

De afgelopen maanden is er een snelle toename geweest in agentische codering: specialistische modellen die niet alleen eenmalige vragen beantwoorden, maar ook complete repositories plannen, bewerken, testen en itereren. Twee van de meest prominente deelnemers zijn Componist, een speciaal ontwikkeld codeermodel met lage latentie dat door Cursor werd geïntroduceerd met de release van Cursor 2.0, en GPT-5-Codex, OpenAI's agent-geoptimaliseerde variant van GPT-5, geoptimaliseerd voor continue codeerworkflows. Samen illustreren ze de nieuwe breuklijnen in ontwikkelaarstools: snelheid versus diepgang, bewustzijn van de lokale werkruimte versus generalistische redenering, en het gemak van 'vibe-coding' versus technische nauwkeurigheid.
In één oogopslag: directe verschillen
- Ontwerpdoel: GPT-5-Codex — diepgaande, agentische redenering en robuustheid voor lange, complexe sessies; Composer — vlotte, werkruimtebewuste iteratie, geoptimaliseerd voor snelheid.
- Primair integratieoppervlak: GPT-5-Codex — Codex-product/Respons-API, IDE's, bedrijfsintegraties; Composer — Cursor-editor en Cursor's multi-agent UI.
- Latentie/iteratie: Composer legt de nadruk op beurten van minder dan 30 seconden en claimt grote snelheidsvoordelen; GPT-5-Codex geeft prioriteit aan grondigheid en autonome runs van meerdere uren waar nodig.
Ik heb de GPT-5-Codex API model geleverd door KomeetAPI (een externe API-aggregatieprovider, waarvan de API-prijzen over het algemeen lager liggen dan de officiële) vatte mijn ervaringen met het Composer-model van Cursor 2.0 samen en vergeleek de twee op verschillende vlakken van codegeneratiebeoordeling.
Wat zijn Composer en GPT-5-Codex
Wat is GPT-5-Codex en welke problemen wil het oplossen?
De GPT-5-Codex van OpenAI is een gespecialiseerde momentopname van GPT-5 die volgens OpenAI geoptimaliseerd is voor agentische coderingsscenario's: het uitvoeren van tests, het uitvoeren van codebewerkingen op repository-schaal en het autonoom itereren totdat de controles zijn geslaagd. De focus ligt hierbij op brede mogelijkheden voor diverse technische taken: diepgaande redenering voor complexe refactors, "agentische" bewerkingen met een langere horizon (waarbij het model minuten tot uren kan besteden aan redeneren en testen) en betere prestaties op gestandaardiseerde benchmarks die zijn ontworpen om echte technische problemen te weerspiegelen.
Wat is Composer en welke problemen wil het oplossen?
Composer is Cursors eerste native codeermodel, geïntroduceerd met Cursor 2.0. Cursor beschrijft Composer als een grensverleggend, agent-centrisch model, gebouwd voor lage latentie en snelle iteratie binnen ontwikkelworkflows: het plannen van multi-file diffs, het toepassen van semantische zoekopdrachten in de gehele repository en het voltooien van de meeste taken in minder dan 30 seconden. Het werd getraind met tooltoegang in de loop (zoeken, bewerken, testen) om efficiënt te zijn bij praktische technische taken en de wrijving van herhaalde prompt-response-cycli in dagelijkse codering te minimaliseren. Cursor positioneert Composer als een model dat geoptimaliseerd is voor de snelheid van ontwikkelaars en realtime feedbackloops.
Modelbereik en runtime-gedrag
- Componist: Geoptimaliseerd voor snelle, editor-gerichte interacties en consistentie tussen meerdere bestanden. Cursors integratie op platformniveau stelt Composer in staat om meer van de repository te zien en deel te nemen aan multi-agent orkestratie (bijvoorbeeld twee Composer-agents versus meerdere), wat volgens Cursor gemiste afhankelijkheden tussen bestanden vermindert.
- GPT-5-Codex: Geoptimaliseerd voor diepere redeneringen met variabele lengte. OpenAI promoot de mogelijkheid van het model om rekenkracht/tijd in te ruilen voor diepere redeneringen wanneer dat nodig is – naar verluidt variërend van seconden voor lichte taken tot uren voor uitgebreide autonome runs – wat grondigere refactoren en testgestuurd debuggen mogelijk maakt.
Korte versie: Composer = Cursor's in-IDE, werkruimte-bewust coderingsmodel; GPT-5-Codex = OpenAI's gespecialiseerde GPT-5-variant voor software engineering, beschikbaar via Responses/Codex.
Hoe verhouden Composer en GPT-5-Codex zich qua snelheid tot elkaar?
Wat beweerden de verkopers?
Cursor positioneert Composer als een "fast frontier" programmeur: gepubliceerde cijfers benadrukken de generatiesnelheid gemeten in tokens per seconde en claimen 2-4x snellere interactieve voltooiingstijden ten opzichte van "frontier"-modellen in Cursors interne infrastructuur. Onafhankelijke berichtgeving (pers en vroege testers) meldt dat Composer code produceert met een snelheid van ~200-250 tokens/sec in Cursors omgeving en in veel gevallen typische interactieve codeerbeurten in minder dan 30 seconden voltooit.
De GPT-5-Codex van OpenAI is niet gepositioneerd als een latentie-experiment; het geeft prioriteit aan robuustheid en dieper redeneren en kan — bij vergelijkbare workloads met veel redeneren — langzamer zijn bij gebruik bij grotere contextgroottes, zo blijkt uit communityrapporten en probleemthreads.
Hoe we snelheid hebben gemeten (methodologie)
Om een eerlijke snelheidsvergelijking te kunnen maken, moet u het taaktype (korte voltooiingen versus lange redeneringen), de omgeving (netwerklatentie, lokale versus cloudintegratie) controleren en beide meten tijd tot eerste bruikbare resultaat en end-to-end wandklok (inclusief eventuele testuitvoerings- of compilatiestappen). Belangrijkste punten:
- Gekozen taken — generatie van kleine fragmenten (implementatie van een API-eindpunt), middelgrote taak (refactoring van één bestand en update-importen), grote taak (implementatie van functionaliteit in drie bestanden, update-tests).
- Metriek — tijd tot eerste token, tijd tot eerste nuttige verschil (tijd totdat de kandidaatpatch wordt uitgezonden) en totale tijd inclusief testuitvoering en -verificatie.
- Herhalingen — elke taak wordt 10x uitgevoerd, mediaan gebruikt om netwerkruis te verminderen.
- Milieu — metingen uitgevoerd op een ontwikkelaarsmachine in Tokio (om de werkelijke latentie weer te geven) met een stabiele 100/10 Mbps-verbinding; resultaten kunnen per regio verschillen.
Hieronder staat een reproduceerbare snelheidstuig voor GPT-5-Codex (Responses API) en een beschrijving van hoe Composer kan worden gemeten (in Cursor).
Snelheidsharnas (Node.js) — GPT-5-Codex (Responses API):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
Hiermee wordt de end-to-end-aanvraaglatentie voor GPT-5-Codex gemeten met behulp van de openbare Responses API (OpenAI-documentatie beschrijft het gebruik van de Responses API en het gpt-5-codex-model).
Hoe de Composer-snelheid (cursor) te meten:
Composer draait binnen Cursor 2.0 (desktop/VS Code fork). Cursor biedt (op het moment van schrijven) geen algemene externe HTTP API voor Composer die overeenkomt met de Responses API van OpenAI; de kracht van Composer is in-IDE, stateful workspace-integratieMeet Composer daarom zoals een menselijke ontwikkelaar dat zou doen:
- Open hetzelfde project in Cursor 2.0.
- Gebruik Composer om dezelfde prompt uit te voeren als een agenttaak (route maken, refactoren, wijzigen van meerdere bestanden).
- Start een stopwatch wanneer u het Composer-plan indient; stop wanneer Composer het atomaire verschil genereert en de testsuite uitvoert (de interface van Cursor kan tests uitvoeren en een geconsolideerd verschil weergeven).
- Herhaal dit 10x en gebruik de mediaan.
Uit gepubliceerde materialen en praktijkbeoordelingen van Cursor blijkt dat Composer in de praktijk veelvoorkomende taken in minder dan ~30 seconden voltooit. Dit is een interactief latentiedoel en geen ruwe modelafleidingstijd.
Afhaal: Het ontwerpdoel van Composer is snelle, interactieve bewerkingen in een editor. Als je prioriteit ligt bij conversatiegerichte codeerlussen met lage latentie, is Composer daarvoor gebouwd. GPT-5-Codex is geoptimaliseerd voor correctheid en agentisch redeneren tijdens langere sessies; het kan wat meer latentie inruilen voor een diepgaandere planning. Leverancierscijfers ondersteunen deze positionering.
Hoe verhouden Composer en GPT-5-Codex zich qua nauwkeurigheid tot elkaar?
Wat nauwkeurigheid betekent bij het coderen van AI
Nauwkeurigheid is hier veelzijdig: functionele correctheid (wordt de code gecompileerd en doorstaat hij de tests), semantische correctheid (voldoet het gedrag aan de specificatie), en robuustheid (behandelt randgevallen en beveiligingsproblemen).
Leveranciers- en persnummers
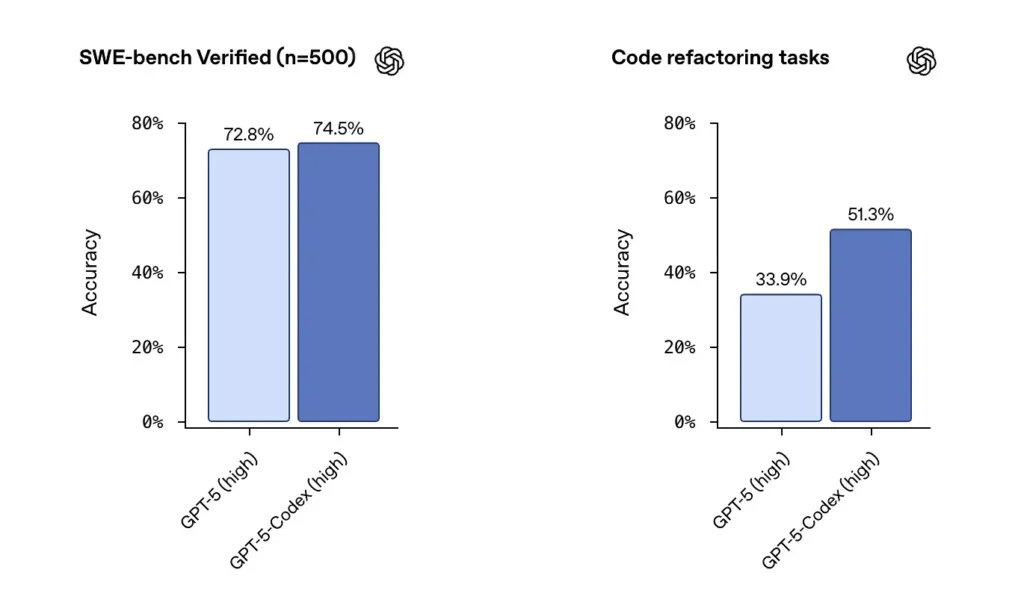
OpenAI rapporteert sterke prestaties van GPT-5-Codex op door SWE-bench geverifieerde datasets en benadrukte een 74.5% kans op succes op een echte coderingsbenchmark (gerapporteerd in de pers) en een opmerkelijke stijging in het succes van refactoring (51.3% versus 33.9 voor base GPT-5 op hun interne refactoringtest).
De release van Cursor geeft aan dat Composer vaak uitblinkt in contextgevoelige bewerkingen met meerdere bestanden, waarbij editorintegratie en zichtbaarheid in de repository van belang zijn. Na mijn tests bleek dat Composer minder gemiste afhankelijkheidsfouten produceerde tijdens refactoring van meerdere bestanden en hoger scoorde in blinde reviewtests voor sommige workloads met meerdere bestanden. De latentie en parallel-agentfuncties van Composer helpen me ook om de iteratiesnelheid te verbeteren.
Onafhankelijke nauwkeurigheidstesten (aanbevolen methode)
Een eerlijke test maakt gebruik van een combinatie van:
- Eenheidstests: voer dezelfde repository en testsuite aan beide modellen toe; genereer code, voer tests uit.
- Refactoring-tests: zorg voor een opzettelijk rommelige functie en vraag het model om te refactoren en tests toe te voegen.
- Veiligheidscontroles: voer statische analyses en SAST-hulpmiddelen uit op gegenereerde code (bijv. Bandit, ESLint, semgrep).
- Menselijke beoordeling: codebeoordelingsscores door ervaren engineers voor onderhoudbaarheid en best practices.
Voorbeeld: geautomatiseerde testomgeving (Python) — gegenereerde code en unittests uitvoeren
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
Gebruik dit patroon om automatisch te bevestigen of de modeluitvoer functioneel correct is (tests slaagt). Voer voor refactoringtaken de Harness uit tegen de originele repository plus het diff van het model en vergelijk de testpassingspercentages en dekkingswijzigingen.
Afhaal: In ruwe benchmarksuites rapporteert GPT-5-Codex uitstekende cijfers en sterke refactoring-vaardigheden. In praktische workflows voor reparatie en bewerking van meerdere bestanden kan Composer's werkruimtebewustzijn leiden tot een hogere praktische acceptatie en minder "mechanische" fouten (ontbrekende imports, onjuiste bestandsnamen). Voor maximale functionele correctheid in algoritmische taken met één bestand is GPT-5-Codex een sterke kandidaat; voor conventiegevoelige wijzigingen in meerdere bestanden binnen een IDE blinkt Composer vaak uit.
Composer vs GPT-5: hoe verhouden ze zich tot elkaar qua codekwaliteit?
Wat wordt beschouwd als kwaliteit?
Kwaliteit omvat leesbaarheid, naamgeving, documentatie, testdekking, gebruik van idiomatische patronen en beveiligingshygiëne. Het wordt zowel automatisch (linters, complexiteitsmetingen) als kwalitatief (menselijke beoordeling) gemeten.
Waargenomen verschillen
- GPT-5-Codex: sterk in het produceren van idiomatische patronen wanneer expliciet gevraagd; blinkt uit in algoritmische helderheid en kan uitgebreide testsuites produceren wanneer daarom wordt gevraagd. De Codex-tools van OpenAI bevatten geïntegreerde test-/rapportage- en uitvoeringslogboeken.
- Componist: geoptimaliseerd om automatisch de stijl en conventies van een repository te volgen; Composer kan bestaande projectpatronen volgen en updates voor meerdere bestanden coördineren (hernoemen/refactoring, propagatie, importeren van updates). Het biedt uitstekende on-demand onderhoudbaarheid voor grote projecten.
Voorbeelden van codekwaliteitscontroles die u kunt uitvoeren
- Linters — ESLint / pylint
- Ingewikkeldheid — radon / flake8-complexiteit
- Security — semgrep / Bandiet
- Test dekking — voer coverage.py of vitest/nyc uit voor JS
Automatiseer deze controles na het toepassen van de patch van het model om verbeteringen of regressies te kwantificeren. Voorbeeld van een opdrachtreeks (JS-repository):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
Menselijke beoordeling en beste praktijken
In de praktijk vereisen modellen instructies om best practices te volgen: vraag om docstrings, type-annotaties, dependency pinning of specifieke patronen (bijv. async/await). GPT-5-Codex is uitstekend wanneer expliciete richtlijnen worden gegeven; Composer profiteert van de impliciete repositorycontext. Gebruik een gecombineerde aanpak: geef het model expliciete instructies en laat Composer de projectstijl afdwingen als u zich binnen Cursor bevindt.
Aanbeveling: Voor multi-file engineering-werk binnen een IDE kunt u het beste Composer gebruiken. Voor externe pipelines, onderzoekstaken of toolchain-automatisering waarbij u een API kunt aanroepen en een grote context kunt leveren, is GPT-5-Codex een goede keuze.
Integraties en implementatieopties
Composer wordt meegeleverd met Cursor 2.0 en is geïntegreerd in de Cursor-editor en -gebruikersinterface. Cursors aanpak benadrukt één leverancierscontrolepaneel dat Composer naast andere modellen uitvoert, waardoor gebruikers meerdere modelinstanties op dezelfde prompt kunnen uitvoeren en de uitvoer in de editor kunnen vergelijken. ()
GPT-5-Codex wordt opgenomen in OpenAI's Codex-aanbod en ChatGPT-productfamilie, met beschikbaarheid via betaalde ChatGPT-abonnementen en API's die externe platforms zoals CometAPI een betere prijs-kwaliteitverhouding bieden. OpenAI integreert Codex ook in ontwikkelaarstools en workflows van cloudpartners (bijvoorbeeld integraties met Visual Studio Code/GitHub Copilot).
Waar kunnen Composer en GPT-5-Codex de industrie als volgende naartoe brengen?
Kortetermijneffecten
- Snellere iteratiecycli: Editor-embedded modellen zoals Composer verminderen de wrijving bij kleine correcties en het genereren van PR.
- Stijgende verwachtingen voor verificatie: Doordat Codex de nadruk legt op testen, logs en autonome mogelijkheden, worden leveranciers gedwongen om krachtigere, kant-en-klare verificatie te bieden voor door modellen geproduceerde code.
Middellange tot lange termijn
- Multi-modelorkestratie wordt normaal: De multi-agent GUI van Cursor is een vroege aanwijzing dat engineers binnenkort meerdere gespecialiseerde agenten parallel zullen willen laten draaien (linting, beveiliging, refactoring, prestatie-optimalisatie) en de beste uitkomsten zullen accepteren.
- Striktere CI/AI-feedbackloops: Naarmate modellen verbeteren, zullen CI-pijplijnen steeds vaker modelgestuurde testgeneratie en geautomatiseerde reparatievoorstellen bevatten. Menselijke beoordeling en gefaseerde uitrol blijven echter cruciaal.
Conclusie
Composer en GPT-5-Codex zijn geen identieke wapens in dezelfde wapenwedloop; het zijn complementaire tools die geoptimaliseerd zijn voor verschillende onderdelen van de softwarelevenscyclus. De waardepropositie van Composer is snelheid: snelle, op de werkruimte gebaseerde iteratie die ontwikkelaars in de flow houdt. De waarde van GPT-5-Codex is diepte: agentische persistentie, testgedreven correctheid en controleerbaarheid voor zware transformaties. Het pragmatische engineeringhandboek is om orkestreren beide: korte-lus Composer-achtige agents voor dagelijkse processen, en GPT-5-Codex-achtige agents voor gated, zeer betrouwbare bewerkingen. Vroege benchmarks suggereren dat beide op korte termijn deel zullen uitmaken van de ontwikkelaarstoolkit in plaats van dat de een de ander vervangt.
Er is geen enkele objectieve winnaar voor alle dimensies. De modellen wisselen sterke punten uit:
- GPT-5-Codex: Sterker op basis van diepgaande correctheidsbenchmarks, grootschalige redeneringen en autonome workflows van meerdere uren. Het blinkt uit wanneer de complexiteit van een taak langdurig redeneren of uitgebreide verificatie vereist.
- Componist: Sterker in gebruiksscenario's die nauw aansluiten op de editor, contextconsistentie in meerdere bestanden en een hoge iteratiesnelheid binnen de Cursor-omgeving. Het kan beter zijn voor de dagelijkse productiviteit van ontwikkelaars waar directe, nauwkeurige, contextbewuste bewerkingen nodig zijn.
Zie ook Cursor 2.0 en Composer: hoe een heroverweging van meerdere agenten de AI-codering verraste
Beginnen
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Ontwikkelaars hebben toegang tot GPT-5-Codex APIvia CometAPI, de nieuwste modelversie wordt altijd bijgewerkt met de officiële website. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
Klaar om te gaan?→ Meld u vandaag nog aan voor CometAPI !
Als u meer tips, handleidingen en nieuws over AI wilt weten, volg ons dan op VK, X en Discord!