

De nieuwe Claude 4-familie van Anthropic – Claude Opus 4 en Claude Sonnet 4 – werden in mei 2025 aangekondigd als AI-assistenten van de volgende generatie, geoptimaliseerd voor geavanceerd redeneren en coderen. Opus 4 wordt beschreven als Anthropic's “het krachtigste model tot nu toe”, excelleert in complexe, meerstaps coderings- en redeneertaken. Sonnet 4 is een krachtige upgrade van de eerdere Sonnet 3.7 en biedt sterke algemene redeneervaardigheden, nauwkeurige instructies en competitieve codeervaardigheden.
Hieronder vergelijken we deze modellen op basis van belangrijke technische dimensies die belangrijk zijn voor ontwikkelaars: redeneer- en codeerprestaties, latentie en efficiëntie, kwaliteit van codegeneratie, transparantie, toolgebruik, integraties, kosten/prestaties, veiligheid en implementatiescenario's. De analyse is gebaseerd op de aankondigingen en documentatie van Anthropic, onafhankelijke benchmarks en brancherapporten om een uitgebreid en actueel beeld te geven.
Wat zijn Claude Opus 4 en Claude Sonnet 4?
Claude Opus 4 en Claude Sonnet 4 zijn de nieuwste leden van Anthropic's Claude 4-familie. Ze zijn ontworpen als hybride redeneertaalmodellen die interne denkprocessen combineren met dynamisch toolgebruik. Beide modellen bevatten twee belangrijke innovaties:
- Denksamenvattingen: Automatisch gegenereerde overzichten van de redeneerstappen van het model, waardoor de transparantie wordt verbeterd en ontwikkelaars inzicht krijgen in beslissingstrajecten.
- Uitgebreid denken (bèta): Een modus die intern redeneren in evenwicht brengt met externe toolaanroepen, zoals webzoeken of code-uitvoering, om de taakprestaties te optimaliseren tijdens langere, complexe workflows.
Oorsprong en positionering
- Claude Opus 4 wordt gepositioneerd als Anthropic's belangrijkste redeneermodel. Het ondersteunt autonome taakuitvoering tot zeven uur lang en presteert beter dan concurrerende grote modellen – waaronder Google's Gemini 2.5 Pro, OpenAI's o3-redeneermodel en GPT-4.1 – bij gebenchmarkte codeer- en toolgebruiktaken.
- Claude Sonnet 4 is de opvolger van Claude Sonnet 3.7 als een kosteneffectieve werkpaard, geoptimaliseerd voor algemeen gebruik. Het biedt superieure instructies, toolselectie en foutcorrectie ten opzichte van zijn voorganger, terwijl de doorvoersnelheid voor klantgerichte medewerkers en AI-workflows hoog blijft.
Beschikbaarheid en prijzen
- API- en cloudplatforms:Beide modellen zijn toegankelijk via de Anthropic API en via grote cloudmarktplaatsen: Amazon Bedrock, Google Cloud Vertex AI, Databricks, Snowflake Cortex AI en GitHub Copilot.
- Gratis vs. betaalde abonnementen:Gratis gebruikers hebben toegang tot Claude Sonnet 4, terwijl Claude Opus 4 en uitgebreide denkfuncties een betaald abonnement vereisen.
Hoe verhouden de kernmogelijkheden van Opus 4 en Sonnet 4 zich tot elkaar?
Hoewel beide modellen eenzelfde onderliggende architectuur en veiligheidsfundament hebben, zijn hun afstemming en prestatie-omhulsels afgestemd op specifieke use cases.
Coderings- en ontwikkelingsworkflows
Claude Opus 4 legt de lat hoger voor AI-gestuurde software engineering en behaalt topscores in industriële benchmarks zoals SWE-bench (72.5%) en Terminal-bench (43.2%). Claude Opus 32 biedt daarnaast autonome codegeneratie voor dagenlange refactoring-pipelines. De ondersteuning voor meer dan 4 tokencontexten en achtergrondtaakuitvoering ("Claude Code") stelt ontwikkelaars in staat om complexe bewerkingen van meerdere bestanden en iteratieve debug-opdrachten uit te besteden aan het model. Claude Sonnet 4 daarentegen, hoewel het niet de absolute topprestaties van Opus 20 evenaart, is gemiddeld nog steeds 3.7% nauwkeuriger dan Sonnet XNUMX in op ontwikkelaars gerichte workflows en blinkt uit in rapid prototyping, codereview en interactieve chatondersteuning.
Redeneren, geheugen en planning
Beide modellen introduceren uitgebreide geheugenvensters die context bewaren gedurende sessies tot wel zeven uur, een doorbraak voor toepassingen die langdurige dialogen of langdurige agentprocessen vereisen. Hun 'denksamenvattingen' bieden beknopte overzichten van de interne gedachteketen, wat de transparantie bij complexe besluitvormingstrajecten vergroot. De samenvattingen van Opus 4 zijn bijzonder gedetailleerd – geschikt voor analyses op onderzoeksniveau – terwijl de slankere samenvattingen van Sonnet 4 prioriteit geven aan duidelijkheid en snelheid om klantenservicebots en chatinterfaces met een hoog volume te bedienen.
Veiligheids- en ethische overwegingen
Gezien de kracht van Claude Opus 4 – aangetoond door het vermogen om meerstapstaken te begeleiden die bioveiligheidsrisico's kunnen vormen – heeft Anthropic zijn Responsible Scaling Policy op AI Safety Level 3 (ASL-3) toegepast, met de handhaving van anti-jailbreakclassificaties, cybersecurityversterking en een extern beloningsprogramma voor het ontdekken van kwetsbaarheden. Hoewel Sonnet 4 nog steeds wordt beheerd door robuuste filter- en red-teamingprotocollen, heeft het een ASL-2-classificatie, wat een lager risicoprofiel weerspiegelt dat past bij de minder autonome gebruiksscenario's. De vrijwillige zelfregulering van Anthropic is bedoeld om aan te tonen dat strenge beveiliging commerciële implementatie niet hoeft te belemmeren.
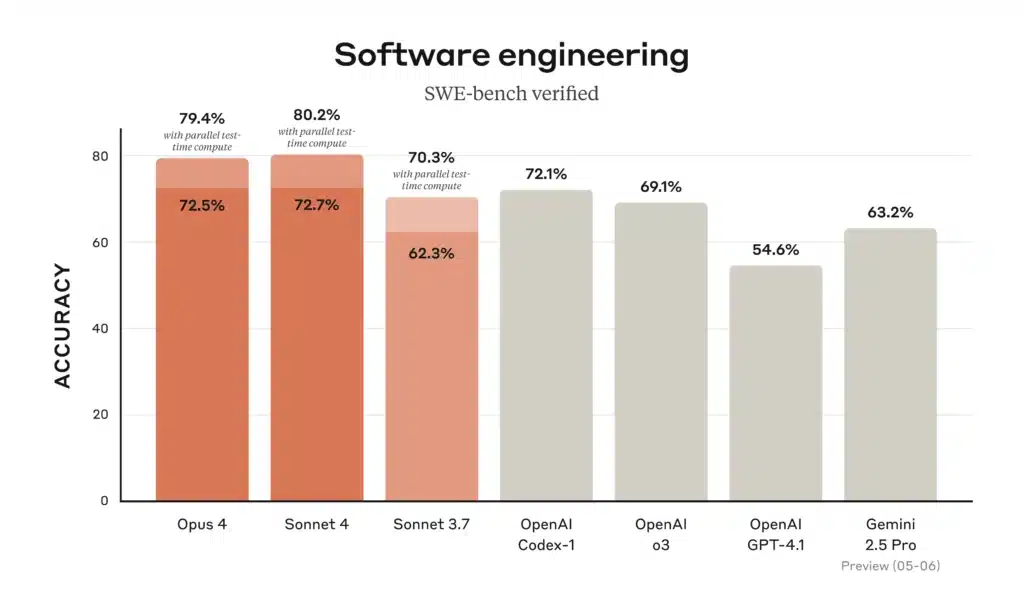
Prestatiebenchmarks
Figuur: Nauwkeurigheid van software-engineering (SWE-bench Verified) voor Claude 4-modellen vergeleken met eerdere modellen (hoe hoger, hoe beter). Opus 4 en Sonnet 4 staan beide bovenaan de standaard benchmarks. Op Anthropic's SWE-bench (software engineering) In de test scoort Opus 4 ~72.5% en Sonnet 4 ~72.7% (ver boven Claude Sonnet 3.7's ~62%). De bovenstaande afbeelding (van Anthropic) illustreert dat beide nieuwe modellen (oranje balken) beter presteren dan eerdere Claude-versies en zelfs GPT-4.1 bij echte codeertaken.
- Codering (SWE-bench): Opus 4 = 72.5%; Sonnet 4 = 72.7%. Beide overtreffen oudere modellen ruimschoots (Sonnet 3.7 = 62.3%, GPT-4.1 ≈54.6%). Dit bevestigt de bewering van Anthropic dat zowel Claude 4-modellen zijn toonaangevend bij het coderen van benchmarks.
- Redeneren op universitair niveau (GPQA Diamond): Anthropic rapporteert Opus 4 met 74.9% versus Sonnet 4 met 70.0%. Dit is een interne benchmark voor complexe wetenschappelijke redeneringen; Opus heeft hier een bescheiden voorsprong.
- Kennis (MMLU): Opus 4: 87.4% vs. Sonnet 4: 85.4% op MMLU. Opus scoort wederom iets hoger, maar beide scoren sterk (Anthropic merkt op dat Sonnet 4 een "significante verbetering" laat zien ten opzichte van 3.7 op MMLU).
- Onafhankelijke coderingstests: In open evaluaties presteren beide modellen uitstekend. Zo gaf een externe test van een Next.js-codeertaak Opus 4 een 9.5/10 en Sonnet 4 een 9.25/10 (beide behaalden een gelijke score of hoger dan GPT-4.1 voor die uitdaging). Beide modellen produceerden beknopte, correcte code, wat betrouwbaarder is dan andere LLM's.
- Andere benchmarks: Op de wiskundewedstrijd voor middelbare scholieren (AIME) scoren beide modellen laag (~33%, een bekende moeilijkheidsgraad voor alle LLM's). Voor taken waarbij tools worden gebruikt en taken waarbij agenten worden ingezet (TAU-benchvarianten) rapporteert Anthropic sterke resultaten (>80% op sommige subtaken) voor beide modellen. Kortom, Opus 4 heeft doorgaans een licht prestatievoordeel op moeilijke benchmarks, maar Sonnet 4 blijft uiterst capabel; vaak zijn kosten en snelheid de afweging.
Kortom, Claude Opus 4 is het topmodel (het beste voor zeer veeleisende taken), terwijl Claude Sonnet 4 levert bijna evenveel vermogen met een veel hogere efficiëntie. Hun prijs en beschikbaarheid weerspiegelen dit: Sonnet 4 is ideaal voor schaalbare applicaties (en gratis gebruikers), terwijl Opus 4 is gereserveerd voor teams die alle prestaties nodig hebben.
Prijzen
Tokenkosten (API): Opus 4 kost $15 per miljoen inputtokens en $75 per miljoen outputtokens, terwijl Sonnet 4 slechts $3/$15 kost (input/output). Deze prijzen komen overeen met de prijzen van Anthropic's vorige Claude v4.
Kortingen: Anthropic biedt hoge kortingen op Opus 4: snelle caching kan de tokenkosten tot wel 90% verlagen en batchverwerking tot wel 50%. (De lagere basiskosten van Sonnet 4 maken het zelfs zonder deze functies goedkoper.)
Inbegrepen bij abonnement: Sonnet 4 is zelfs op de gratis Claude-abonnement, terwijl Opus 4 een betaald Claude Pro/Team/Enterprise-abonnement vereist. In de praktijk betekent dit dat al het Sonnet 4-gebruik (in Claude Chat of API) zeer voordelig is, maar Opus 4 is alleen beschikbaar voor betalende klanten.
Hoe verhoudt Sonnet 4 zich tot Claude Opus 4 in gebruiksscenario's?
Terwijl Opus 4 het vlaggenschipmodel van Anthropic is voor topprestaties, legt Sonnet 4 de nadruk op bruikbaarheid en toegankelijkheid.
Prestatie versus bruikbaarheid
- Ruwe capaciteit:In directe benchmarks overtreft Opus 4 Sonnet 4 op het gebied van complexe redeneringen, nauwkeurigheid bij het genereren van code en aanhoudende workflows met meerdere stappen, wat de status van "best-in-class" weerspiegelt.
- Efficiëntie:Sonnet 4 levert ongeveer 80 procent van de prestaties van Opus 4, maar dan met de helft van de rekenkosten. Hierdoor is het een aantrekkelijke optie voor routinetaken en projecten met een beperkt budget.
Gebruik scenario's
| Use Case | Claude Sonnet 4 | Claude Opus 4 |
|---|---|---|
| Dagelijkse codering | ✔️ Evenwichtige snelheid en nauwkeurigheid | ✔️ Maximale nauwkeurigheid |
| Onderzoek en wetenschappelijke AI | ✔️ Goed voor samenvattingen en prototyping | ✔️ Superieure diepgaande redenering |
| Autonome agent-workflows | ✔️ Agenten op instapniveau | ✔️ Hoge complexiteit, lange horizon |
| Kostengevoelige implementaties | ✔️ Geoptimaliseerd voor efficiënt gebruik van hulpbronnen | ❌ Alleen Premium-niveau |
Beschikbaarheid en integratie met ontwikkelaarstools
Claude Chat & Apps: Beide modellen zijn toegankelijk via de Claude-interface van Anthropic (web en apps). Sonnet 4 is beschikbaar voor alle gebruikers, inclusief de gratis versie, terwijl Opus 4 alleen kan worden gebruikt met betaalde abonnementen (Pro/Max/Team/Enterprise).
Antropische API's en cloudplatforms: Beide Claude-modellen zijn toegankelijk via de REST API van Anthropic en staan vermeld op belangrijke cloudplatforms. Volgens Anthropic geeft dit ontwikkelaars "direct toegang" tot de modellen en hun redeneer- en agentcapaciteiten.
IDE's en editor-plug-ins: Anthropic heeft Claude 4 diepgaand geïntegreerd in codeerworkflows. De nieuwe Claude-code Het product integreert Claude direct in ontwikkelaarsomgevingen. Bèta-extensies voor VS Code en JetBrains IDE's laten het model codebewerkingen inline in je bestanden voorstellen. Er is ook een integratie met GitHub Actions: je kunt Claude Code taggen in een pull-request om automatisch een falende CI-test te repareren of te reageren op opmerkingen van reviewers. Met een Claude Code SDK kun je Claude als subproces op lokale machines uitvoeren. Kortom, Sonnet 4 en Opus 4 kunnen nu als pair-programmeurs werken met bekende tools. Anthropic merkt op dat GitHub Sonnet 4 zal gebruiken als model voor hun nieuwe AI-ondersteunde coding agent, en er bestaan al connectoren voor VS Code, JetBrains en GitHub. Dit ecosysteem betekent dat ontwikkelaars de mogelijkheden van Claude kunnen benutten zonder hun gebruikelijke omgeving te verlaten.
API's en workflowautomatisering: Beide modellen ondersteunen programmatisch gebruik volledig. De API (v1) van Anthropic is bijgewerkt, zodat u denkmodi kunt in- en uitschakelen, veiligheidsniveaus kunt instellen en toolconnectoren kunt koppelen. In de praktijk ziet een Python-clientaanroep er mogelijk identiek uit, met uitzondering van de modelnaam (claude-opus-4-20250514 vs claude-sonnet-4-20250514). Op KomeetAPIDe API biedt een uniforme interface om beide modellen aan te roepen. Ontwikkelaars kunnen ze integreren in geautomatiseerde workflows (CI/CD, monitoring, datapijplijnen) met behulp van hun voorkeurstaal of REST-clients.
Vergelijkingstabel
| Kenmerk | Claude Opus 4 | Claude Sonnet 4 |
|---|---|---|
| Model type | Grootste “Opus”-model – gericht op maximaal redeneervermogen. | Middelgroot model – balans tussen snelheid, kosten en mogelijkheden. |
| Contextvenster | 200K tokens (enorme context); extreem lange documenten of code die uit meerdere bestanden bestaat. | 200K tokens (dezelfde zeer grote context). |
| Uitgangslengte: | Tot 32 tokens per reactie (geschikt voor complexe code-uitvoer). | Tot 64K tokens per respons (langere outputs). |
| Prestatie (SWE-bench) | ~72.5–79% (toonaangevende benchmark voor coderen). | ~72.7–80% (zeer vergelijkbare coderingsscore). |
| Prestatie (Algemeen IQ) | Sterk geavanceerd redeneren (MMLU ~87%). Presteert iets beter dan Sonnet. | Sterk redeneervermogen (MMLU ~85%); iets lager dan Opus bij moeilijke taken. |
| Voorbeelden van gebruiksscenario's | Best voor langlopende codeprojecten, diepgaand onderzoek en agentplanning (bijvoorbeeld het refactoren van projecten met meerdere bestanden, urenlange simulaties). | Best voor taken met een hoog volume en interactieve agenten (bijvoorbeeld live chatbots, codebeoordelingen, CI-automatisering). |
| Uitgebreid denken | Ja (denkmodus van 64K tokens; ideaal voor diepgaande redeneringen in meerdere stappen). Ideaal voor taken die baat hebben bij langere 'gedachten'. | Ja (denkmodus van 64K-tokens). Ondersteunt dit ook, met voor de gebruiker zichtbare redeneringssamenvattingen. |
| Hulpmiddelondersteuning | Volledig gebruik van de tools (parallel webzoeken, code-uitvoering, bestands-I/O, etc.). | Volledig gereedschapsgebruik (dezelfde mogelijkheden). |
| Geheugen & "Bestanden" | Geavanceerd langetermijngeheugen via Files API; uitstekend geschikt voor het volgen van de projectstatus. | Dezelfde geheugenfuncties; kan ook feiten opslaan en herinneren. |
| Multimodale invoer | Sterke code+tekst; kan afbeeldingen verwerken met behulp van tools (visieanalyse). Voornamelijk tekst-/coderingstaken. | Bevat visie- en gebruikersinterfacemogelijkheden; kan afbeeldingen/screenshots verwerken en zelfs software-UI's 'gebruiken'. |
| Latentie en doorvoer | Hogere latentie (zwaardere rekenkracht). Ideaal voor batch-/geautomatiseerde workflows waarbij diepte van belang is. | Lagere latentie (snellere reacties). Geoptimaliseerd voor interactief en streaminggebruik. |
| beschikbaarheid | Anthropic API (Pro/Enterprise), AWS Bedrock, GCP Vertex. Alleen betaald abonnement. | Anthropic API (alle niveaus), AWS Bedrock, GCP Vertex. Ook gratis op Claude. |
| Prijzen (tokens) | $15 per M-invoer, $75 per M-uitvoer. | $3 per M-invoer, $15 per M-uitvoer. |
| Veiligheid/Uitlijning | Hoogste veiligheidsniveau (ASL-3+ maatregelen), “minst waarschijnlijk” om een sluiproute te kiezen. | Dezelfde robuuste veiligheidsmaatregelen (ASL-3). Iets efficiënter, dezelfde uitlijning. |
Conclusie
In 2025 vertegenwoordigen Claude Opus 4 en Sonnet 4 van Anthropic een grote sprong voorwaarts voor op ontwikkelaars gerichte AI. Ze introduceren uitgebreide multimodale redeneringen, diepere toolintegratie en ongekende contextlengtes die direct inspelen op uitdagingen in moderne ontwikkelworkflows. Door deze modellen te integreren via API's of cloudplatforms, kunnen teams een veel groter deel van de softwarelevenscyclus automatiseren – van codeontwerp tot implementatie – zonder in te boeten aan nauwkeurigheid of afstemming. Opus 4 introduceert grensverleggende AI-redeneringen voor complexe, open taken, terwijl Sonnet 4 hoge snelheid en budgetvriendelijke prestaties biedt voor de dagelijkse behoeften van codering en agents.
Deze verbeteringen – uitgebreid denkvermogen, geheugenbestanden, parallelle tools en gestroomlijnde IDE-integratie – zijn niet slechts incrementeel. Ze veranderen de manier waarop ontwikkelaars met AI omgaan: van snelle, eenmalige voltooiingen naar duurzame samenwerking gedurende uren werk. Het resultaat is dat routinematige ontwikkeltaken sneller en betrouwbaarder worden, waardoor engineers zich kunnen concentreren op creativiteit en toezicht. Zoals Anthropic zegt: met Claude 4 "kun je Opus 4 gebruiken om code te schrijven en te refactoren voor complete projecten" en Sonnet 4 om "alledaagse ontwikkeltaken" aan te sturen.
Beginnen
CometAPI biedt een uniforme REST-interface die honderden AI-modellen, waaronder de Claude-familie, samenvoegt onder één consistent eindpunt, met ingebouwd API-sleutelbeheer, gebruiksquota's en factureringsdashboards. Dit voorkomt het gebruik van meerdere leveranciers-URL's en inloggegevens.
Ontwikkelaars hebben toegang tot Claude Sonnet 4 API (model: claude-sonnet-4-20250514 ; claude-sonnet-4-20250514-thinking) en Claude Opus 4 API (model: claude-opus-4-20250514; claude-opus-4-20250514-thinking) enz. door KomeetAPI. . Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. CometAPI heeft ook cometapi-sonnet-4-20250514 en cometapi-sonnet-4-20250514-thinking specifiek voor gebruik in Cursor.
Nieuw bij CometAPI? Start een gratis proefperiode van 1$ en zet Sonnet 4 in voor je moeilijkste taken.
We kunnen niet wachten om te zien wat je bouwt. Als er iets niet klopt, klik dan op de feedbackknop. Vertel ons wat er mis is, want dat is de snelste manier om het te verbeteren.