestratie. Kosten en previewstabiliteit zijn de belangrijkste overwegingen bij de implementatie: organisaties zullen willen experimenteren met caching, streaming en batch-calls om zowel latentie als prijs te beheersen.