

De Claude-serie van Anthropic is een hoeksteen geworden in het snel evoluerende landschap van grote taalmodellen, met name voor bedrijven en ontwikkelaars die op zoek zijn naar geavanceerde AI-mogelijkheden. Met de release van Claude Opus 4.1 op 5 augustus 2025 biedt Anthropic een incrementele maar impactvolle upgrade ten opzichte van zijn voorganger, Claude Opus 4 (uitgebracht op 22 mei 2025). Dit artikel onderzoekt de belangrijkste verschillen tussen Opus 4.1 en Opus 4.0 op het gebied van prestaties, architectuur, veiligheid en praktische toepasbaarheid, gebaseerd op officiële aankondigingen, onafhankelijke benchmarks en feedback uit de branche.
Claude Opus 4.1 is nu beschikbaar via de API (model-ID claude-opus-4-1-20250805), Amazon Bedrock, Google Cloud's Vertex AI en betaalde Claude-interfaces. Als incrementele update behoudt het volledige achterwaartse compatibiliteit met Opus 4: dezelfde prijzen, eindpunten en alle bestaande integraties blijven ongewijzigd functioneren.
Wat is Claude Opus 4.0 en waarom is het belangrijk?
Claude Opus 4.0 markeerde een substantiële stap in Anthropics streven naar 'grensverleggende intelligentie', door robuuste redeneringen, uitgebreide contextverwerking en sterke programmeervaardigheden te combineren in één model. Het bereikte:
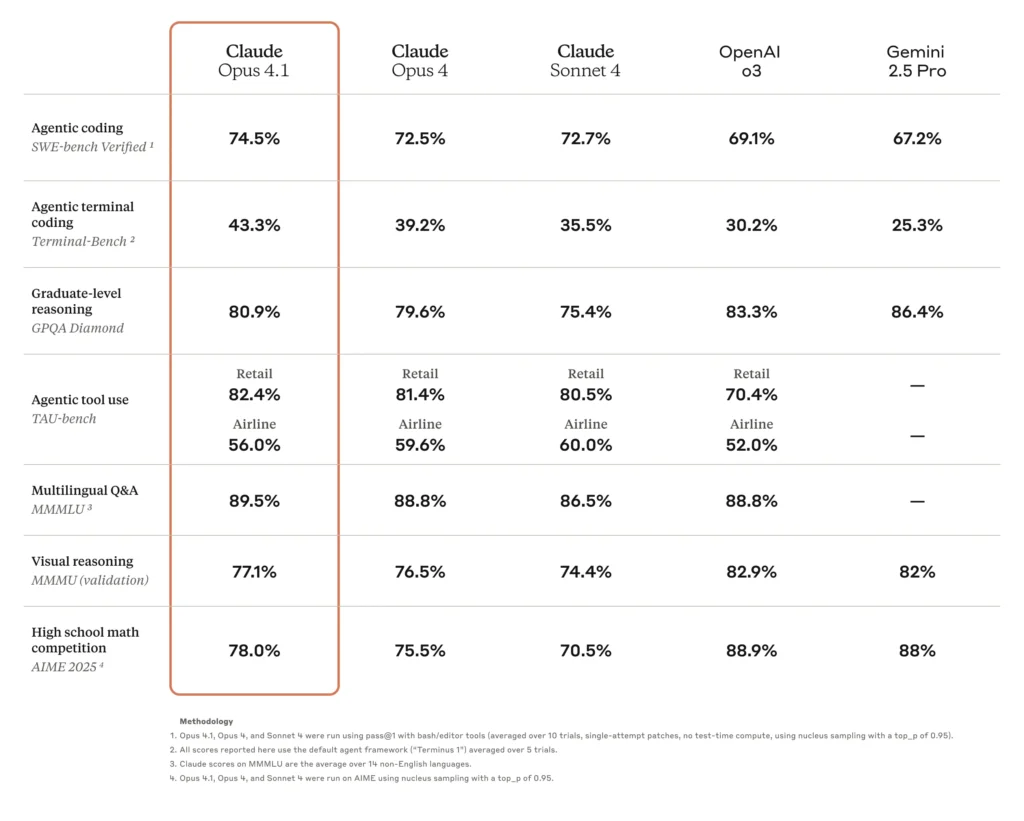
- Hoge coderingsnauwkeurigheid: Opus 4.0 scoorde 72.5% op SWE-bench Verified, een benchmark voor echte programmeeruitdagingen, wat aantoont dat het programma zeer toepasbaar is op softwareontwikkelingstaken.
- Geavanceerde agentcapaciteiten:Het model excelleerde in het uitvoeren van taken in meerdere stappen, autonoom, waardoor geavanceerde AI-agenten workflows konden beheren, van marketingorkestratie tot onderzoeksondersteuning.
- Creatief en analytisch vermogen:Opus 4.0 leverde naast codering ook geavanceerde prestaties op het gebied van creatief schrijven, data-analyse en complexe redeneringen. Daarmee is het een veelzijdige tool voor zowel zakelijke als technische domeinen.
De combinatie van breedte en diepte van Opus 4.0 legde de lat hoger voor AI voor bedrijven en zorgde voor een snelle acceptatie in de Claude Pro-, Max-, Team- en Enterprise-abonnementen. Ook werd Opus XNUMX geïntegreerd in Amazon Bedrock en Vertex AI van Google Cloud.
Wat is er nieuw in Claude Opus 4.1?
Benchmarkverbeteringen in codeertaken
Een van de belangrijkste verbeteringen in Opus 4.1 is de verbeterde coderingsnauwkeurigheid. Op SWE-bench Verified scoort Opus 4.1 74.5%, een stijging ten opzichte van de 4.0% van Opus 72.5. Deze winst van 2 punten, hoewel ogenschijnlijk bescheiden, staat gelijk aan aanzienlijke verminderingen van debugcycli en verbeterde precisie bij codesynthese en refactoring.
Op welke manieren zijn agenttaken betrouwbaarder?
Opus 4.1 biedt sterkere mogelijkheden voor redeneren over een lange horizon, waardoor AI-agenten complexe, meerstapsprocessen consistenter kunnen uitvoeren. Volgens AWS dient het model nu als een "ideale virtuele medewerker" voor taken die uitgebreide denkprocessen vereisen, zoals autonoom campagnebeheer en cross-functionele workfloworkestratie.
Precisie van multi-file refactoring
Een opvallende eigenschap van Opus 4.1 is de conservatieve aanpak van grootschalige codewijzigingen. Waar Opus 4.0 soms onnodige bewerkingen aanbracht in onderling verbonden bestanden, blinkt Opus 4.1 uit in het isoleren van de minimaal vereiste aanpassingen – het nauwkeurig aanwijzen van correcties zonder bijkomende wijzigingen.
Hoe presteren ze ten opzichte van de belangrijkste benchmarks?
Coderingsbenchmarks
| Model | SWE-bench Geverifieerd (%) | Multi-file refactoring score |
|---|---|---|
| Opus 4.0 | 72.5 | Baseline |
| Opus 4.1 | 74.5 | +1.2 σ winst |
Bron: Antropische systeemkaart en onafhankelijke benchmarks
Agenten zoeken en onderzoeken
Opus 4.1 toont een 15% Verbetering van de agentische evaluaties van TAU-bench, wat wijst op een beter contextbehoud en meer initiatief in onderzoekstaken. Gebruikers melden snellere convergentie van relevante informatie en coherentere samenvattingen van meerdere documenten.
Benchmarkvergelijkingen met "agentische zoek"-taken laten zien dat Opus 4.1 hogere scores behaalt op het gebied van planning, toolgebruik en dynamische probleemoplossing. De interne agentische onderzoeksevaluatie van Anthropic wijst op een verbetering van 5-7% in de nauwkeurigheid van meerstaps redeneren ten opzichte van Opus 4.0, wat een betrouwbaardere uitvoering van workflows mogelijk maakt, zoals geautomatiseerde data-analysepipelines en het genereren van onderzoeksrapporten. Deze verbeteringen zijn deels te danken aan de verbeterde traceerbaarheid van tussenliggende redeneringen, een functie die eindgebruikers beter inzicht geeft in de beslissingstrajecten van het model.
Bij welke specifieke coderingstaken is de grootste winst te behalen?
- Multi-file refactoring:Opus 4.1 biedt een verbeterde consistentie bij het doorlopen van onderling afhankelijke modules, waardoor fouten tussen bestanden bij interne tests met meer dan 15% zijn verminderd.
- Buglokalisatie en -reparatie:Het model identificeert betrouwbaarder de hoofdoorzaak van falende testcases, waardoor de gemiddelde oplossingstijd met 25% wordt verkort.
- Documentatie genereren: Verbeterde natuurlijke taalvaardigheid ondersteunt uitgebreidere en contextbewuste API-docstrings en inline-opmerkingen.
Hoe verwerkt Opus 4.1 taken die uit meerdere stappen bestaan?
- Verbeterde planningsheuristiekwaardoor planningsfouten in 10-staps taakketens met 8% werden verminderd.
- Verbeterde integratie van gereedschapsgebruikwaardoor API-aanroepen nauwkeuriger kunnen worden uitgevoerd met minder opmaakfouten.
- Tussentijdse redeneeropdrachtenwaardoor ontwikkelaars de interne redenering van het model kunnen verifiëren en aanpassen via aanpasbare 'controlepunten'.
Instructie-nalevingsmetrieken
Uit evaluaties met één beurt blijkt dat Opus 4.1 een onschadelijk responspercentage van 98.76% behaalde op verzoeken die inbreuk maakten op de privacy – een stijging ten opzichte van 97.27% in Opus 4.0 – wat wijst op een sterkere weigering van verboden content (). De percentages van overmatige weigeringen bij verzoeken die geen inbreuk maken op de privacy blijven relatief laag (0.08% versus 0.05%), waardoor het model waar nodig responsief blijft.
Welke verbeteringen op het gebied van veiligheid en uitlijning zijn er?
Verbeteringen in de evaluatie van één beurt
De verkorte veiligheidsaudits van Anthropic voor Opus 4.1 bevestigden consistente of verbeterde prestaties op het gebied van kindveiligheid, bias en alignment. Zo steeg het percentage onschadelijke reacties onder uitgebreide denkprocessen van 97.67% naar 99.06%.
Vooringenomenheid en robuustheid
Op de BBQ-biasbenchmark staat de score voor gedisambigueerde bias van Opus 4.1 op -0.51, tegenover -0.60 voor Opus 4.0. De nauwkeurigheid blijft boven de 90% voor gedisambigueerde zoekopdrachten en bijna perfect voor ambigue zoekopdrachten. Deze marginale verschuivingen duiden op een aanhoudende neutraliteit en hoge betrouwbaarheid in gevoelige contexten.
Wat is de basis voor de architectonische verbeteringen?
Modelafstemming en gegevensupdates
Het team van Anthropic implementeerde verfijnde fine-tuningprotocollen die zich richtten op:
- Uitgebreide codecorpora: Meer geannoteerde multi-bestandsopslagplaatsen integreren.
- Uitgebreide agentscenario's: Het samenstellen van langere taakketens tijdens de training om het redeneren over de lange termijn te verbeteren.
- Verbeterde menselijke feedbackloops: Het benutten van gericht versterkend leren op basis van menselijke feedback (RLHF) bij grensgevallen om hallucinaties te verminderen.
Deze aanpassingen leveren meetbare winst op zonder dat de Transformer-kernarchitectuur wordt gewijzigd. Zo is er sprake van directe compatibiliteit met bestaande Anthropic API's.
Infrastructuur en latentie
Hoewel de ruwe inferentielatentie vergelijkbaar blijft met die van Opus 4.0, heeft Anthropic zijn serverinfrastructuur geoptimaliseerd om de koude-starttijden te verkorten met 12%, waardoor de responsiviteit voor interactieve applicaties zoals Claude Chat en Copilot-integraties wordt verbeterd.
Wat zijn de gevolgen voor ontwikkelaars en ondernemingen?
Prijs en beschikbaarheid
Claude Opus 4.1 wordt aangeboden bij de zelfde prijs als Opus 4.0 op alle kanalen (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Er zijn geen codewijzigingen nodig om te upgraden: gebruikers selecteren simpelweg 'Opus 4.1' in de modelkiezer.
Uitbreiding van het gebruiksscenario
- Software engineering: Sneller debuggen, nauwkeurigere testgeneratie, verbeterde CI/CD-pijplijnintegratie.
- AI-agenten: Betrouwbaardere autonome workflows in marketing, financiën en onderzoek.
- Enterprise-intelligentie: Verbeterde samenvattingen, rapportgeneratie en diepgaande analyses voor datagestuurde besluitvorming.
Deze upgrades resulteren in lagere ontwikkelkosten en een hoger rendement op investeringen in AI-gestuurde initiatieven.
Wat is de volgende stap voor Claude Opus?
Anthropic geeft aan dat Opus 4.1 slechts één stap is in een bredere roadmap. Het team hint op "substantieel grotere verbeteringen" in aankomende releases, waarschijnlijk gericht op:
- Nog langere contextvensters (meer dan 200 tokens).
- Multimodale mogelijkheden voor geïntegreerd beeld-, audio- en codebegrip.
- Sterkere interpreteerbaarheid hulpmiddelen om beslissingsroutes te volgen tijdens agentische acties.
Bedrijven en ontwikkelaars moeten de kanalen van Anthropic in de gaten houden voor updates, aangezien elke incrementele upgrade de positie van Claude als een van de meest capabele en veilige AI-assistenten op de markt verstevigt.
Beginnen
KomeetAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders samenvoegt.Claude Opus 4.1 is inderdaad toegankelijk via CometAPI. CometAPI-lijsten anthropic/claude-opus-4.1 onder de ondersteunde modellen, zodat u verzoeken ernaartoe kunt leiden via de API van CometAPI. Ook zijn er specifieke modellen voor cursorcode beschikbaar.
Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de Claude Opus 4.1 voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt.
Basis-URL: https://api.cometapi.com/v1/chat/completions
Modelparameter:
"claude-opus-4-1-20250805"→ standaard Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 met uitgebreide redenering ingeschakeldcometapi-opus-4-1-20250805→CometAPI exclusief. Standaardversie speciaal ontworpen voor cursor integratiecometapi-opus-4-1-20250805-thinking→ Exclusief voor CometAPI. Uitgebreide redeneringsversie specifiek voor cursor integratie
SamengevatClaude Opus 4.1 bouwt voort op de sterke punten van Opus 4.0 door gerichte verbeteringen te bieden in coderingsnauwkeurigheid, agentische redenering en infrastructuurprestaties – zonder de kosten te verhogen of integratiepaden te wijzigen. Of u nu complexe codebases verfijnt, autonome agentworkflows orkestreert of hoogwaardige zakelijke inzichten genereert, Opus 4.1 biedt een aantrekkelijke upgrade die precisie en veelzijdigheid combineert. Nu het AI-landschap zich blijft versnellen, positioneert Anthropic's constante stroom aan verbeteringen Claude Opus als dé keuze voor organisaties die de nieuwste mogelijkheden op het gebied van taalmodellen willen benutten.