

Claude Sonnet 4.5 (vaak kortgesloten tot Claudia 4.5) is de frontierrelease van Anthropic van 29 september 2025, gericht op agentisch werk, codering en "computergebruik" (het automatiseren van taken met meerdere stappen in verschillende tools). Claude 4.5 biedt grote sprongen in de duur van autonoom coderen, toolgebruik en afgestemd gedrag, terwijl de prijs per token gelijk blijft aan die van de vorige Sonnet-release. Voor teams die agentische workflows, productiviteitsstacks voor ontwikkelaars en gereguleerde bedrijfsapplicaties bouwen, is Claude 4.5 een aantrekkelijke en kosteneffectieve optie.
Wat Claude Sonnet 4.5 is
Claude Sonnet 4.5 is de volgende grote iteratie van het Claude-model van Anthropic (met de naam "Sonnet 4.5"), ontworpen om langere, complexere taken met meerdere stappen uit te voeren, softwaretools namens gebruikers te bedienen en productiekwaliteit codering en redenering uit te voeren voor zakelijke klanten. De release legt de nadruk op agentische mogelijkheden (modellen die autonoom kunnen handelen over meerdere stappen en tools), nauwere afstemming/veiligheid en rijkere in-app functionaliteit zoals code-uitvoering en bestandscreatie (spreadsheets, dia's, documenten).
Belangrijkste doorbraken en kenmerken
1. Duurzame, langdurige agentcapaciteit
Antropische rapporten Claude Sonnet 4.5 kan een gerichte, meerstapsbewerking uitvoeren voor meer dan 30 uur op complexe taken – een stapsgewijze verandering voor workflows die een AI vereisen om vele subtaken te orkestreren en veranderende contexten over lange tijdsperioden te verwerken. Dit staat centraal in de 'agent'-usecases van Antropische doelen.
2. State-of-the-art codering en computergebruikprestaties
Claude 4.5 behaalde topresultaten op SWE-Bench Verified (een industriële coderingsbenchmark) en laat grote winst zien in het vermogen van het model om daadwerkelijk gebruik een computer (toolaanroepen uitvoeren, terminal-/IDE-workflows beheren, apps bouwen). Antropische en onafhankelijke pers beschrijven het als het toonaangevende model voor codeertaken en "het beste ter wereld" op verschillende software engineering-niveaus. Dit omvat verbeteringen in autonome codegeneratie, debuggen en aanhoudende code-uitvoeringssessies.
3. Verbeterde toolorkestratie, contextbeheer en geheugen
Ter ondersteuning van lange agentruns introduceert Claude Sonnet 4.5 betere tools voor contextbeheer (automatische "contextbewerking" om verouderde tooluitvoer te wissen) plus een bestandsgebaseerde geheugentool waarmee het model kan worden bewaard en de status over sessies heen kan worden opgehaald. Deze systeemfuncties verminderen contextophoping en helpen agents om "gefocust" te blijven tijdens lange workflows.
4. Betere systeem-/besturingssysteeminteractie
In interne tests, beschreven door Anthropic en gerapporteerd door media, laat de nieuwe Claude Sonnet 4.5-variant aanzienlijke winst zien in benchmarks voor systeemgebruik (Anthropic rapporteerde bijvoorbeeld een sprong in een OS-benchmarkingtaak van ~40% naar ~60% vaardigheid), wat betekent dat het model meetbaar beter is in de interactie met en besturing van andere software. Dat is waardevol wanneer u wilt dat het model tools (bestanden bewerken, builds uitvoeren, API's aanroepen) betrouwbaar bedient.
5. Ontwikkelaarstools en integraties
Anthropic levert naast Claude Sonnet 4.5 ook tools voor ontwikkelaars: een Claude Agent SDK, native VS Code-integratie, terminal-/IDE-workflows en productintegraties zoals uitrol naar GitHub Copilot (Copilot Pro/Enterprise previews). Deze integraties verkorten de weg van prototype naar productie voor engineeringteams.
6. Verbeteringen in uitlijning en veiligheid
Anthropic noemt Claude Sonnet 4.5 “het meest uitgelijnde grensmodel” dat het heeft uitgebracht; het wordt ingezet onder AI-veiligheidsniveau 3 (ASL-3) bescherming en omvat verbeterde classificaties en verdedigingen (bijvoorbeeld tegen snelle injectie), met een afname van problematisch gedrag zoals gerapporteerd door Anthropic.
Prestatiebenchmarks: wat de cijfers betekenen
De aankondiging van Anthropic bevat verschillende belangrijke cijfers (SWE-benchmark, OSWorld, interne terminal/agent benchmarks). Belangrijkste gepubliceerde cijfers van Anthropic:
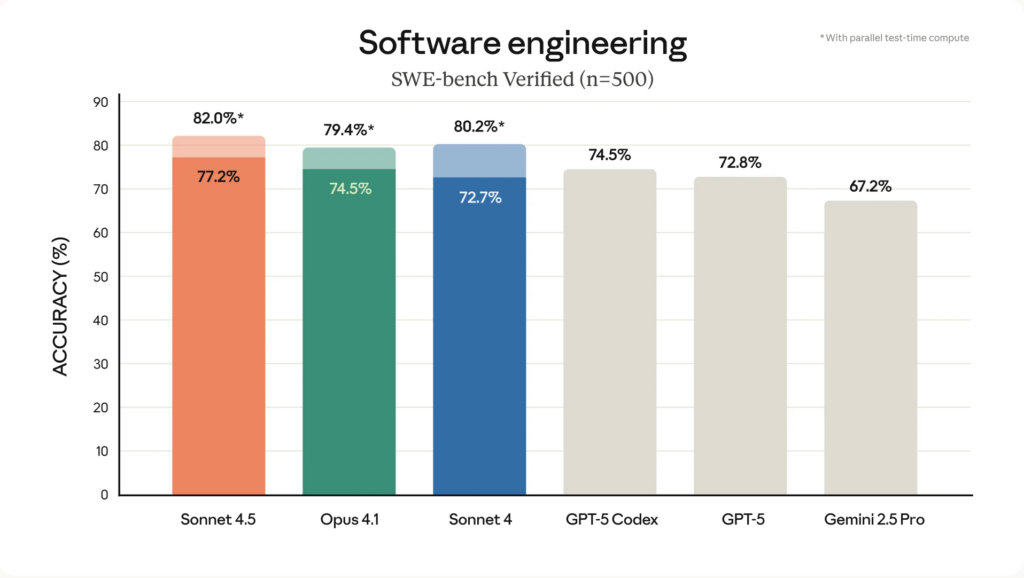
- SWE-bench Geverifieerd: 77.2% (200K denkbudget, steiger + gereedschap); 78.2% in 1M-context; 82.0% gerapporteerd voor een “high-compute” kandidaatselectieregime.
- OSWorld (computertaken): 61.4% voor Sonnet 4.5 vs 42.2% voor Sonnet 4 (vier maanden eerder).
- Autonomieduur (interne testen): >30 uur continue autonome codering/agent-werking (vorige generatie ~7 uur).
- Benchmark voor besturingssysteem/tool: Anthropic meldt een sprong van ~60% ten opzichte van ~40% voor de voorganger in een OS-interactiebenchmark. Dit toont een verbeterde betrouwbaarheid aan wanneer het model software aanstuurt.
Prijzen (ontwikkelaar / API)
Antropische lijsten de Sonnet 4.5 ontwikkelaarsprijzen in overeenstemming met Sonnet 4: $ 3 per miljoen inputtokens en $15 per miljoen output-tokens (met standaardbesparingen beschikbaar via prompt caching en batching). Sonnet 4.5 is beschikbaar via de Claude API en de Claude-apps. Enterprise- en volumekortingen/productniveaus (Pro/Max/Team/Enterprise) zijn beschikbaar via de commerciële kanalen van Anthropic.
Waarom kiezen voor Claude Sonnet 4.5? Gebruiksscenario's waar het uitblinkt
Agentische automatisering en orkestratie
Als u modellen nodig hebt die lange workflows (meerdere uren/dagen) uitvoeren, geheugen beheren over meerdere stappen, subagenten coördineren of tools (terminals, web-UI's, spreadsheets) autonoom bedienen, dan is de focus van Sonnet 4.5 op duurzame coherentie en een speciale Agent SDK een groot voordeel.
Productiecodering en productiviteit van ontwikkelaars
Uit de benchmarks en partnerrapporten van Anthropic (bijvoorbeeld integraties met GitHub Copilot) blijkt dat Sonnet 4.5 codebasebewerkingen in meerdere bestanden, tests en lange foutopsporingssessies aankan. Dit is handig wanneer ontwikkelaars een assistent willen die kan schrijven, testen en itereren met minder menselijke tussenkomst.
Gereguleerde en bedrijfscontexten
Sterkere afstemming en ASL-3-implementatie maken Sonnet 4.5 aantrekkelijk voor teams in de financiële, juridische, beveiligings- en zorgsector die strengere eisen en gedocumenteerde veiligheidspraktijken nodig hebben. Anthropic positioneert het model expliciet voor zakelijke klanten.
Kostengevoelig productiegebruik
Omdat Sonnet 4.5 de Sonnet-prijzen aanhoudt (~$3/$15 per miljoen tokens), lijkt de kosten-/prestatie-afweging voor zware agentische workloads gunstig vergeleken met sommige duurdere frontiermodellen, vooral als je rekening houdt met prompt caching en andere platformoptimalisaties
Overweeg alternatieven als:
- Uw prioriteit ligt bij de laagst mogelijke latentie of de goedkoopste inferentie per token voor eenvoudige vraag- en antwoordsessies; lichtere modellen of gedistilleerde modellen van andere leveranciers kunnen goedkoper/sneller zijn voor eenvoudige workloads. (Prijzen en kostenstructuur variëren; vergelijk de prijzen per token-uitvoer en cachingstrategieën.)
Wanneer u voor Claude Sonnet 4.5 kiest — praktische richtlijnen
Kies Claude Sonnet 4.5 als:
- Je hebt een LLM nodig om gereedschappen bedienen betrouwbaar over lange sequenties (agent-orkestratie, automatiseringspijplijnen, autonome assistenten).
- Uw primaire werklast is software engineering op schaal (geautomatiseerde codering, lange debugsessies, continue integratietaken) — Sonnet 4.5 presteert naar verluidt uitstekend in SWE-Bench en gerelateerde codebenchmarks.
- U werkt in gereguleerde of risicovolle domeinen (juridisch, financieel, beveiliging) en hebt een model nodig dat is afgestemd op voorspelbaarder, controleerbaarder gedrag en veiligere uitkomsten. Anthropic legt de nadruk op betrouwbaarheid en veiligheid binnen ondernemingen.
Overweeg alternatieven als:
Uw prioriteit ligt bij de laagst mogelijke latentie of de goedkoopste inferentie per token voor eenvoudige vraag- en antwoordsessies; lichtere modellen of gedistilleerde modellen van andere leveranciers kunnen goedkoper/sneller zijn voor eenvoudige workloads. (Prijzen en kostenstructuur variëren; vergelijk de prijzen per token-uitvoer en cachingstrategieën.)
Hoe krijg ik toegang tot Claude Sonnet 4.5?
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Ontwikkelaars hebben toegang tot Claude Sonnet 4.5 en Claude Sonnet 4 via CometAPI, de nieuwste modelversie wordt altijd bijgewerkt met de officiële website. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
Klaar om te gaan?→ Meld u vandaag nog aan voor CometAPI !
Conclusie
Claude Sonnet 4.5 is een doelgerichte evolutie: het is niet alleen ‘een beetje beter in chatten’. Anthropic heeft het ontworpen als een betrouwbare agentbouwer — een die langdurig aan de slag kan, tools en code kan orkestreren en domeinintensieve workflows (juridisch, financieel, cybersecurity en engineering) aankan. Als uw productie-usecases robuuste toolorkestratie, uitgebreide contextstabiliteit en topprestaties in coderen vereisen — en u voorspelbare prijzen per token wilt behouden — verdient Claude 4.5 een formele technische test in uw omgeving.